开放 AI GPT-3
Open AI GPT-3 是 OpenAI 的研究人员在题为“语言模型是少数学习者”的论文中提出的 GPT 模型的下一个模型系列。它在 1750 亿个参数上进行了训练,比之前的任何非稀疏模型都多 10 倍。它可以执行从机器翻译到代码生成等各种任务。
由于担心错误使用,该模型目前无法下载。 OpenAI 将为使用 GPT-3 能力提供高级 API。该 API 目前提供测试版。
- 零样本学习:模型试图在没有训练的情况下预测答案(更新梯度)。该模型提供了任务的输入和描述。模型需要根据输入预测输出。
- 一次性学习:该模型尝试仅使用一个任务示例来预测答案。该模型看到一个任务的单个示例,但未用于训练。这在计算机视觉中很常用,例如我们一个训练和一个测试示例通过神经网络并计算它们之间的距离的 Siamese 网络。
- 小样本学习:该模型尝试仅通过几个任务示例来预测答案。该模型提供了一些任务和任务描述的示例。

零样本、单样本和少样本学习
上述训练方法用于上下文学习,这意味着它提供了一个任务和示例,基于模型需要在测试数据集上执行它。 GPT-3中常用的这种训练方法
微调:在这个过程中,通过提供大量数据来训练模型。在这种方法中,我们将通过在每个 epoch(或每个示例)之后执行梯度更新来训练模型,类似于神经网络的训练。
架构: GPT-3 使用不同的模型变体进行训练,其参数数量从 1.25 亿到 1750 亿不等。以下是不同 GPT-3 模型的架构细节。
| Model Name | nparams | nlayers | dmodel | nheads | dheads | Batch Size | Learning Rate |
|---|---|---|---|---|---|---|---|
| GPT-3 small | 125 M | 12 | 768 | 12 | 64 | 0.5 M | 6 * 10-4 |
| GPT-3 Medium | 350 M | 24 | 1024 | 16 | 64 | 0.5 M | 3 * 10-4 |
| GPT-3 Large | 760 M | 24 | 1536 | 16 | 96 | 0.5 M | 2.5 * 10-4 |
| GPT-3 XL | 1.3 B | 24 | 2048 | 24 | 128 | 1 M | 2 * 10-4 |
| GPT-3 2.7 B | 2.7 B | 32 | 2560 | 32 | 80 | 1 M | 1.6 * 10-4 |
| GPT-3 6.7 B | 6.7 B | 32 | 4096 | 32 | 128 | 2 M | 1.2 * 10-4 |
| GPT-3 13 B | 13 B | 40 | 5140 | 40 | 128 | 2 M | 1 * 10-4 |
| GPT-3 175 B | 175 B | 96 | 12288 | 96 | 128 | 3.2 M | 0.6 * 10-4 |
- n params : 模型中的参数数量
- n层: 模型中的层数。
- d模型:每个瓶颈模型中的单元数。
- d head :注意头的尺寸。
- n head :注意力头的数量。
结果详情:
- 语言建模:对于语言建模任务,GPT-3 在 Penn Treebank 数据集上进行评估。语言模型使用 Zero-shot 设置来评估结果。最大的 GPT-3 模型将最先进的 (SOTA) 结果提高了 15 分。 GPT-3 还在其他 3 个语言建模数据集上进行了评估。
- LAMBADA 数据集: LAMBADA 数据集测试文本中长期依赖关系的建模。任务是预测需要阅读一段上下文的句子的最后一个单词。在 LAMBADA 数据集上,少样本 GPT-3 模型将准确度提高了 18%,即使是零样本 GPT-3 也比以前的 SOTA 提高了 8%。
- HellaSwag 数据集:HellaSwag 数据集涉及选择故事或指令集的最佳结局。这些示例是对抗性挖掘的,因此它们对语言模型变得困难,而对人类来说却很容易。在 HellaSwag 数据集上,少样本 GPT-3 获得了 79.3% 的准确率,并不比之前的最新技术 (85.6%) 好。
- StoryCloze: StoryCloze 2016 数据集涉及为五句长篇故事选择正确的结尾句子。少数射击GPT-3。 GPT-3 的小样本学习获得了 87.7% 的准确率,这更接近于最先进的准确率 (91%)。
- Closed Book Question Answering:此任务衡量GPT-3模型在不提供任何辅助数据来搜索答案的情况下回答问题的能力。在此任务中,模型使用广泛的事实知识来回答问题。 GPT-3 模型在三个数据集(NaturalQS、WebQS 和 TriviaQA)上进行评估,用于零样本、单样本和少样本学习。以下是 GPT-3 与此任务相比生成的结果。在 TriviaQA 数据集上,GPT-3 获得的结果(71.2%)比以前的最先进(,但在 NaturalQS 和 WebQS 数据集上,它仍然落后于检索增强生成(RAG)模型。
- 翻译:由于 GPT-3 的大部分训练数据是带有过滤的原始 Common crawl 数据集。因此,大部分训练数据是英语(93%),其他语言只有 7%。提供任务唯一描述的零样本设置的性能低于之前的无监督神经机器翻译模型。然而,作者注意到翻译任务的 BLEU 分数平均增加了 7 分,并且从单次设置到几次设置又增加了 4 次 BLUE。作者得出的另一点是,从英语翻译成其他语言时,它落后于最先进的 NMT 模型。然而,在翻译成英语时,它实现了最先进的结果(或更接近)。
