分类中使用的交叉熵成本函数
成本函数的简要概念
您的老师如何评估您是否在整个学年都学习过?她在最后进行测试,并通过交叉检查您的答案与所需答案来对您的表现进行评分。如果你设法保持了自己的准确性,并且你的分数超过了某个基准,那么你就通过了。如果您还没有(尽管不太可能),您需要提高准确性并再次尝试。因此,粗略地说,测试用于分析您在课堂上的表现。
在机器学习术语中,“成本函数”用于评估模型的性能。可能出现的一个重要问题是,我如何评估我的模型的性能如何?就像老师通过根据所需答案验证您的答案来评估您的准确性一样,您通过将模型预测的值与实际值进行比较来评估模型的准确性。成本函数量化了实际值和预测值之间的差异,并将其存储为单值实数。如果仅考虑单个训练示例中的误差,则成本函数可以类似地称为“损失函数”。请注意,这些仅适用于利用优化技术的监督机器学习算法。由于成本函数是衡量我们的预测值与正确标记值的偏差程度的度量,因此可以认为它是一个不充分的度量。因此,所有优化技术都倾向于努力将其最小化。
在本文中,我们将仅介绍主要用于分类模型的成本函数。
交叉熵成本函数
香农熵背后的想法
随机变量X的熵可以作为变量可能结果的不确定性来衡量。这意味着确定性/概率越大,熵越小。
计算熵的公式可以表示为:
(1) 
(2) 
让我们举一个简单的例子。
您有3 个礼篮,每个礼篮包含10 个糖果。
第一个礼篮有 3 个 Eclairs 和 7 个 Alpenliebes。

红色=泡芙,黄色=Alpenliebe
第二个礼篮有 5 个 Eclairs 和 5 个 Alpenliebes。

第三个篮子有 10 个 Eclairs 和 0 个 Alpenliebes。

使用上述方程,我们可以计算上述每种情况下的熵值。

您现在可以看到,由于礼盒 2 的不确定度最高,它的熵是可能的最高值,即 1。另外,由于礼盒 3 只有一种糖果,因此可以 100% 确定抽出的糖果是泡芙。因此,不存在不确定性,熵为 0。
交叉熵的成本函数
现在您已经熟悉了熵,让我们进一步深入研究交叉熵的成本函数。
让我们举一个三类分类问题的例子。模型应接受图像并区分图像是否可以分类为苹果、橙子或芒果的图像。处理后,模型将以概率分布的形式提供输出。预测的类别将具有最高的概率。
- 苹果 = [1,0,0]
- 橙色 = [0,1,0]
- 芒果 = [0,0,1]
这意味着如果模型正确预测的类别是苹果。那么预测苹果的概率分布应该趋向于最大概率分布值,即1。如果不是这样,模型的权重需要调整。
假设以下 logits 是预测值:

苹果、橙子和芒果的Logits
这些是输入图像(苹果、橙子和芒果)各自的 logit 值。我们可以部署一个Softmax函数来将这些 logit 转换为概率。我们之所以使用 softmax 是因为它是一个连续可微的函数。这使得计算神经网络中每个权重的成本函数的导数成为可能。

期望值与预测值之差,即1和0.723= 0.277
尽管苹果的概率不完全是 1,但它比所有其他选项更接近 1。

经过后续的连续迭代训练,该模型可能会显着提高其输出概率并减少损失。这就是交叉熵如何降低成本函数并使模型更准确的方式。用于预测成本函数的公式为:
(3) 
多类分类成本函数
就像前面提到的示例一样,多类分类是存在多个类但输入仅适合 1 个类的场景。水果实际上不可能既是芒果又是橙子,对吧?
让模型的输出突出显示固定输入“d ”的“ c”类的概率分布。
(4) ![\begin{equation*} p(d)=\left[\begin{array}{c} p 1 \\ p 2 \\ p c \end{array}\right] \end{equation*}](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/Cross-Entropy_Cost_Functions_used_in_Classification_10.png "由 QuickLaTeX.com 渲染")
另外,设实际概率分布为
(5) ![\begin{equation*} \mathrm{y}(\mathrm{d})=\left[\begin{array}{l} \mathrm{y} 1 \\ \mathrm{y} 2 \\ \mathrm{y} 3 \end{array}\right] \end{equation*}](https://mangodoc.oss-cn-beijing.aliyuncs.com/geek8geeks/Cross-Entropy_Cost_Functions_used_in_Classification_11.png "由 QuickLaTeX.com 渲染")
因此,交叉熵成本函数可以表示为:
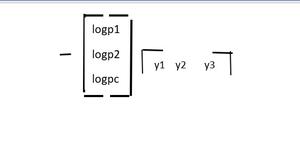
请注意,对于所有“c”项,y3=yc

现在,如果我们以苹果、橙子和芒果为例的概率分布为例,并代入公式中的值,我们得到:
- p(苹果)=[0.723, 0.240, 0.036]
- y(苹果)=[1,0,0]
交叉熵(y,P) 损失 = – (1*log(0.723) + 0*log(0.240)+0*log(0.036)) = 0.14
这是交叉熵损失的值。
分类交叉熵
完整模型的分类误差由完整训练数据集的交叉熵平均值给出。这就是分类交叉熵。当实际值标签被单热编码时,使用分类交叉熵。这意味着一次只有一个“位”数据为真,例如 [1,0,0]、[0,1,0] 或 [0,0,1]。分类交叉熵在数学上可以表示为:
分类交叉熵 =(N 个数据的交叉熵之和)/N
二元交叉熵成本函数
在二元交叉熵中,也只有一种可能的输出。此输出可以有离散值,0 或 1。例如,让特定水果图像的输入是苹果或橙子的图像。现在,让我们重写这句话:水果要么是苹果,要么不是苹果。只有二进制的真假输出是可能的。
让我们假设实际输出表示为变量 y
现在,特定数据“d”的交叉熵可以简化为
- 当 y = 1 时,交叉熵(d) = – y*log(p)
- 当 y = 0 时,交叉熵 (d) = – (1-y)*log(1-p)
此方法的问题实现与多类成本函数的问题实现相同。不同之处在于只能接受二进制类。
稀疏分类交叉熵
在稀疏分类交叉熵中,真值标签用整数值标记。例如,如果考虑 3 类问题,标签将被编码为 [1]、[2]、[3]。
请注意,Keras API 提供了二进制交叉熵成本函数、分类交叉熵和稀疏分类交叉熵。