GAN vs Adversarial Autoencoder 模型的选择
在本文中,我们将看到 GAN 与 Adversarial Autoencoder 模型的选择。
生成对抗网络 ( GAN)
生成对抗网络(GAN)是目前最突出的深度生成建模方法之一。 GAN 和 VAE 之间的主要区别在于 GAN 寻求匹配像素级分布而不是数据分布,并且它以不同的方法将模型分布优化为真实分布。
GAN 创建图像的过程是什么?图像只不过是像素值的向量。另一方面,随机值不能用于创建物品的图片。为了使狗的图片看起来像狗,像素必须具有一定的值并以特定的方式放置。因此,我们可以声明这些向量必须遵循特定的分布才能像狗一样。因此,GAN 的目标是将随机向量作为输入,并将其转换为与我们预期输出相匹配的像素分布。
因此,潜在变量或 GAN 输入本身除了网络提供的意义之外没有任何意义。潜在空间中的任何点都将被模型映射到有意义的输出。
训练 GAN 网络:
尽管我们知道 GAN 会改变输入以遵循对象分布,但 GAN 如何优化网络以学习输出分布?有“直接”和“间接”方法可以做到这一点。通过比较真实分布与创建分布、确定错误并适当调整网络,使用“直接”技术。生成匹配网络 (GMN) 使用了这种方法。另一方面,生产的真正分配可能很复杂。与高斯分布不同,它可以仅使用均值和方差来描述。明确表达真实和生产的分布将是具有挑战性的。相反,使用来自实际分布和创建的分布的样本来比较分布。我们可以使用真实数据和创建数据的样本来估计分布并检查差异。
另一方面,GAN 采用“间接”方法,使用单独的网络(鉴别器)对实际数据和生成数据进行分类。简而言之,GAN 架构由两部分组成:判别器,用于对真实数据和生产数据进行分类;生成器,用于误导判别器将错误样本分类为真实数据。
训练 GAN 的过程:
- 通过冻结生成器的权重来训练判别器(仅更新判别器),使用生成器创建错误样本(最初,这将是噪声,因为生成器一开始没有经过训练),对真实样本进行采样并使用实际和训练判别器虚构的例子(使用真假标签)。
- 然后,通过将鉴别器的权重设置为零来训练生成器(仅更新生成器),使用生成器创建虚假样本,然后使用虚假样本作为输入以鉴别器输出训练生成器
- 重复步骤 1 和 2
对抗网络
对抗性自动编码器 (AAE) 是一个出色的概念,它将自动编码器架构与 GAN 的对抗性损失概念相结合。它的工作方式与变分自动编码器 (VAE) 类似,除了它不是使用 KL 散度,而是利用对抗性损失来规范潜在代码。
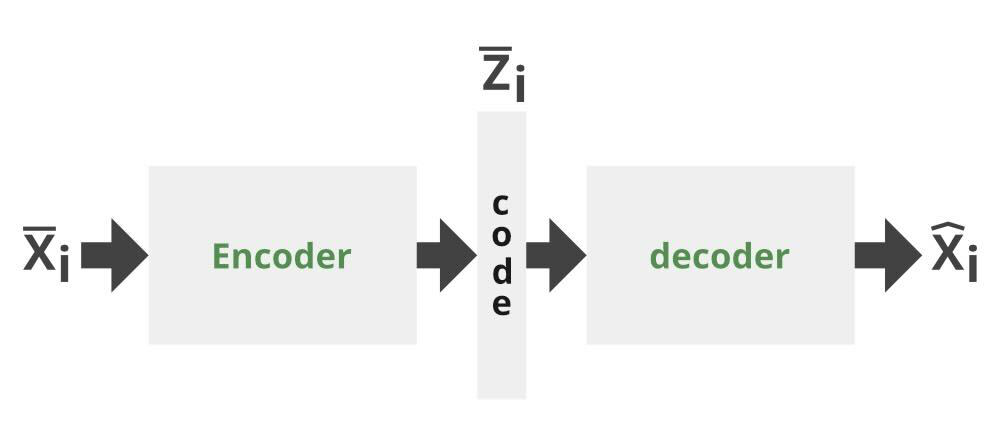
为了使编码的潜在编码适合正态分布,VAE 使用 KL 散度(分布之间的差异)(或选择的任何任意分布)。 AAE 用对抗性损失代替了这一点,这增加了一个额外的鉴别器组件并使编码器成为生成器。与生成器的输出是创建的图片而鉴别器的输入是真假图像的 GAN 不同,AAE 的生成器创建一个潜在代码并试图让鉴别器相信该潜在代码是从指定分布中采样的。另一方面,鉴别器将确定特定的潜在代码是由自动编码器创建的(假的)还是从正态分布中提取的随机向量(真实的)。
三种不同类型的编码器可供选择:
- 编码器将尝试将输入压缩为表示为向量 z 的指定特征,这与自动编码器中使用的编码器相同。
- 高斯后验编码器不是将每个特征编码为单个值,而是使用均值和方差这两个变量来存储每个特征的高斯分布。
- 这些特征也被编码为使用 Universal Approximator Posterior 的分布。但是,我们不假设特征分布遵循高斯分布。本例中的编码器将是一个函数f(x, n),其中 x 是输入,n 是具有任何可能分布的随机噪声。
因此,AAE 架构由以下元素组成:
- 编码器将接受输入并将其转换为低维格式(潜在代码 z)
- 解码器会将潜在代码 z 转换为结果图片。
- 鉴别器使用来自自动编码器的编码潜在代码 z(假)以及从指定分布(真实)中选择的随机向量 z。它将验证输入是否真实。
如上面的架构所示,编码器和鉴别器是 AAE 和 GAN 之间的两个基本区别。与 GAN 不同,AAE 使用图像作为其输入,而不是随机向量 z。这是通过在开始时包含一个编码器来实现的。此外,AAE 试图使潜在代码遵循正态分布(或您选择的分布)。这是通过改变鉴别器作业来预测潜在代码 z 是由自动编码器创建还是从正态分布导出来实现的。与 GAN 不同,判别器的工作是预测给定图片是真还是假,这里判别器的工作是预测给定图像是真还是假(假)。
应用
Adversarial Autoencoder令人兴奋的应用之一是在异常检测和定位任务中,需要一种无监督的方法来检测异常。可以训练自动编码器将异常图像重建为正常图像,通过计算没有异常的重建图像与原始异常图像之间的差异来检测异常。