- Winograd Style Task :在这个词中,模型的目标是确定当代词对建模没有歧义但人类无法理解时,该代词指代哪个词。最近的模型在 Winograd 任务上达到了人类级别的准确性。 GPT-3 还获得了更接近先前最先进技术的准确度。但是在更大的 Winogrande 数据集上,与之前的最新技术相比还有改进的空间。
- 常识推理:为了捕捉物理和科学推理,该模型在三个数据集上进行评估。这些是:
- 物理 QA:包含有关物理世界如何运作的常识性问题,旨在作为对世界的扎实理解的探索。 GPT-3 实现了 81.0% 的零样本准确度、80.5% 的单样本准确度和 82.8% 的少样本学习准确度。这比之前微调 RoBERTa 的最先进精度要好。
- ARC:它包含从 3 年级到 9 年级科学考试中收集的多项选择题。 GPT-3 在零次设置中达到 51.4% 的准确率,在一次设置中达到 53.2%,在少次设置中达到 51.5%。
- OpenBookQA:在 OpenBookQA 上,GPT-3 从零到少数镜头设置显着提高,但仍比整体最先进技术 (SOTA) 低 20 多分。 GPT-3 的少拍性能类似于排行榜上经过微调的 BERT Large 基线。
- 阅读理解:对于阅读理解,GPT-3 在 5 个不同的数据集上进行评估。 GPT-3 结果更接近会话问答数据集的最新技术。然而,在四个数据集(包括 DROP 数据集、QuCA、斯坦福问答(SQuAD)、提取阅读理解(RACE))上,GPT-3 远远落后于最先进的技术。
- 超级胶水。为了更好地总结 NLP 任务的结果并以更系统的方式与流行的模型(如 BERT 和 RoBERTa)进行比较,我们还在标准化的数据集集合 SuperGLUE 基准上评估 GPT-3。以下是 GPT-3 在这些基准数据集上的性能结果。
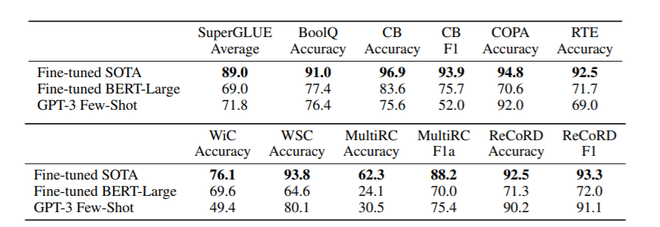
SuperGLUE 基准测试结果
- NLI :自然语言推理 (NLI) 涉及理解两个句子之间关系的能力。在实践中,这个任务通常被构造为一个二类或三类分类问题,其中模型对第二个句子是否在逻辑上紧随其后、首先矛盾或它是两个句子的可能组合进行分类。 SuperGLUE 包含一个 NLI 数据集 (RTE),上面提供了其结果。 GPT-3 在另一个名为 ANLI(对抗性自然语言推理)的 NLI 数据集上进行了测试。该数据集包含 3 个级别的对抗挖掘问题(R1、R2 和 R3)。最大的 GPT-3 模型在 R3 上的准确率约为 40%,远低于最先进的 (48.3%)。
- 合成和定性任务:为了测试 GPT-3 的能力,作者提供了实时观察模式所需的任务,而这些任务在训练中从未见过。首先,作者测试了 GPT-3 执行算术任务的能力。其次,作者在涉及重新排列或解读单词中的字母(例如字谜、反向单词等)的任务中评估了 GPT-3。第三,作者测试了 GPT-3 解决 SAT 类类比问题的能力。最后,GPT-3 在几个定性任务上进行评估,包括在句子中使用新词、纠正英语语法和新闻文章生成。
- 在算术任务上,GPT-3 的小样本学习最初在 2 位数加法和减法上给出了几乎 100% 的正确结果,但随着位数的增加,准确性也会受到影响。
- GPT-3 还展示了令人印象深刻的新闻文章生成结果。然后这些文章在人类身上进行了测试,以检测它是真实的还是生成的。 GPT-3 175B 模型生成的文章仅被 52% 的人正确检测到(相比之下,50% 的人是随机检测到的)。以下是大多数人出错的文章样本(准确率为 12%)。
Title: United Methodists Agree to Historic Split
Subtitle: Those who oppose gay marriage will form their own denomination
Article: After two days of intense debate, the United Methodist Church
has agreed to a historic split - one that is expected to end in the
creation of a new denomination, one that will be "theologically and
socially conservative," according to The Washington Post. The majority of
delegates attending the church's annual General Conference in May voted to
strengthen a ban on the ordination of LGBTQ clergy and to write new rules
that will "discipline" clergy who officiate at same-sex weddings. But
those who opposed these measures have a new plan: They say they will form a
separate denomination by 2020, calling their church the Christian Methodist
denomination.
