FastText 工作和实现
什么是快速文本?
FastText 是Facebook AI Research (FAIR) 的一个开源免费库,用于学习词嵌入和词分类。该模型允许创建无监督学习或监督学习算法来获得单词的向量表示。它还评估这些模型。 FastText支持 CBOW 和 Skip-gram 模型。
FastText 的用途:
- 它用于查找语义相似性
- 它还可以用于文本分类(例如:垃圾邮件过滤)。
- 它可以在几分钟内训练大型数据集。
FastText 的工作:
FastText 在训练词向量模型方面非常快。您可以在不到 10 分钟的时间内训练大约 10 亿个单词。通过深度神经网络构建的模型的训练和测试速度可能很慢。这些方法使用线性分类器来训练模型。
线性分类器:在本文中,标签表示为向量。我们找到向量表示,使得文本及其相关标签具有相似的向量。简单来说,文本对应的向量更接近其对应的标签。
为了找到给定关联文本的正确标签的概率分数,我们使用softmax函数:

- 这里 travel 是标签,car 是与之相关的文本。
为了最大化正确标签的概率,我们可以使用梯度下降算法。
这在计算上非常昂贵,因为对于每段文本,我们不仅必须获得与其正确标签相关联的分数,而且还需要获得训练集中所有其他标签的分数。这限制了这些模型在非常大的数据集上的使用。
FastText 通过使用分层分类器来训练模型来解决这个问题。
FastText 使用的分层分类器:
在这种方法中,它表示二叉树中的标签。二叉树中的每个节点都代表一个概率。标签由沿着给定标签的路径的概率表示。这意味着二叉树的叶节点代表标签。

FastText 使用 Huffman 算法来构建这些树,以充分利用类可能不平衡的事实。频繁出现的标签的深度小于不常见的标签。
使用二叉树可以加快搜索时间,因为不必遍历所有不同的元素,只需搜索节点即可。所以现在我们不必计算每个可能标签的分数,我们只需要计算通往一个正确标签的路径中每个节点的概率。因此,这种方法大大降低了训练模型的时间复杂度。
提高速度不会牺牲模型的准确性。
- 当我们有未标记的数据集时,FastText 使用N-Gram 技术来训练模型。让我们更详细地了解这种技术是如何工作的——
让我们考虑数据集中的一个词,例如:“kingdom”。现在它会看一下“kingdom”这个词,并将它分解成它的 n-gram 组件,如下所示:
kingdom = ['k','in','kin','king','kingd','kingdo','kingdom',...]
这些是给定单词的一些 n-gram 组件。这个词会有更多的组成部分,但这里只列出了一些只是为了得到一个想法。可以根据您的选择选择 n-gram 组件的大小。 n-gram 的长度可以介于所选字符的最小和最大数量之间。您可以分别使用-minn和-maxn标志来实现。
注意:当您的文本不是来自特定语言的单词时,使用 n-gram 将没有意义。例如:当语料库包含 id 时,它不会存储单词而是存储数字和特殊字符。在这种情况下,您可以通过将-minn和-maxn参数选择为 0 来关闭 -gram 嵌入。
当模型更新时,fastText 会学习每个 n-gram 以及整个单词标记的权重。
以这种方式,每个标记/单词将被表示为其 n-gram 组件的总和和平均值。
- 通过 fastText 生成的词向量包含有关其子词的额外信息。在上面的例子中,我们可以看到“kingdom”这个词的组成部分之一是“king”这个词。此信息有助于模型在两个词之间建立语义相似性。
- 它还允许捕获语料库中给定单词的后缀/前缀的含义。
- 它也允许为不同或罕见的词生成更好的词嵌入。
- 它还可以为词汇外(OOV)词生成词嵌入。
- 在使用 fastText 时,即使您不删除停用词,其准确性也不会受到影响。如果您喜欢,您可以对您的语料库执行简单的预处理步骤。
- 由于 fastText 具有提供子词信息的特性,因此它也可以用于形态丰富的语言,如西班牙语、法语、德语等。
我们确实通过 fastText 获得了更好的词嵌入,但与 word2vec 或 GloVe 相比,它使用了更多的内存,因为它为每个词生成了很多子词。
FastText 的实现
首先,我们必须构建 fastText。为此,请按照以下步骤操作 –
In your terminal run the below commands-
$ wget https://github.com/facebookresearch/fastText/archive/v0.9.2.zip
$ unzip v0.9.2.zip
$ cd fastText-0.9.2
$ make
注意:如果您的 make 命令给出了类似这样的错误 – 'make' 不是内部或外部命令、可运行的程序或批处理文件。您可以通过单击链接下载 MinGW。
在此之后,您需要将其 bin 文件夹的路径添加到系统变量中,然后您可以使用它代替make 命令作为-
$ mingw32-make
我们已经成功构建了 fastText。
fastText 支持的命令是——
supervised train a supervised classifier
quantize quantize a model to reduce the memory usage
test evaluate a supervised classifier
test-label print labels with precision and recall scores
predict predict most likely labels
predict-prob predict most likely labels with probabilities
skipgram train a skipgram model
cbow train a cbow model
print-word-vectors print word vectors given a trained model
print-sentence-vectors print sentence vectors given a trained model
print-ngrams print ngrams given a trained model and word
nn query for nearest neighbors
analogies query for analogies
dump dump arguments,dictionary,input/output vectors
现在我已经获取了亚马逊评论数据集并将其保存为 amazon_reviews.txt。您还可以对数据执行一些预处理以获得更好的结果。
我们将训练一个skipgram模型。进入 fastText-0.9.2 目录后,运行以下命令-
$ fasttext skipgram -input amazon_reviews.txt -output model_trained
这里的输入文件是amazon_reviews.txt 。如果文件不在 dame 目录中,请确保提供文件的完整路径。 model_trained是为输出文件指定的名称。
您还可以根据您的要求显式添加其他参数,例如 epos 等。这里我们使用了默认值。
它首先开始读取输入文档中存在的单词。该文件由 3200 万字组成,预计到达时间约为 15 分钟。

它给出了神经网络学习率的详细统计数据,每个线程每秒处理多少单词。它还显示了随着模型的训练而不断减小的损失值。
模型训练好后,我们会生成两个文件,即model_trained.bin和model_trained.vec 。 .bin文件包含模型的参数和字典。这是 fasttext 使用的文件。 .vec文件是一个包含词向量的文本文件。这是您将在应用程序中使用的文件。
我们现在将使用我们的词向量并对其执行一些操作-
1) 为给定的词寻找最近邻
要初始化最近邻居接口,请执行以下命令:
$ fasttext nn model_trained.bin
界面会询问您要查找最近邻的查询词。查询词“brutality”的输出是-
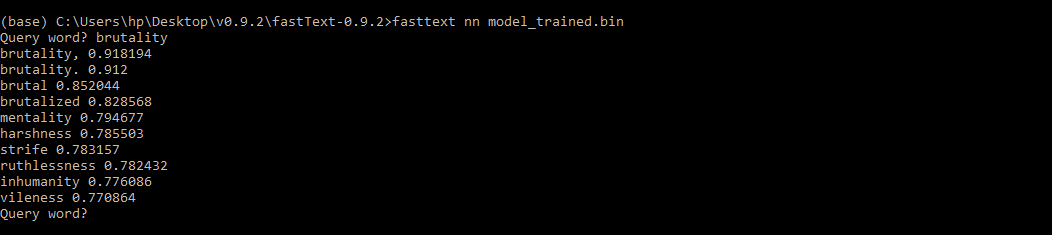
2) 进行单词类比
要对单词执行( A – B + C )形式的单词类比,您可以执行以下命令:
$ fasttext analogies model_trained.bin
A = king , B = man , C = women 的类比词是:
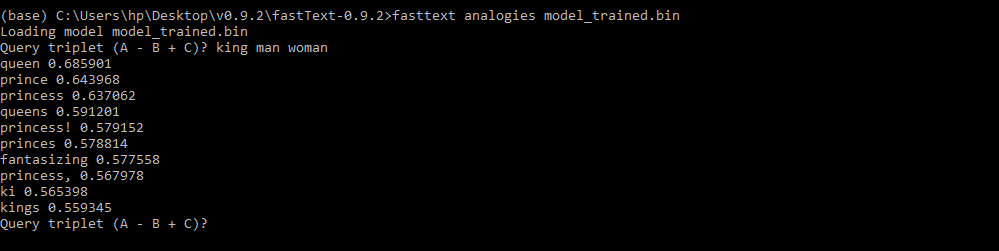
查询的第一个输出是“ queen ”,这是该查询可能的最正确答案。因此,我们训练的模型非常准确。
您还可以执行其他操作,例如使用测试数据文件测试模型、预测正确标签、获取给定单词的 n-gram 等。您可以使用 fasttext 中提供的上述命令来执行这些操作。