Python - 使用 beautifulSoup 查找文本,然后替换原始汤变量
Python提供了一个名为BeautifulSoap的库来轻松实现网页抓取。 BeautifulSoup对象由 Beautiful Soup 提供,它是Python的网络抓取框架。网络抓取是使用自动化工具从网站中提取数据的过程,以加快过程。 BeautifulSoup 对象将解析后的文档表示为一个整体。在本文中,我们将废弃一个简单的网站并替换已解析的“soup”变量中的内容。
出于本文的目的,让我们创建一个虚拟环境(venv),因为它可以帮助我们管理不同项目的单独包安装,并避免混淆依赖项和解释器!
更多关于如何创建虚拟环境的信息可以从这里阅读:创建虚拟环境
创建虚拟环境
导航到您的项目目录并运行此命令以在您的项目目录中创建一个名为“env”的虚拟环境。
python3 -m venv env通过键入激活“env”。
source env/bin/activate激活解释器后,我们可以在命令行中的:~$ 符号之前看到解释器的名称
安装所需模块
- BeautifulSoup:抓取网页的库。
pip install bs4- 请求:这使得发送 HTTP 请求的过程。
pip install requests循序渐进的方法
- 让我们首先导入库并将“GET”请求响应存储在变量中。
Python3
import bs4
from bs4 import BeautifulSoup
import requests
# sending a GET req.
response = requests.get("https://isitchristmas.today/")
print(response.status_code)Python3
# create object
soup = BeautifulSoup(r.text, "html.parser")
# find title
title = soup.find("title")
# find heading
heading = soup.find("h1")
print(title)Python3
# replace
title.string = "Is GFG day today?"
heading.string = "Welcome to GFG"Python3
import bs4
from bs4 import BeautifulSoup
import requests
# sending a GET requests
response = requests.get("https://isitchristmas.today/")
# a status 200 implies a sucessfull requests
#print(response.status_code)
soup = BeautifulSoup(response.text, "html.parser")
#print(soup)
title = soup.find("title")
heading = soup.find("h1")
# replacde
title.string = "Is GFG day today?"
heading.string = "Welcome to GFG"
# display replaced content
print(soup)
# The title and the heading tag contents
# get changed in the parsed soup obj.输出:
200状态 200 表示请求成功。
- 现在让我们将内容解析为一个 BeautifulSoup 对象,以提取网站的标题和标题标签(如本文)并将其替换为原始汤变量。 find()方法从汤对象中返回第一个匹配的案例。
蟒蛇3
# create object
soup = BeautifulSoup(r.text, "html.parser")
# find title
title = soup.find("title")
# find heading
heading = soup.find("h1")
print(title)
输出:
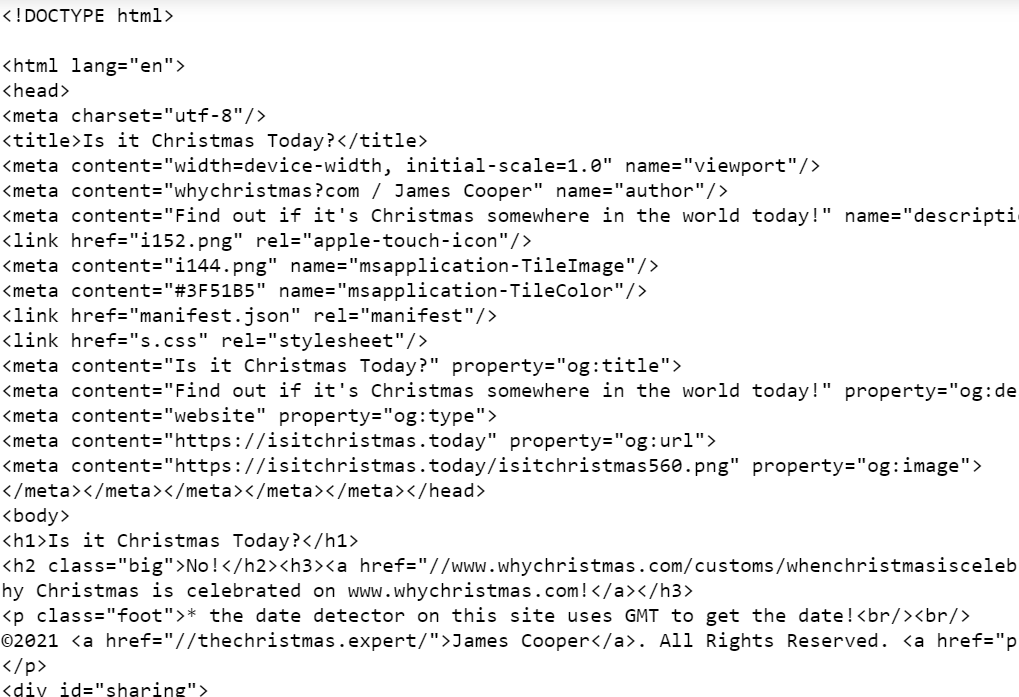
将解析后的汤 obj 的内容替换为“.字符串”方法。
蟒蛇3
# replace
title.string = "Is GFG day today?"
