处理 Julia 中的缺失数据
如今,大数据的常见问题之一是分析该数据中的缺失值。缺失值可能导致一些重大的预测错误,这对任何业务观点都不利。因此,当我们遇到任何缺失数据时,我们必须应用不同的技术来处理数据集中的缺失值。

缺少对象
Julia 的缺失对象是最强大、最快速的用户定义类型,它比大多数内置类型(如 NA、NaN 等)要好得多。它还支持许多自定义类型以利用更多优势。
为了提供缺失值的一些预定义类型和一些自定义类型之间的一致性,Julia 引入了新的缺失对象,一个没有字段的对象,它是 Missing 单例类型的唯一实例。值可以是 T 类型或缺失值。它可以声明为Union{Missing, T} 。
# missing object cast as Int
[1, missing]
# missing object cast as Char
['1', missing]
# missing object cast as Float64
[1.0, missing]
输出:
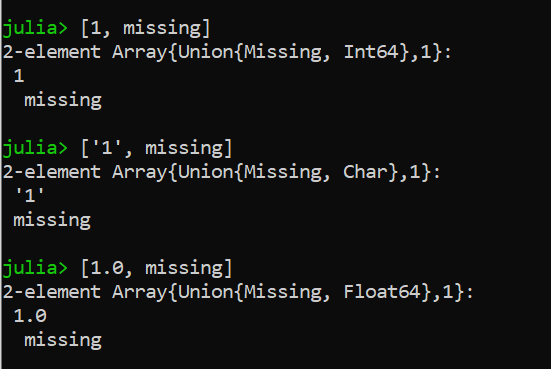
Julia 的新缺失框架更加通用和高效。它确保了安全性,缺失值永远不应该被忽略或替换为任何非缺失值。使用此缺失对象执行的任何数学运算都不会影响数据操作的结果。如果数据集中有任何缺失值,那么我们也可以毫无问题地执行一些任务。
# Adding something with missing value
1 + missing
# Subtract something with missing value
1 - missing
# Multiply something with missing value
2 * missing
# Round-off missing value
round(missing)
# Taking cosine of missing value
cos(missing)
输出:
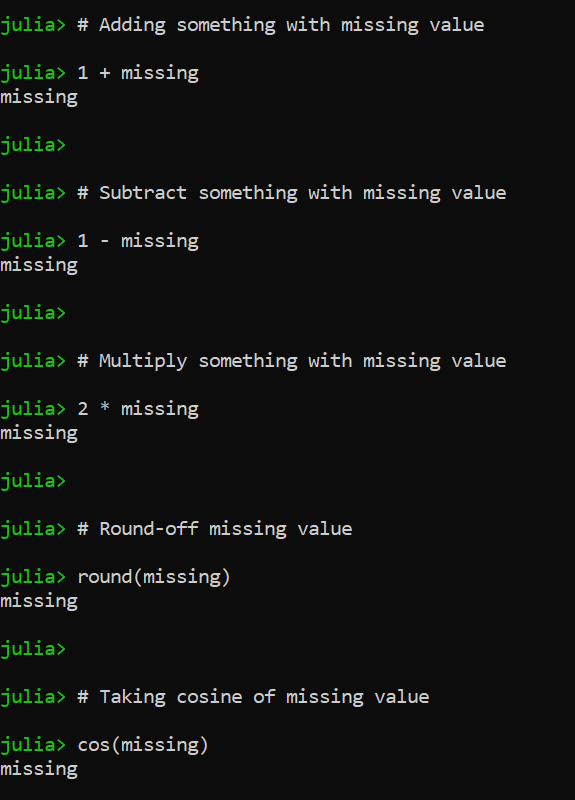
正如您所看到的,通过使用缺失的框架,我们发现对缺失对象的任何操作都不会影响结果,而如果我们对 NA 或 NAN 值执行相同的操作,它可能会返回错误或某些类型的异常。
为了摆脱这些丢失的对象,我们可以使用一个称为skipmissing()方法的便利函数。这可以帮助我们使用数据框或数组中的其他值。
# Sum the values of array ignoring missing
sum(skipmissing([1, missing, 5]))
# Mean of values of array ignoring missing
mean(skipmissing([4, missing, 3]))
输出:

处理缺失数据的方法
处理缺失值的方法有很多,下面给出了其中的一些:
从数据框中删除缺失值
在这个方法中,我们可以看到通过使用dropmissing()方法,我们能够删除数据框中缺失值的行。删除缺失值对于那些大到足以错过一些不会影响预测的数据的数据集是好的,对于小数据集则不好,它可能会导致模型拟合不足。
# Install DataFrames and Missings
using Pkg
Pkg.add('DataFrames')
Pkg.add('Missings')
# Defining DataFrame having missing values
df = DataFrame(i = 1:6,
x = [5, missing, 4, missing, 2, 1],
y = ["a", missing, missing, "c", "d", "e"])
# Droping missing data values
gfg = dropmissing(df)
print(gfg)
输出:

跳过数据框中的缺失值
在这个方法中,我们可以看到通过使用skipmissing()方法,我们能够跳过缺失值。删除缺失值是一个更好的选择,至少我们可以在该行中拥有其他值,这些值可以作为制作模型的有用数据。
# Install DataFrames and Missings
using Pkg
Pkg.add('DataFrames')
Pkg.add('Missings')
# Defining DataFrame having missing values
df = DataFrame(i = 1:6,
x = [5, missing, 4, missing, 2, 1],
y = ["a", missing, missing, "c", "d", "e"])
# Skipping missing data values
gfg = skipmissing(df[2])
print(maximum(df[2]))
print(maximum(gfg))
输出:
