数据挖掘和推荐系统
数据挖掘利用统计中的各种方法和不同的算法,如分类模型、聚类和回归模型,以利用大量数据中存在的洞察力。它可以帮助我们根据已经发生的事件的历史来预测结果。例如,一个人根据他之前的交易每月花费的金额,客户经常购买的面包,黄油和果酱等经常一起购买。还可以分析市场趋势,例如雨季对雨伞的需求和夏季对冰淇淋的需求。这里的主要目标是分析数据集中存在的模式并根据所需的目标获得有用的信息。
今年农作物的产量可能是多少?当给出所有症状时,一个人患某种特定疾病的几率是多少?特定月份杂货的预期销售额是多少?从特定超市购买衣服的预期顾客数量是多少?预计来年的亏损/盈利百分比是多少?如果我们使用准确的模型来训练数据,识别数据集中存在的模式,那么所有这些问题都可以得到解答,更重要的是,我们需要有足够数量的数据来获得准确有效的结果。
特别是,数据处理吸引了一些想法,例如来自统计和搜索算法的抽样、估计和假设检验、建模技术以及来自计算、模式识别和机器学习的学习理论。
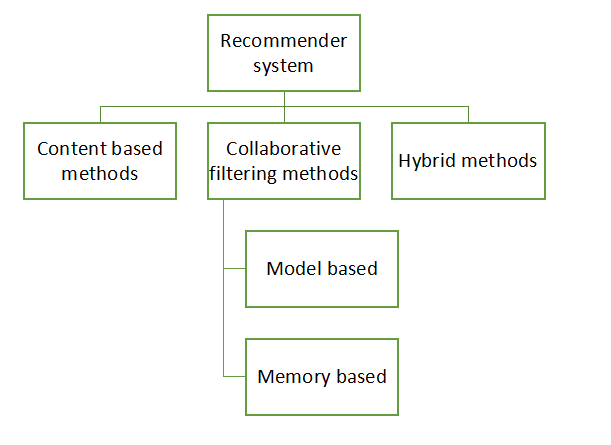
推荐系统:
推荐系统主要处理用户的好恶。其主要目标是根据用户之前的购买向有高机会喜欢或需要特定用户的用户推荐商品。这就像拥有一个个性化的团队,他们可以了解我们的好恶,并通过利用每天生成的存储库中的大量数据来帮助我们做出有关特定项目的决策,而不会以任何方式产生偏见。推荐系统的目的是为用户社区提供易于访问的高质量推荐。它的愿望是高效地拥有合理的个人权威。
接下来我应该看哪部电影/网络连续剧?我接下来应该读哪本书?我应该购买哪些与之前购买的物品相匹配的物品?我应该阅读哪些杂志?这会和我喜欢的类型相匹配吗?我应该去一个特定的地方吗?我会喜欢吗?所有这些问题都可以在推荐系统的帮助下得到解答。
在这里,我们要做的是找到必须从中进行推荐的用户或项目与数据集中存在的所有用户或项目的相似性。我们发现喜欢和不喜欢的模式具有最高的相似性。然后我们利用该模式来建议是否必须建议某个项目、地点、电影或书籍。
- 基于用户的推荐:这里我们计算皮尔逊的相似性度量,这是确定密切相关的用户所需要的,即他们的好恶遵循相同的模式。计算操作基于皮尔逊相似度公式。两个不同用户的评分减去平均值,然后乘以分子和分母,然后将评分平方并计算每个用户的总和。得到总和值后,将它们除以得到相似度度量。
- 基于项目的推荐:最初的目标是获得均值调整矩阵。平均调整矩阵用于预测使用该项目的新用户的评分,基于减少用户引起的错误,因为有些人在大多数时间倾向于给出非常高的评分,而有些人倾向于给出非常低的评分大多数时候。因此,为了减少这种不一致,我们从每个用户中减去平均值。下一步是计算项目之间的相似性度量。在这里,我们可以利用余弦相似度矩阵。计算操作基于余弦相似度公式。不同用户对两个项目的评分乘以分子和分母,评分平方并为每个项目计算总和。得到总和值后,将它们除以得到相似度度量。
在上述两种方法中,我们得到了相似性度量,基于该度量我们可以预测是否必须向特定用户建议该项目或该项目是否相关。
选择最简单技术的方法支持设备领域的具体情况,区分完全不同技术背后的令人信服的成功因素,或者检查许多支持相关最佳标准区域单元的技术,所有这些都是有效分析所需的。推荐系统历来是通过利用离线实验来评估的,这些实验计划估计推荐利用的预测误差,关联现有的交易数据集。