顺序覆盖算法
先决条件:学习一条规则算法
顺序覆盖是一种基于规则分类的流行算法,用于学习一组析取的规则。这里的基本思想是学习一个规则,删除它涵盖的数据,然后重复相同的过程。在这个过程中,通过这种方式,它在训练阶段按顺序覆盖了所有与之相关的规则。
涉及的算法:
Sequential_covering (Target_attribute, Attributes, Examples, Threshold):
Learned_rules = {}
Rule = Learn-One-Rule(Target_attribute, Attributes, Examples)
while Performance(Rule, Examples) > Threshold :
Learned_rules = Learned_rules + Rule
Examples = Examples - {examples correctly classified by Rule}
Rule = Learn-One-Rule(Target_attribute, Attributes, Examples)
Learned_rules = sort Learned_rules according to performance over Examples
return Learned_rules
顺序学习算法在一定程度上解决了学习一个规则算法中以顺序方式覆盖所有规则的低覆盖率问题。
在算法上工作:
该算法涉及要做出的一组“有序规则”或“决策列表”。
Step 1 – create an empty decision list, ‘R’.
Step 2 – ‘Learn-One-Rule’ Algorithm
It extracts the best rule for a particular class ‘y’, where a rule is defined as: (Fig.2)
规则的一般形式

In the beginning,
Step 2.a – if all training examples ∈ class ‘y’, then it’s classified as positive example.
Step 2.b – else if all training examples ∉ class ‘y’, then it’s classified as negative example.
Step 3 – The rule becomes ‘desirable’ when it covers a majority of the positive examples.
Step 4 – When this rule is obtained, delete all the training data associated with that rule.
(i.e. when the rule is applied to the dataset, it covers most of the training data, and has to be removed)
Step 5 – The new rule is added to the bottom of decision list, ‘R’. (Fig.3)

图 3:决策列表“R”
下面是描述算法工作的可视化表示。
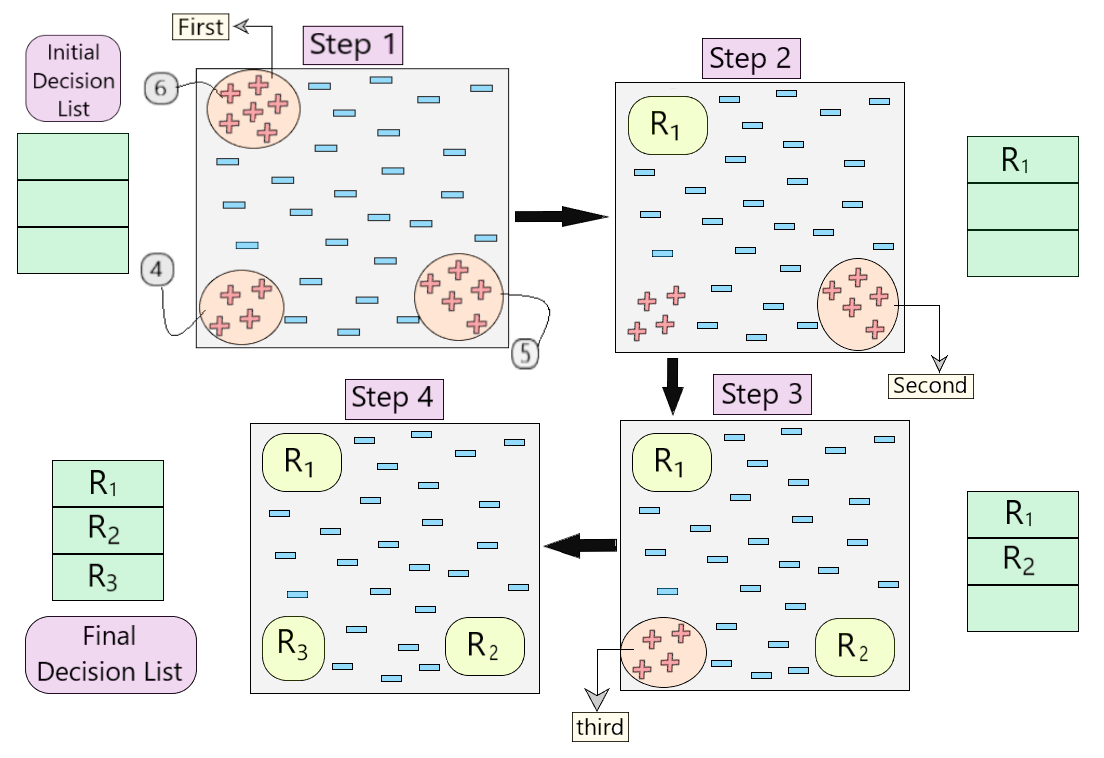
图 4:算法工作的可视化表示
- 让我们逐步了解算法在图 4 所示示例中的工作原理。
- 首先,我们创建了一个空的决策列表。在步骤 1 中,我们看到数据集中存在三组正例。因此,根据算法,我们考虑正例数最大的那个。 (6,如图4的步骤1所示)
- 一旦我们覆盖了这 6 个正例,我们就得到了我们的第一个规则 R 1 ,然后将其推入决策列表,并从数据集中删除这些正例。 (如图4的步骤2所示)
- 现在,我们采用接下来的大多数正例(5,如图 4 的步骤 2 所示)并遵循相同的过程,直到我们得到规则 R 2 。 (R 3相同)
- 最后,我们获得了包含所有理想规则的最终决策列表。
顺序学习是一种强大的算法,用于在机器学习中生成基于规则的分类器。它使用“Learn-One-Rule”算法作为学习一系列析取规则的基础。有关算法的疑问/疑问,请在下面发表评论。