heading.string = "Welcome to GFG"
输出:
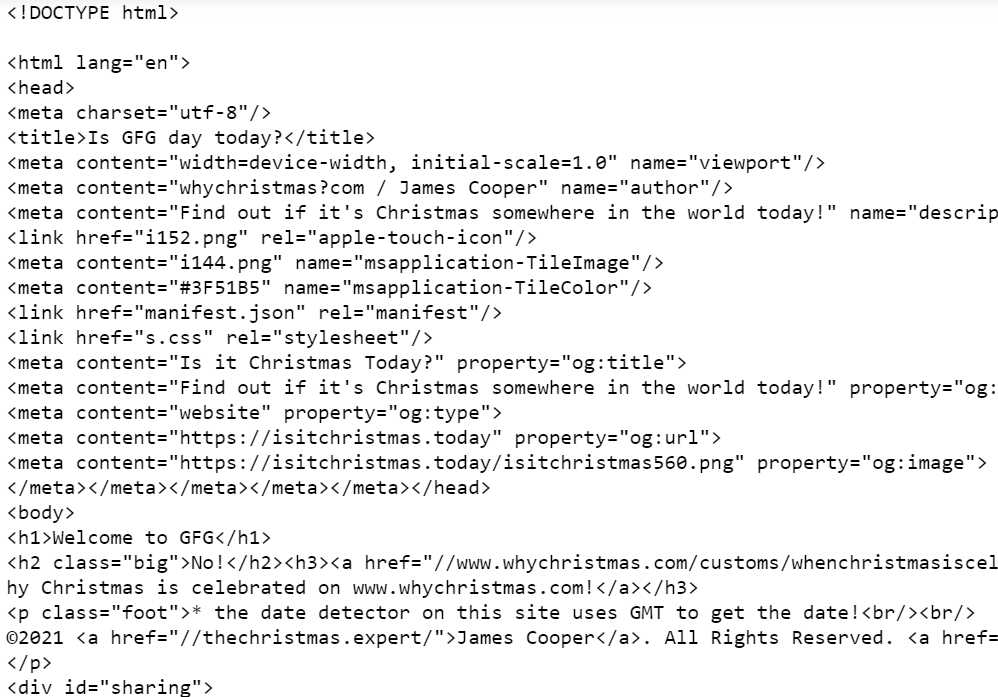
因此,原来的soup 变量中的title 标签和heading 标签被替换了。
注意:我们无法将修改后的页面推送回网站,因为这些页面是从托管它们的服务器呈现的。
下面是完整的程序:
蟒蛇3
import bs4
from bs4 import BeautifulSoup
import requests
# sending a GET requests
response = requests.get("https://isitchristmas.today/")
# a status 200 implies a sucessfull requests
#print(response.status_code)
soup = BeautifulSoup(response.text, "html.parser")
#print(soup)
title = soup.find("title")
heading = soup.find("h1")
# replacde
title.string = "Is GFG day today?"
heading.string = "Welcome to GFG"
# display replaced content
print(soup)
# The title and the heading tag contents
# get changed in the parsed soup obj.
输出:
