在 PySpark 中选择满足条件的列
在本文中,我们将使用 Pyspark 中的where()函数根据条件选择数据框中的列。
让我们用员工数据创建一个示例数据框。
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display dataframe
dataframe.show()Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# select ID where ID less than 3
dataframe.select('ID').where(dataframe.ID < 3).show()Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# select ID and name where ID =4
dataframe.select(['ID', 'NAME']).where(dataframe.ID == 4).show()Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# select all columns e where name = sridevi
dataframe.select(['ID', 'NAME', 'Company']).where(
dataframe.NAME == 'sridevi').show()输出:

where() 方法
此方法用于根据给定条件返回数据帧。它可以接受一个条件并返回数据帧
句法:
where(dataframe.column condition)- 这里的数据帧是输入数据帧
- 列是我们必须提出条件的列名
select() 方法
应用 where 子句后,我们将从数据框中选择数据
句法:
dataframe.select('column_name').where(dataframe.column condition)- 这里的数据帧是输入数据帧
- 列是我们必须提出条件的列名
示例1: Python程序根据条件返回ID
蟒蛇3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# select ID where ID less than 3
dataframe.select('ID').where(dataframe.ID < 3).show()
输出:
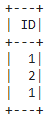
示例 2:选择 ID 和名称的Python程序,其中 ID =4。
蟒蛇3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# select ID and name where ID =4
dataframe.select(['ID', 'NAME']).where(dataframe.ID == 4).show()
输出:

示例 3:基于条件选择所有列的Python程序
蟒蛇3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of employee data
data = [[1, "sravan", "company 1"], [2, "ojaswi", "company 1"],
[3, "rohith", "company 2"], [4, "sridevi", "company 1"],
[1, "sravan", "company 1"], [4, "sridevi", "company 1"]]
# specify column names
columns = ['ID', 'NAME', 'Company']
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# select all columns e where name = sridevi
dataframe.select(['ID', 'NAME', 'Company']).where(
dataframe.NAME == 'sridevi').show()
输出:
