Python中的并行处理
并行处理可以增加程序完成的任务数量,从而减少整体处理时间。这些有助于处理大规模问题。
在本节中,我们将介绍以下主题:
- 并行处理简介
- 用于并行处理的多处理Python库
- IPython并行框架
并行处理简介
对于并行性,将问题划分为不依赖于其他子单元(或依赖性较小)的子单元很重要。子单元完全独立于其他子单元的问题称为embarrassingly parallel 。
例如,对数组的逐元素操作。在这种情况下,操作需要知道它当前正在处理的特定元素。
在另一种情况下,划分为子单元的问题必须共享一些数据才能执行操作。由于通信成本,这些导致性能问题。
处理并行程序有两种主要方法:
- 共享内存
在共享内存中,子单元可以通过相同的内存空间相互通信。优点是您不需要显式处理通信,因为这种方法足以从共享内存中读取或写入。但是当多个进程同时访问并更改相同的内存位置时,就会出现问题。使用同步技术可以避免这种冲突。
- 分布式内存
在分布式内存中,每个进程是完全分离的,有自己的内存空间。在这种情况下,进程之间的通信是显式处理的。由于通信是通过网络接口进行的,因此与共享内存相比,它的成本更高。
线程是实现共享内存并行的方法之一。这些是源自进程并共享内存的独立子任务。由于Global Interpreter Lock (GIL) ,线程不能用于提高Python的性能。 GIL 是一种机制,其中Python解释器设计一次只允许运行一条Python指令。通过使用进程而不是线程可以完全避免 GIL 限制。使用进程与共享内存相比几乎没有进程间通信效率低等缺点,但它更加灵活和明确。
用于并行处理的多处理
使用标准的多处理模块,我们可以通过创建子进程来有效地并行化简单的任务。该模块提供了一个易于使用的界面,并包含一组用于处理任务提交和同步的实用程序。
进程和池类
过程
通过子类化 multiprocessing.process,您可以创建一个独立运行的进程。通过扩展__init__方法,您可以初始化资源,并通过实现Process.run()方法,您可以为子进程编写代码。在下面的代码中,我们看到如何创建一个打印分配的 id 的进程:

要生成流程,我们需要初始化 Process 对象并调用Process.start()方法。这里Process.start()将创建一个新进程并调用Process.run()方法。
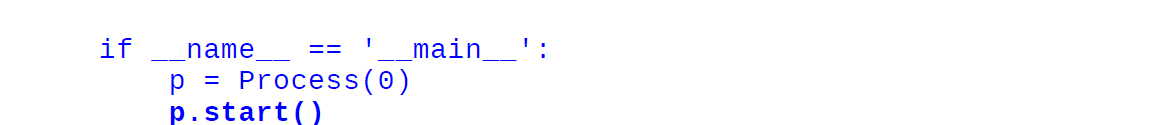
p.start()之后的代码将在进程 p 的任务完成之前立即执行。要等待任务完成,您可以使用Process.join() 。

这是完整的代码:
import multiprocessing
import time
class Process(multiprocessing.Process):
def __init__(self, id):
super(Process, self).__init__()
self.id = id
def run(self):
time.sleep(1)
print("I'm the process with id: {}".format(self.id))
if __name__ == '__main__':
p = Process(0)
p.start()
p.join()
p = Process(1)
p.start()
p.join()
输出:
泳池课
池类可用于并行执行不同输入数据的函数。 multiprocessing.Pool()类生成一组称为worker 的进程,并且可以使用方法apply/apply_async and map/map_async提交任务。对于并行映射,您应该首先初始化一个multiprocessing.Pool()对象。第一个参数是工人的数量;如果没有给出,该数字将等于系统中的核心数。
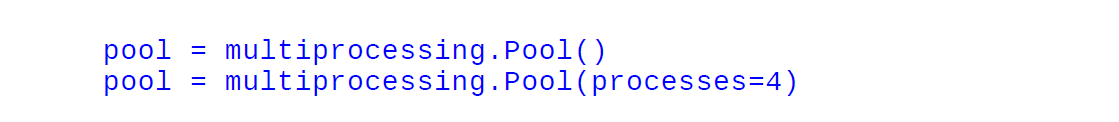
让我们通过一个例子来看看。在这个例子中,我们将看到如何传递一个计算数字平方的函数。使用Pool.map()您可以将函数映射到列表并将函数和输入列表作为参数传递,如下所示:

import multiprocessing
import time
def square(x):
return x * x
if __name__ == '__main__':
pool = multiprocessing.Pool()
pool = multiprocessing.Pool(processes=4)
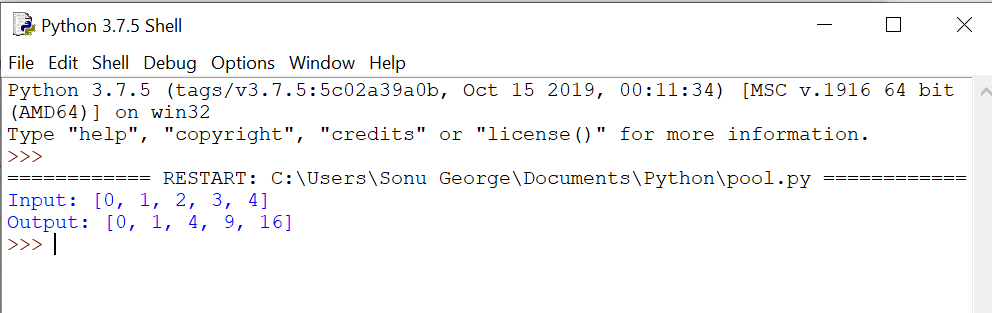
inputs = [0,1,2,3,4]
outputs = pool.map(square, inputs)
print("Input: {}".format(inputs))
print("Output: {}".format(outputs))
输出:
当我们使用法线贴图方法时,程序的执行会停止,直到所有的worker完成任务。使用map_async() ,在不停止主程序的情况下立即返回 AsyncResult 对象,并且任务在后台完成。可以随时使用AsyncResult.get()方法检索结果,如下所示:
import multiprocessing
import time
def square(x):
return x * x
if __name__ == '__main__':
pool = multiprocessing.Pool()
inputs = [0,1,2,3,4]
outputs_async = pool.map_async(square, inputs)
outputs = outputs_async.get()
print("Output: {}".format(outputs))
输出:

Pool.apply_async将由单个函数组成的任务分配给其中一个工作人员。它接受函数及其参数并返回一个 AsyncResult 对象。

import multiprocessing
import time
def square(x):
return x * x
if __name__ == '__main__':
pool = multiprocessing.Pool()
result_async = [pool.apply_async(square, args = (i, )) for i in
range(10)]
results = [r.get() for r in result_async]
print("Output: {}".format(results))
输出:

IPython 并行框架
IPython 并行包提供了一个框架,用于在单个、多核机器和连接到网络的多个节点上设置和执行任务。在 IPython.parallel 中,您必须启动一组称为 Engines 的工作人员,这些工作人员由 Controller 管理。控制器是帮助客户端和引擎之间进行通信的实体。在这种方法中,工作进程是单独启动的,它们将无限期地等待来自客户端的命令。
Ipcluster shell 命令用于启动控制器和引擎。
$ ipcluster start经过上述过程,我们可以使用 IPython shell 并行执行任务。 IPython 带有两个基本接口:
- 直接接口
- 基于任务的界面
直接接口
直接接口允许您向每个计算单元显式发送命令。这是灵活且易于使用的。要与单元交互,您需要启动引擎,然后在单独的 shell 中启动 IPython 会话。您可以通过创建客户端来建立与控制器的连接。在下面的代码中,我们导入 Client 类并创建一个实例:
from IPython.parallel import Client
rc = Client()
rc.ids
在这里, Client.ids将给出整数列表,其中给出了可用引擎的详细信息。
使用 Direct View 实例,您可以向引擎发出命令。我们可以通过两种方式获得直接视图实例:
- 通过索引客户端实例
dview = rc[0] - 通过调用 DirectView.direct_view 方法
dview = rc.direct_view(‘all’).
作为最后一步,您可以使用 DirectView.execute 方法执行命令。
dview.execute(‘ a = 1 ’)上述命令将由每个引擎单独执行。使用 get 方法可以获取 AsyncResult 对象形式的结果。
dview.pull(‘ a ‘).get()
dview.push({‘ a ’ : 2})
如上所示,您可以使用DirectView.push方法获取数据,并使用DirectView.pull方法发送数据。
基于任务的界面
基于任务的界面提供了一种处理计算任务的智能方式。从用户的角度来看,这有一个不太灵活的界面,但它在引擎上的负载平衡方面很有效,并且可以重新提交失败的作业,从而提高性能。
LoadBalanceView 类使用 load_balanced_view 方法提供基于任务的接口。
from IPython.parallel import Client
rc = Client()
tview = rc.load_balanced_view()
使用 map 和 apply 方法,我们可以运行一些任务。在 LoadBalanceView 中,任务分配取决于当时引擎上存在多少负载。这确保了所有引擎都可以在不停机的情况下工作。