PySpark – 按类型选择列
在本文中,我们将讨论如何使用Python在 PySpark 中按类型选择列。
让我们创建一个数据框进行演示
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# import data field types
from pyspark.sql.types import StringType, DoubleType,
IntegerType, StructType, StructField, FloatType
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [(1, "sravan", 9.8, 4500.00), (2, "ojsawi",
9.2, 6789.00),
(3, "bobby", 8.9, 988.000)]
# specify column names with data types
columns = StructType([
StructField("ID", IntegerType(), True),
StructField("NAME", StringType(), True),
StructField("GPA", FloatType(), True),
StructField("FEE", DoubleType(), True),
])
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# display
dataframe.show()Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# import data field types
from pyspark.sql.types import (StringType,
DoubleType, IntegerType, StructType,
StructField, FloatType)
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [(1, "sravan", 9.8, 4500.00), (2, "ojsawi",
9.2, 6789.00),
(3, "bobby", 8.9, 988.000)]
# specify column names with data types
columns = StructType([
StructField("ID", IntegerType(), True),
StructField("NAME", StringType(), True),
StructField("GPA", FloatType(), True),
StructField("FEE", DoubleType(), True),
])
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# select columns that are integer type
print(dataframe[[item[0]
for item in dataframe.dtypes if item[
1].startswith('int')]].collect())
# select columns that are string type
print(dataframe[[item[0]
for item in dataframe.dtypes if item[
1].startswith('string')]].collect())
# select columns that are float type
print(dataframe[[item[0]
for item in dataframe.dtypes if item[
1].startswith('float')]].collect())
# select columns that are double type
print(dataframe[[item[0]
for item in dataframe.dtypes if item[
1].startswith('double')]].collect())Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# import data field types
from pyspark.sql.types import StringType, DoubleType,
IntegerType, StructType, StructField, FloatType
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [(1, "sravan", 9.8, 4500.00), (2, "ojsawi",
9.2, 6789.00),
(3, "bobby", 8.9, 988.000)]
# specify column names with data types
columns = StructType([
StructField("ID", IntegerType(), True),
StructField("NAME", StringType(), True),
StructField("GPA", FloatType(), True),
StructField("FEE", DoubleType(), True),
])
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# select columns that are integer type
print(dataframe[[f.name for f in dataframe.schema.fields if isinstance(
f.dataType, IntegerType)]].collect())
# select columns that are string type
print(dataframe[[f.name for f in dataframe.schema.fields if isinstance(
f.dataType, StringType)]].collect())
# select columns that are float type
print(dataframe[[f.name for f in dataframe.schema.fields if isinstance(
f.dataType, FloatType)]].collect())
# select columns that are double type
print(dataframe[[f.name for f in dataframe.schema.fields if isinstance(
f.dataType, DoubleType)]].collect())输出:
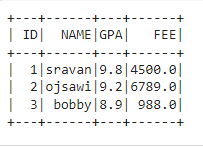
我们可以使用以下关键字按名称选择列:
- 整数:整数
- 字符串:字符串
- 浮动:浮动
- 双:双
方法一:使用 dtypes()
在这里,我们使用 dtypes 后跟 startswith() 方法来获取特定类型的列。
Syntax: dataframe[[item[0] for item in dataframe.dtypes if item[1].startswith(‘datatype’)]]
where,
- dataframe is the input dataframe
- datatype refers the keyword types
- item defines the values in the column
最后,我们使用 collect() 方法来显示列数据
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# import data field types
from pyspark.sql.types import (StringType,
DoubleType, IntegerType, StructType,
StructField, FloatType)
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [(1, "sravan", 9.8, 4500.00), (2, "ojsawi",
9.2, 6789.00),
(3, "bobby", 8.9, 988.000)]
# specify column names with data types
columns = StructType([
StructField("ID", IntegerType(), True),
StructField("NAME", StringType(), True),
StructField("GPA", FloatType(), True),
StructField("FEE", DoubleType(), True),
])
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# select columns that are integer type
print(dataframe[[item[0]
for item in dataframe.dtypes if item[
1].startswith('int')]].collect())
# select columns that are string type
print(dataframe[[item[0]
for item in dataframe.dtypes if item[
1].startswith('string')]].collect())
# select columns that are float type
print(dataframe[[item[0]
for item in dataframe.dtypes if item[
1].startswith('float')]].collect())
# select columns that are double type
print(dataframe[[item[0]
for item in dataframe.dtypes if item[
1].startswith('double')]].collect())
输出:
[Row(ID=1), Row(ID=2), Row(ID=3)]
[Row(NAME=’sravan’), Row(NAME=’ojsawi’), Row(NAME=’bobby’)]
[Row(GPA=9.800000190734863), Row(GPA=9.199999809265137), Row(GPA=8.899999618530273)]
[Row(FEE=4500.0), Row(FEE=6789.0), Row(FEE=988.0)]
方法 2:使用 schema.fields
这里我们使用 schema.fields 方法来获取列的类型。我们正在使用 pyspark.sql.types 模块中可用的方法检查特定类型。
让我们一一检查:
- 整数 - 整数类型
- 浮点型
- 双 - 双类型
- 字符串 - 字符串类型
我们正在使用 isinstance()运算符来检查这些数据类型。
Syntax: dataframe[[f.name for f in dataframe.schema.fields if isinstance(f.dataType, datatype)]]
where,
- dataframe is the input dataframe
- name is the values
- datatype refers to above types
Python3
# importing module
import pyspark
# importing sparksession from pyspark.sql module
from pyspark.sql import SparkSession
# import data field types
from pyspark.sql.types import StringType, DoubleType,
IntegerType, StructType, StructField, FloatType
# creating sparksession and giving an app name
spark = SparkSession.builder.appName('sparkdf').getOrCreate()
# list of student data
data = [(1, "sravan", 9.8, 4500.00), (2, "ojsawi",
9.2, 6789.00),
(3, "bobby", 8.9, 988.000)]
# specify column names with data types
columns = StructType([
StructField("ID", IntegerType(), True),
StructField("NAME", StringType(), True),
StructField("GPA", FloatType(), True),
StructField("FEE", DoubleType(), True),
])
# creating a dataframe from the lists of data
dataframe = spark.createDataFrame(data, columns)
# select columns that are integer type
print(dataframe[[f.name for f in dataframe.schema.fields if isinstance(
f.dataType, IntegerType)]].collect())
# select columns that are string type
print(dataframe[[f.name for f in dataframe.schema.fields if isinstance(
f.dataType, StringType)]].collect())
# select columns that are float type
print(dataframe[[f.name for f in dataframe.schema.fields if isinstance(
f.dataType, FloatType)]].collect())
# select columns that are double type
print(dataframe[[f.name for f in dataframe.schema.fields if isinstance(
f.dataType, DoubleType)]].collect())
输出:
[Row(ID=1), Row(ID=2), Row(ID=3)]
[Row(NAME=’sravan’), Row(NAME=’ojsawi’), Row(NAME=’bobby’)]
[Row(GPA=9.800000190734863), Row(GPA=9.199999809265137), Row(GPA=8.899999618530273)]
[Row(FEE=4500.0), Row(FEE=6789.0), Row(FEE=988.0)]