在 Pandas 中处理缺失数据
当没有为一个或多个项目或整个单元提供信息时,可能会出现缺失数据。在现实生活场景中,缺少数据是一个非常大的问题。缺失数据也可以指熊猫中的NA (不可用)值。在 DataFrame 中,有时许多数据集只是带着缺失的数据到达,要么是因为它存在但未被收集,要么因为它从未存在。例如,假设被调查的不同用户可能选择不分享他们的收入,一些用户可能会选择不分享地址,这样很多数据集就丢失了。 
在 Pandas 中,缺失数据由两个值表示:
- None:None 是一个Python单例对象,通常用于Python代码中的缺失数据。
- NaN :NaN(Not a Number 的首字母缩写词),是所有使用标准 IEEE 浮点表示的系统都可以识别的特殊浮点值
Pandas 将None和NaN视为本质上可以互换以指示缺失值或空值。为了促进这一约定,Pandas DataFrame 中有几个用于检测、删除和替换空值的有用函数:
- 一片空白()
- 非空()
- 下降()
- 填充()
- 代替()
- 插()
在本文中,我们使用的是 CSV 文件,要下载使用的 CSV 文件,请单击此处。
使用isnull()和notnull()检查缺失值
为了检查 Pandas DataFrame 中的缺失值,我们使用函数isnull()和notnull() 。这两个函数都有助于检查一个值是否为NaN 。这些函数也可以在 Pandas 系列中使用,以便在系列中查找空值。
使用isnull()检查缺失值
为了检查 Pandas DataFrame 中的空值,我们使用isnull()函数,该函数返回布尔值的数据帧,对于 NaN 值是 True。
代码#1:
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
# creating a dataframe from list
df = pd.DataFrame(dict)
# using isnull() function
df.isnull()
输出: 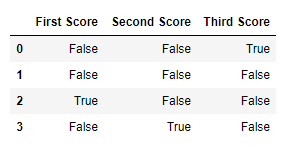 代码#2:
代码#2:
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# creating bool series True for NaN values
bool_series = pd.isnull(data["Gender"])
# filtering data
# displaying data only with Gender = NaN
data[bool_series]
输出:
如输出图像所示,仅显示Gender = NULL的行。 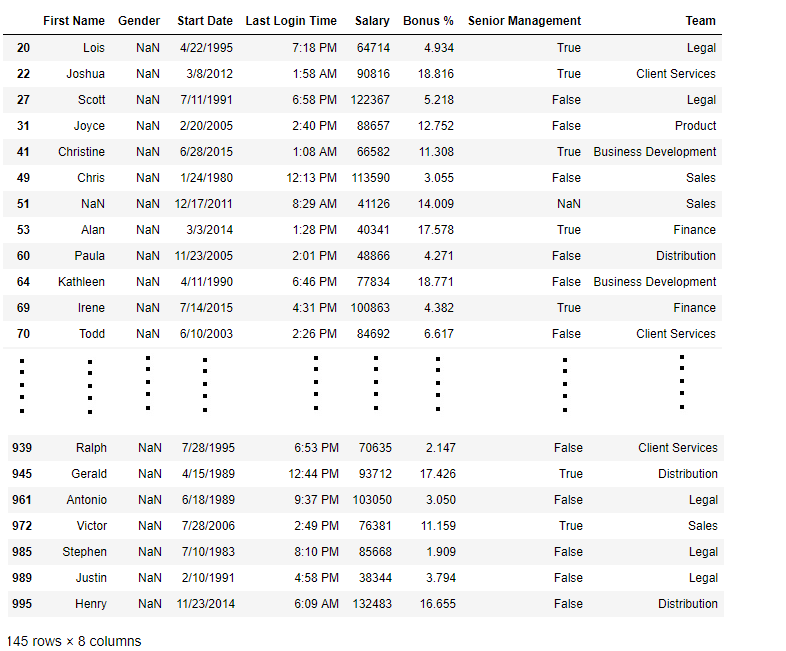
使用notnull()检查缺失值
为了检查 Pandas Dataframe 中的空值,我们使用 notnull()函数,该函数返回布尔值的数据帧,对于 NaN 值是 False。
代码#3:
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
# creating a dataframe using dictionary
df = pd.DataFrame(dict)
# using notnull() function
df.notnull()
输出: 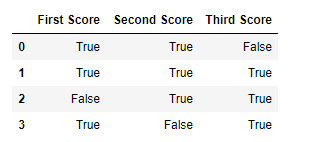 代码 #4:
代码 #4:
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# creating bool series True for NaN values
bool_series = pd.notnull(data["Gender"])
# filtering data
# displayind data only with Gender = Not NaN
data[bool_series]
输出:
如输出图像所示,仅显示Gender = NOT NULL的行。 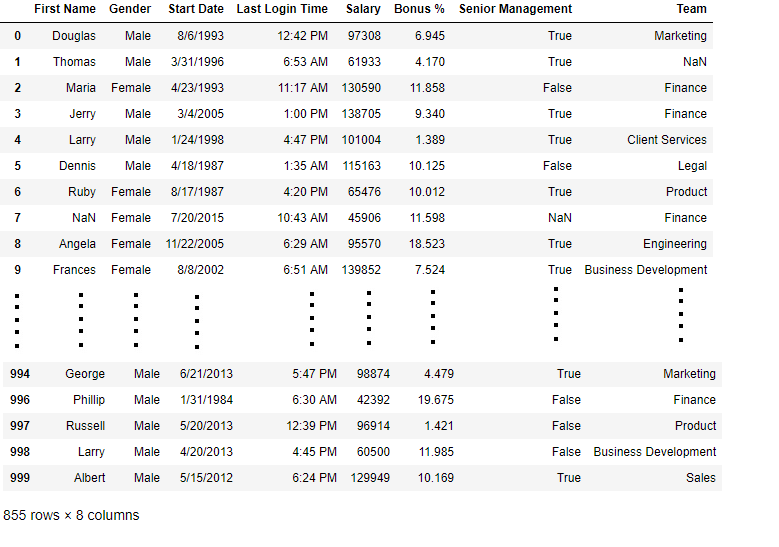
使用fillna() 、 replace()和interpolate()填充缺失值
为了填充数据集中的空值,我们使用fillna() 、 replace()和interpolate()函数,这些函数用它们自己的一些值替换 NaN 值。所有这些函数都有助于在 DataFrame 的数据集中填充空值。 Interpolate()函数基本上用于填充数据帧中的NA值,但它使用各种插值技术来填充缺失值,而不是对值进行硬编码。
代码 #1:用单个值填充空值
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
# filling missing value using fillna()
df.fillna(0)
输出: 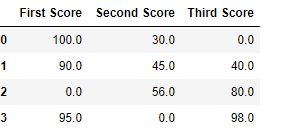 代码 #2:用之前的值填充空值
代码 #2:用之前的值填充空值
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
# filling a missing value with
# previous ones
df.fillna(method ='pad')
输出: 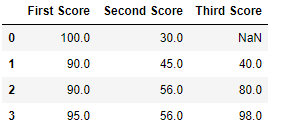 代码#3:用下一个填充空值
代码#3:用下一个填充空值
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
# filling null value using fillna() function
df.fillna(method ='bfill')
输出: 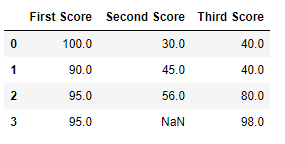 代码 #4:在 CSV 文件中填充空值
代码 #4:在 CSV 文件中填充空值
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# Printing the first 10 to 24 rows of
# the data frame for visualization
data[10:25]
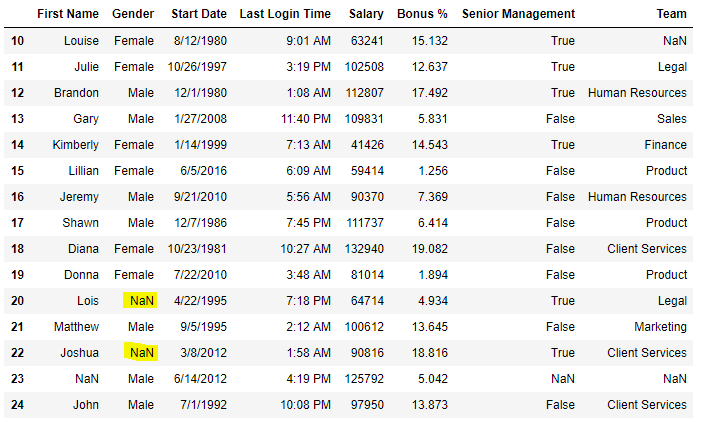
现在我们将用“No Gender”填充 Gender 列中的所有空值
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# filling a null values using fillna()
data["Gender"].fillna("No Gender", inplace = True)
data
输出: 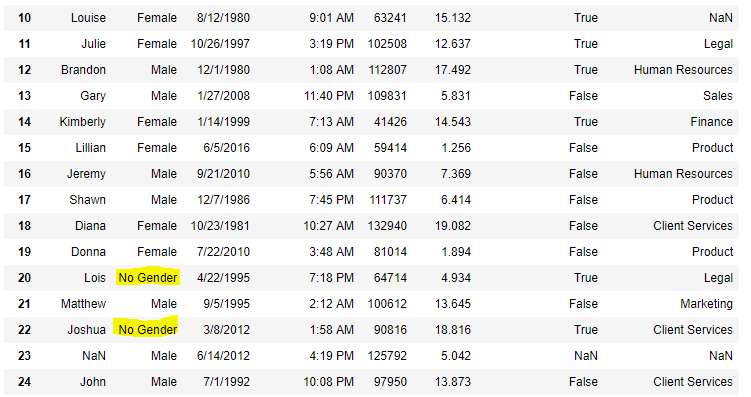
代码 #5:使用 replace() 方法填充空值
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# Printing the first 10 to 24 rows of
# the data frame for visualization
data[10:25]
输出: 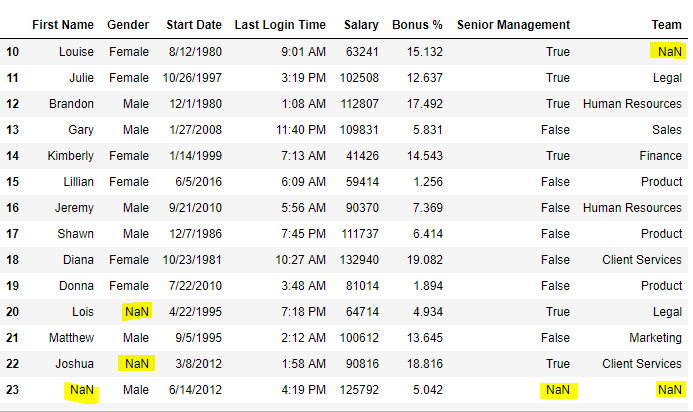
现在我们将数据框中的所有 Nan 值替换为 -99 值。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# will replace Nan value in dataframe with value -99
data.replace(to_replace = np.nan, value = -99)
输出: 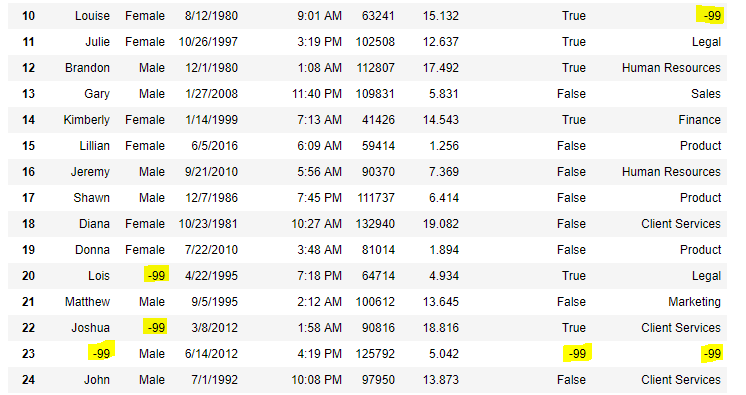 代码 #6:使用 interpolate()函数使用线性方法填充缺失值。
代码 #6:使用 interpolate()函数使用线性方法填充缺失值。
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.DataFrame({"A":[12, 4, 5, None, 1],
"B":[None, 2, 54, 3, None],
"C":[20, 16, None, 3, 8],
"D":[14, 3, None, None, 6]})
# Print the dataframe
df
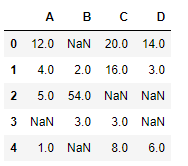
让我们使用线性方法对缺失值进行插值。请注意,线性方法忽略索引并将值视为等距。
# to interpolate the missing values
df.interpolate(method ='linear', limit_direction ='forward')
输出: 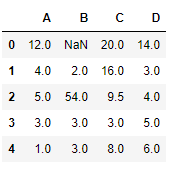
正如我们所看到的输出,第一行中的值无法被填充,因为值的填充方向是向前的,并且没有可以用于插值的先前值。
使用dropna()删除缺失值
为了从数据框中删除空值,我们使用dropna()函数,该函数以不同的方式删除具有空值的数据集的行/列。
代码 #1:删除至少有 1 个空值的行。
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
df
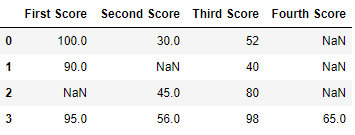
现在我们删除具有至少一个 Nan 值(Null 值)的行
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
# using dropna() function
df.dropna()
输出: 
代码 #2:如果该行中的所有值都丢失,则删除行。
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
df
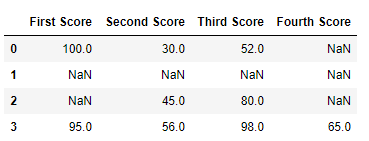
现在我们删除所有数据丢失或包含空值(NaN)的行
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
# using dropna() function
df.dropna(how = 'all')
输出: 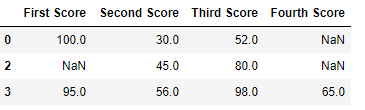
代码 #3:删除至少有 1 个空值的列。
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[60, 67, 68, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
df
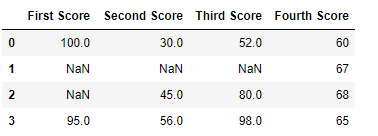
现在我们删除至少有 1 个缺失值的列
# importing pandas as pd
import pandas as pd
# importing numpy as np
import numpy as np
# dictionary of lists
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[60, 67, 68, 65]}
# creating a dataframe from dictionary
df = pd.DataFrame(dict)
# using dropna() function
df.dropna(axis = 1)
输出 : 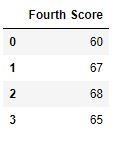 代码 #4:删除 CSV 文件中至少有 1 个空值的行
代码 #4:删除 CSV 文件中至少有 1 个空值的行
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# making new data frame with dropped NA values
new_data = data.dropna(axis = 0, how ='any')
new_data
输出: 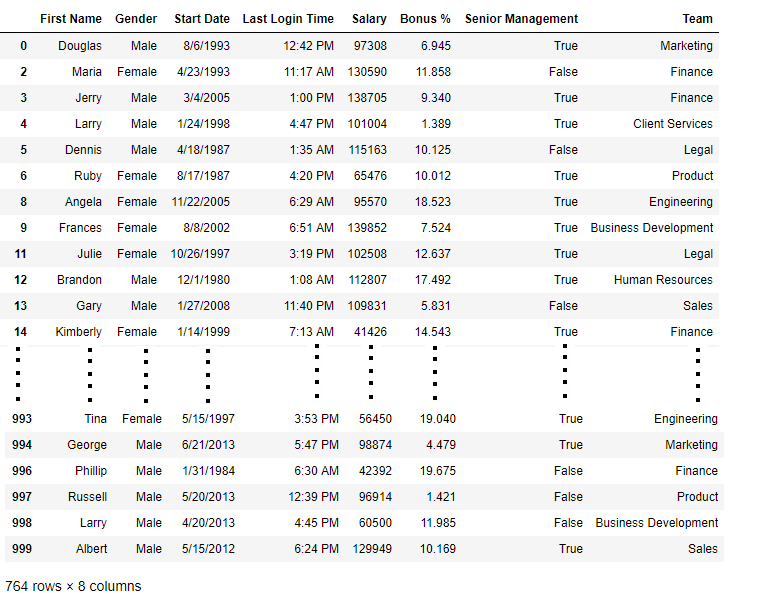
现在我们比较数据帧的大小,以便我们可以知道有多少行至少有 1 个 Null 值
print("Old data frame length:", len(data))
print("New data frame length:", len(new_data))
print("Number of rows with at least 1 NA value: ", (len(data)-len(new_data)))
输出 :
Old data frame length: 1000
New data frame length: 764
Number of rows with at least 1 NA value: 236
由于差异为 236,因此有 236 行在任何列中至少有 1 个 Null 值。