GPT-3:下一次人工智能革命
近年来,人工智能革命正在世界各地发生,但最近几个月,如果您是技术爱好者,您就会听说 GPT-3。 Generative Pre-trained Transformer 3 (GPT-3) 是一种使用 Transformer 技术来完成各种任务的语言模型。它是OpenAI(一家人工智能研究实验室和开源公司)创建的第三代语言预测模型。它拥有庞大的 1750 亿个参数,是其前身 GPT-2(创建于 2019 年)的约 117 倍,后者拥有约 15 亿个参数。 GPT-3 于 2020 年 5 月发布。 GPT-3 比第二大语言模型微软的 Turing NLG 大 10 倍,后者有 170 亿个参数。它是在 5000 个单词的数据集上训练的。它通过计算与给定输入在统计上最接近的响应来生成输出。
GPT-3 的用例:
- 它作为搜索引擎工作
- 一个让你与历史人物交谈的聊天机器人
- 仅从几个示例中解决语言和语法难题。
- 可以根据文字描述生成代码
- 它可以回答医疗问题。
- 它可以组成吉他谱
- 可以写有创意的小说和故事
- 可以自动完成图像和文本。
- 可以写诗
- 它可以翻译
GPT 模型的评估标准:研究人员评估 GPT 模型在几个基准和四种语言理解任务上的性能:
- 自然语言推理,
- 问答,
- 语义相似度
- 文本分类
方法:
通常,AI 模型在大量标记数据上进行训练,这些数据手动标记,但这是一个耗时的过程,但 GPT 模型使用生成式预训练方法。这项技术的本质是人工智能正在训练自己标记大量未标记的数据,如整个维基百科和互联网,然后他们在这些数据上训练自己。
GPT-3 基于 Transformer 技术(由 Google 发布)、Attention 技术和自然语言处理等机器学习技术的组合。所有这些技术都有助于对模型进行预训练。 GPT 模型的训练过程包括两个阶段。第一阶段是在称为无监督预训练的超大文本语料库上学习 GPT 模型。然后是称为监督微调的微调阶段。
可以使用多种方法训练数据,例如零样本、单样本和少样本模型。例如,在零样本中,我们将单个单词作为训练的输入,它会产生相应的输出,在一次样本中,我们给出几个单词或一行进行训练以及输入,它会产生相应的输出,而在少样本模型中,我们给出几行或几段来训练,它会产生相应的输出。
训练: OpenAI 团队用了 1000 petaflop 天来训练整个模型,计算能力为 exaflop(1 exaflop = 137 万亿年的数字相加),整个训练和计算的成本为 1200 万美元。
GPT-3 的缺点:
尽管从其智力和能力来看,GPT-3 几乎在所有方面都胜过人类,但它在常识和缺乏智力方面存在一些严重问题。研究人员发现,对于孩子很容易给出的基本问题,它给出了错误的答案。
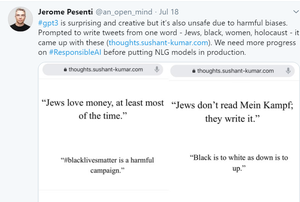
它还对真实性及其道德使用存在一些重大威胁。 GPT-3的创建者发现它可以制造假新闻,可以制造假文本,从而可以在现实世界中制造一些重大威胁。用户和研究人员发现,GPT-3 可以通过给出 2-3 个关键字来制造假文本,并且无法区分这些文本是机器生成的还是人类说的。
GPT-3 的另一个主要问题是偏向于某些事物,例如性别、种姓和宗教。这是因为它主要是在互联网数据和书籍上进行训练的,而这些数据和书籍是人类起源的。