R 编程中的数据争论——数据转换
数据集可以以多种不同的方式呈现给世界。让我们看看最本质和基本的区别之一,无论数据集是宽还是长。
宽数据集和长数据集的区别在于我们更喜欢在数据集中拥有更多行还是更多列。专注于放置有关单个列的附加数据的数据集被称为宽数据集,因为随着我们添加越来越多的列,数据集变得更宽。同样,专注于在行中包含有关主题的数据的数据集称为长数据集。
在 R 中的数据整理中,有时我们需要使长数据集更宽,反之亦然。一般来说,接受整洁数据概念的数据科学家通常更喜欢长数据集而不是宽数据集,因为更长的数据集在 R 中操作起来更舒服。
![]()
在上图中,同一数据集表示为宽数据集和长数据集。这是一个带有收入分类的宗教数据集。当您了解什么是长数据集和宽数据集时,让我们尝试使用 R 中的工具将宽数据集转换为长数据集,将长数据集转换为宽数据集。
将 Wide 数据集转换为 long
'tidyr'包中的gather()函数使宽数据集变长。收集函数适用于键和值的概念。数据值表示对单个变量的观察,而键是用于标识由值描述的变量的名称。
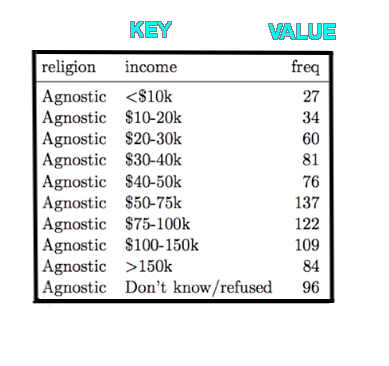
在上面的数据集中,收入作为关键,通过对不同宗教的收入进行分类,频率为收入关键提供了值。
Syntax:
gather(data, key, value, columns)
Parameters:
data: The Tibble name
key: The name that we would like to use for the key column in the long dataset.
value: The name we would like to apply for the value column in the long dataset.
columns: list of columns from the wide dataset that we would like to include or exclude from the gathering.
或者,如果您想收集大部分列,您可以通过在列前加上减号 (-) 来指定不想收集的列。
# Making Wide Datasets Long with gather()
# Load the tidyverse
library(tidyverse)
# Read in the dataset
sample_data <- read.csv("C:/Users/Admin/Desktop/pew.csv")
sample_data
sample_data_long <- gather(sample_data, income, freq, -religion)
sample_data_long
输出:
![]()
![]()
长数据集到宽数据集的转换
有时需要执行gather()函数的反向操作。因此spread()函数用于将长数据集转换为更宽的数据集。
Syntax:
spread(data, key, value)
Parameters:
data: The Tibble name
key: The name that we would like to use for the key column in the long dataset.
value: The name we would like to apply for the value column in the long dataset.
library(tidyverse)
sample_data <- read.csv("C:/Users/Admin/Desktop/mexicanweather.csv")
sample_data
sample_data_wide <- spread(sample_data, element, value)
sample_data_wide
输出:
![]()
![]()
现在我们可以看到只有墨西哥数据集一半大小的 Tibble。我们有 Tmax 和 Tmin 列,不再有元素或值列。