The Post notes that the denomination, which claims 12.5 million members, was
in the early 20th century the "largest Protestant denomination in the U.S.,"
but that it has been shrinking in recent decades. The new split will be the
second in the church's history. The first occurred in 1968, when roughly
10 percent of the denomination left to form the Evangelical United Brethren
Church. The Post notes that the proposed split "comes at a critical time
for the church, which has been losing members for years," which has been
"pushed toward the brink of a schism over the role of LGBTQ people in the
church." Gay marriage is not the only issue that has divided the church. In
2016, the denomination was split over ordination of transgender clergy, with
the North Pacific regional conference voting to ban them from serving as
clergy, and the South Pacific regional conference voting to allow them.
使用的数据集:训练中使用了五个不同的数据集,其中最大的是 Common crawl 数据集,在过滤前包含近万亿个单词。但是这个数据集经过过滤和预处理,得到了近 4000 亿个令牌。另一个数据集包括 WebText 数据集的扩展版本和两个基于互联网的书籍语料库数据集和英文维基百科文本。Dataset Quantity(Num Tokens) Weight in Training MIx Common Crawl Dataset (filtered) 410 billion 60% WebText 2 19 billion 22% Books1 12 billion 8% Books2 55 billion 8% Wikipedia 3 billion 3%
培训详情:
GPT-3 的所有版本都(预)使用 Adam 作为优化器进行训练,β 1 = 0.9、β 2 = 0.95 和 epsilon = 10 -8 。训练数据的批量大小从 32k 令牌线性增加到最大超过 4-120 亿令牌。在训练过程中对数据进行采样而不进行替换,以最大限度地减少过拟合。
限制:
尽管在定性和定量结果上有了很大的提升,但 GPT-3 也有一些局限性:
- GTP-3 也面临与其他 NLP 模型相同的问题,尽管模型大小 GPT-3 样本有时会在文档级别在语义上重复自己,在足够长的段落中开始失去连贯性,自相矛盾,偶尔包含非结论性句子或段落
- 由于上下文学习不同于标准模型训练,它不涉及任何双向架构或其他训练目标,例如去噪。这可能是 GPT-3 在一些任务上相对较差的少拍性能的一个可能解释,例如 WIC(涉及比较两个句子中一个词的使用),ANLI(涉及比较两个句子,看看是否一个暗示另一个),以及几个阅读理解任务(例如 QuAC 和 RACE)。
- 尽管 GPT-3 朝着更接近人类(单次或零次)的测试时间样本效率迈进了一步,但它在预训练期间仍然需要比人类一生中看到的文本多得多的文本。
- GPT-3 也受到常见偏见的影响,例如对种族、性别、宗教等的偏见。
- 对性别的偏见:为了测试性别偏见,作者测试了不同职业的性别关联。下面是结果
- GPT-3 评估的 388 个职业中有 83% 更有可能与男性标识符相关联。这包括劳动密集型工作,即需要高水平教育和能力的工作。
- 大多数女性形容词与其外表有关,而男性形容词则多种多样。
- 对种族的偏见:在所有模型中,作者注意到亚洲人的情绪相对较好,而黑人的情绪相对较低。
- 对宗教的偏见:为了评估与宗教相关的偏见,作者通过给出带有宗教名称的提示,从 800 个长度 ≈50 的模型输出中获取生成的文本。作者发现,与其他词相比,有些词与特定宗教的关联度更高
- 对性别的偏见:为了测试性别偏见,作者测试了不同职业的性别关联。下面是结果
参考:
- GPT-3 论文