惰性代码运动问题
惰性代码运动问题:
为了避免冗余计算、减少代码大小或节省资源,代码移动性优化在控制流图 (CFG) 中移动计算。例如,循环不变代码运动识别在循环中计算的表达式,这些表达式在迭代后具有相同的值迭代,并将它们提升到循环之外,以便它们只计算一次。与其在表达式 f(e) 和 g(e) 中计算子表达式 'e' 两次,不如计算一次并将其存储在临时寄存器中。
main {
one: int = const 1;
do_nothing
compute:
y: int = add x one;
gfgdone;
do_nothing:
gfgdone;
done:
z: int = add x one;
ret;
}通过程序的所有路径现在只包括一个 x+1 计算。这是最佳代码,至少在那个维度上,并且是部分冗余删除或惰性代码运动的合理结果。那么,懒惰的代码运动与急切的替代品有什么区别呢?
记下压力:
在具有有限且固定数量的寄存器的架构中,编译器在将 IR 代码简化为汇编时,必须为有限但无限数量的变量分配存储空间。如果变量多于寄存器,一些变量将在堆栈中结束。内存比寄存器慢,因此“溢出”到堆栈是昂贵的。
编译器应该旨在减少在早期通道中寄存器分配期间引入的溢出量。引入程序的确切溢出量由所使用的寄存器分配技术确定,因此针对该统计数据进行优化是一件愚蠢的事情。
通过急切的代码运动,变量定义(计算)远离了它们的用途,从而延长了它们的生命范围。由于伴随的寄存器压力,可以很容易地从代码运动中获得任何性能优势。懒惰的代码运动,而不是尽可能早地进行计算,而是将它们转移到稍后的程序点,避免不必要的处理。实际上,一项研究表明,惰性代码运动“尽可能晚地进行计算,尽管这个短语在脱离上下文时会产生误导。在选择最近的可能性之前,系统会进行静态分析以找到潜在的安全移动。
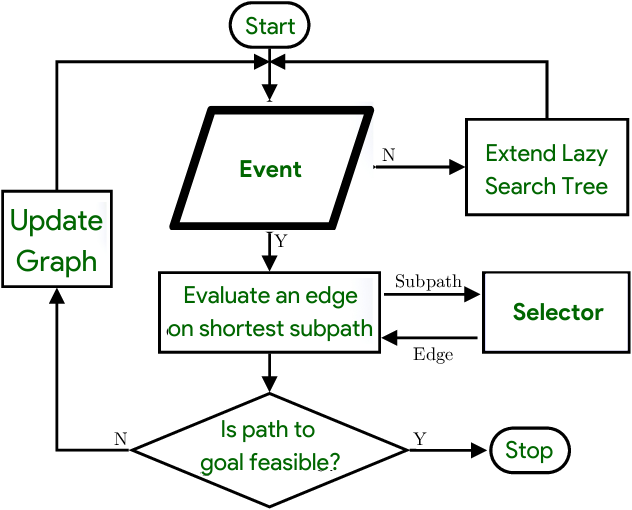
懒惰的代码问题
限制:
根据优化,词法相等的表达式应始终放在同一个伪寄存器中。以后的研究可能会对数据流分析进行更改以削弱这一假设。这会导致多余的移动指令从临时对象中获取计算值,从而增加寄存器压力。更智能的重写通行证可能能够减少这些费用。
计算布局算法在优化范围的另一端效率低下。惰性代码运动将计算移动到 CFG 的边缘,需要将新的基本块缝合到边缘。虽然在大多数情况下都需要它们,但插入的基本块可以在许多边上与其前任或后继块安全地合并。因为跳跃的数量会减少,这可能会提高性能。同样,CFG 的漂亮打印机也不会忽略掉线可以工作的跳跃——这似乎是一件微不足道的事情,但它可能会影响性能或代码大小。这两个问题都可以通过在惰性代码移动后运行简化过程来解决。
结论 :
优化后计算量永远不会增加,因为惰性代码运动旨在避免冗余表达式计算。谨慎的临时分配技术和基本块插入的成本似乎通过添加移动和跳跃对计算总数产生不利影响。由于计算被提升到循环之外,循环基准(基本,提升循环)显示出相当大的加速。