Pandas GroupBy – 计算列中的出现次数
使用size()或count()方法 pandas.DataFrame.groupby() 将生成数据帧特定列中存在的数据出现次数的计数。但是,也可以使用 pandas.Series.value_counts() 和 pandas.Index.value_counts() 执行此操作。
方法
- 导入模块
- 创建或导入数据框
- 申请分组
- 使用两种方法中的任何一种
- 显示结果
方法一:使用pandas.groupyby().size ()
使用此方法的基本方法是在groupby()方法中将列名指定为参数,然后使用size()方法。下面是描述如何计算不同数据集列中出现次数的各种示例。
示例 1:
在此示例中,我们分别计算数据集中所有列的出现次数。
Python3
# import module
import pandas as pd
# assign data
data = pd.DataFrame({'Section': ['A', 'A', 'A', 'B', 'B',
'B', 'C', 'C', 'C'],
'Teacher': ['Kakeshi', 'Kakeshi', 'Iruka',
'Kakeshi', 'Kakeshi', 'Kakeshi',
'Iruka', 'Iruka', 'Guy']})
# display dataframe
print('Data:')
display(data)
print('Occurrence counts of particular columns:')
# count occurrences a particular column
occur = data.groupby(['Section']).size()
# display occurrences of a particular column
display(occur)
# count occurrences a particular column
occur = data.groupby(['Teacher']).size()
# display occurrences of a particular column
display(occur)Python3
# import module
import pandas as pd
# assign data
data = pd.DataFrame({'Section': ['A', 'A', 'A', 'B', 'B', 'B',
'C', 'C', 'C'],
'Teacher': ['Kakeshi', 'Kakeshi', 'Iruka',
'Kakeshi', 'Kakeshi', 'Kakeshi',
'Iruka', 'Iruka', 'Guy']})
# display dataframe
print('Data:')
display(data)
print('Occurrence counts of combined columns:')
# count occurrences of combined columns
occur = data.groupby(['Section', 'Teacher']).size()
# display occurrences of combined columns
display(occur)Python3
# import module
import pandas as pd
# assign data
data = pd.read_csv('diamonds.csv')
# display dataframe
print('Data:')
display(data.sample(10))
print('Occurrence counts of particular column:')
# count occurrences a particular column
occur = data.groupby(['cut']).size()
# display occurrences of a particular column
display(occur)
print('Occurrence counts of combined columns:')
# count occurrences of combined columns
occur = data.groupby(['clarity', 'color', 'cut']).size()
# display occurrences of combined columns
display(occur)Python3
# import module
import pandas as pd
# assign data
data = pd.DataFrame({'Section': ['A', 'A', 'A', 'B', 'B', 'B',
'C', 'C', 'C'],
'Teacher': ['Kakeshi', 'Kakeshi', 'Iruka',
'Kakeshi', 'Kakeshi', 'Kakeshi',
'Iruka', 'Iruka', 'Guy']})
# display dataframe
print('Data:')
display(data)
print('Occurrence counts of particular columns:')
# count occurrences a particular column
occur = data.groupby(['Section']).size()
# display occurrences of a particular column
display(occur)
# count occurrences a particular column
occur = data.groupby(['Teacher']).size()
# display occurrences of a particular column
display(occur)Python3
# import module
import pandas as pd
# assign data
data = pd.DataFrame({'Section': ['A', 'A', 'A', 'B', 'B', 'B',
'C', 'C', 'C'],
'Teacher': ['Kakeshi', 'Kakeshi', 'Iruka',
'Kakeshi', 'Kakeshi', 'Kakeshi',
'Iruka', 'Iruka', 'Guy']})
# display dataframe
print('Data:')
display(data)
print('Occurrence counts of combined columns:')
# count occurrences of combined columns
occur = data.groupby(['Section', 'Teacher']).size()
# display occurrences of combined columns
display(occur)Python3
# import module
import pandas as pd
# assign data
data = pd.read_csv('diamonds.csv')
# display dataframe
print('Data:')
display(data.sample(10))
print('Occurrence counts of particular column:')
# count occurrences a particular column
occur = data.groupby(['cut']).size()
# display occurrences of a particular column
display(occur)
print('Occurrence counts of combined columns:')
# count occurrences of combined columns
occur = data.groupby(['clarity', 'color', 'cut']).size()
# display occurrences of combined columns
display(occur)输出:

示例 2:
在下面的程序中,我们计算从前面程序中使用的相同数据集组合的所有列的出现次数。
蟒蛇3
# import module
import pandas as pd
# assign data
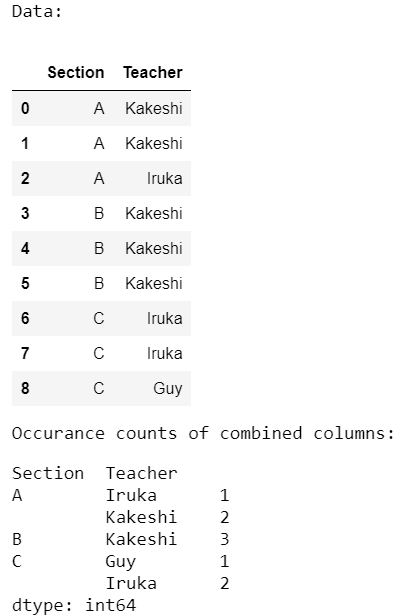
data = pd.DataFrame({'Section': ['A', 'A', 'A', 'B', 'B', 'B',
'C', 'C', 'C'],
'Teacher': ['Kakeshi', 'Kakeshi', 'Iruka',
'Kakeshi', 'Kakeshi', 'Kakeshi',
'Iruka', 'Iruka', 'Guy']})
# display dataframe
print('Data:')
display(data)
print('Occurrence counts of combined columns:')
# count occurrences of combined columns
occur = data.groupby(['Section', 'Teacher']).size()
# display occurrences of combined columns
display(occur)
输出:
示例 3:
在这里,我们将 CSV 文件中存在的分类列的计数出现次数和组合计数分开。
蟒蛇3
# import module
import pandas as pd
# assign data
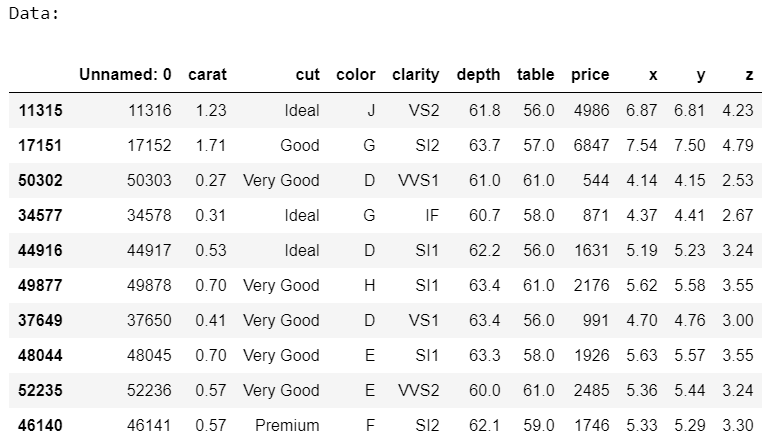
data = pd.read_csv('diamonds.csv')
# display dataframe
print('Data:')
display(data.sample(10))
print('Occurrence counts of particular column:')
# count occurrences a particular column
occur = data.groupby(['cut']).size()
# display occurrences of a particular column
display(occur)
print('Occurrence counts of combined columns:')
# count occurrences of combined columns
occur = data.groupby(['clarity', 'color', 'cut']).size()
# display occurrences of combined columns
display(occur)
输出:


方法二:使用pandas.groupyby().count ()
使用此方法的基本方法是在groupby()方法中将列名指定为参数,然后使用count()方法。下面是描述如何计算不同数据集列中出现次数的各种示例。
示例 1:
在此示例中,我们分别计算数据集中所有列的出现次数。
蟒蛇3
# import module
import pandas as pd
# assign data
data = pd.DataFrame({'Section': ['A', 'A', 'A', 'B', 'B', 'B',
'C', 'C', 'C'],
'Teacher': ['Kakeshi', 'Kakeshi', 'Iruka',
'Kakeshi', 'Kakeshi', 'Kakeshi',
'Iruka', 'Iruka', 'Guy']})
# display dataframe
print('Data:')
display(data)
print('Occurrence counts of particular columns:')
# count occurrences a particular column
occur = data.groupby(['Section']).size()
# display occurrences of a particular column
display(occur)
# count occurrences a particular column
occur = data.groupby(['Teacher']).size()
# display occurrences of a particular column
display(occur)
输出:

示例 2:
在下面的程序中,我们计算从前面程序中使用的相同数据集组合的所有列的出现次数。
蟒蛇3
# import module
import pandas as pd
# assign data
data = pd.DataFrame({'Section': ['A', 'A', 'A', 'B', 'B', 'B',
'C', 'C', 'C'],
'Teacher': ['Kakeshi', 'Kakeshi', 'Iruka',
'Kakeshi', 'Kakeshi', 'Kakeshi',
'Iruka', 'Iruka', 'Guy']})
# display dataframe
print('Data:')
display(data)
print('Occurrence counts of combined columns:')
# count occurrences of combined columns
occur = data.groupby(['Section', 'Teacher']).size()
# display occurrences of combined columns
display(occur)
输出:

示例 3:
在这里,我们将 CSV 文件中存在的分类列的计数出现次数和组合计数分开。
蟒蛇3
# import module
import pandas as pd
# assign data
data = pd.read_csv('diamonds.csv')
# display dataframe
print('Data:')
display(data.sample(10))
print('Occurrence counts of particular column:')
# count occurrences a particular column
occur = data.groupby(['cut']).size()
# display occurrences of a particular column
display(occur)
print('Occurrence counts of combined columns:')
# count occurrences of combined columns
occur = data.groupby(['clarity', 'color', 'cut']).size()
# display occurrences of combined columns
display(occur)
输出: