使用Python进行 RFM 分析分析
在本文中,我们将看到使用Python进行的新近度、频率、货币价值分析。但首先,让我们简要了解 RFM 分析。
什么是 RFM 分析?
RFM 代表新近度、频率、货币价值。在业务分析中,我们经常使用这个概念将客户划分为不同的细分市场,如高价值客户、中等价值客户或低价值客户,等等。
假设我们是一家公司,我们的公司名称是 geek,我们来对我们的客户进行 RFM 分析
- 新近度:客户最近多久与我们进行过交易
- 频率:客户从我们这里订购/购买某些产品的频率
- 货币:客户从我们这里购买产品的花费是多少。
入门
加载必要的库和数据
在这里,我们将导入所需的模块(pandas、DateTime 和 NumPy),然后读取数据框中的数据。
使用的数据集: rfm
Python3
# importing necessary libraries
import pandas as pd
import datetime as dt
import numpy as np
# importing the data
df = pd.read_excel( < my excel file location > )
df.head()Python3
df_recency = df.groupby(by='Customer Name',
as_index=False)['Order Date'].max()
df_recency.columns = ['CustomerName', 'LastPurchaseDate']
recent_date = df_recency['LastPurchaseDate'].max()
df_recency['Recency'] = df_recency['LastPurchaseDate'].apply(
lambda x: (recent_date - x).days)
df_recency.head()Python3
frequency_df = df.drop_duplicates().groupby(
by=['Customer Name'], as_index=False)['Order Date'].count()
frequency_df.columns = ['CustomerName', 'Frequency']
frequency_df.head()Python3
df['Total'] = df['Sales']*df['Quantity']
monetary_df = df.groupby(by='Customer Name', as_index=False)['Total'].sum()
monetary_df.columns = ['CustomerName', 'Monetary']
monetary_df.head()Python3
rf_df = df_recency.merge(frequency_df, on='CustomerName')
rfm_df = rf_df.merge(monetary_df, on='CustomerName').drop(
columns='LastPurchaseDate')
rfm_df.head()Python3
rfm_df['R_rank'] = rfm_df['Recency'].rank(ascending=False)
rfm_df['F_rank'] = rfm_df['Frequency'].rank(ascending=True)
rfm_df['M_rank'] = rfm_df['Monetary'].rank(ascending=True)
# normalizing the rank of the customers
rfm_df['R_rank_norm'] = (rfm_df['R_rank']/rfm_df['R_rank'].max())*100
rfm_df['F_rank_norm'] = (rfm_df['F_rank']/rfm_df['F_rank'].max())*100
rfm_df['M_rank_norm'] = (rfm_df['F_rank']/rfm_df['M_rank'].max())*100
rfm_df.drop(columns=['R_rank', 'F_rank', 'M_rank'], inplace=True)
rfm_df.head()Python3
rfm_df['RFM_Score'] = 0.15*rfm_df['R_rank_norm']+0.28 * \
rfm_df['F_rank_norm']+0.57*rfm_df['M_rank_norm']
rfm_df['RFM_Score'] *= 0.05
rfm_df = rfm_df.round(2)
rfm_df[['CustomerName', 'RFM_Score']].head(7)Python3
rfm_df["Customer_segment"] = np.where(rfm_df['RFM_Score'] >
4.5, "Top Customers",
(np.where(
rfm_df['RFM_Score'] > 4,
"High value Customer",
(np.where(
rfm_df['RFM_Score'] > 3,
"Medium Value Customer",
np.where(rfm_df['RFM_Score'] > 1.6,
'Low Value Customers', 'Lost Customers'))))))
rfm_df[['CustomerName', 'RFM_Score', 'Customer_segment']].head(20)Python3
plt.pie(rfm_df.Customer_segment.value_counts(),
labels=rfm_df.Customer_segment.value_counts().index,
autopct='%.0f%%')
plt.show()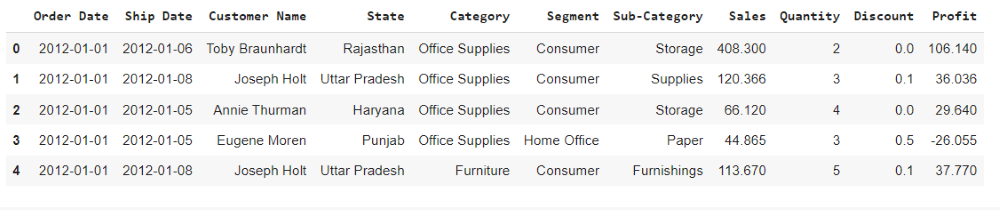
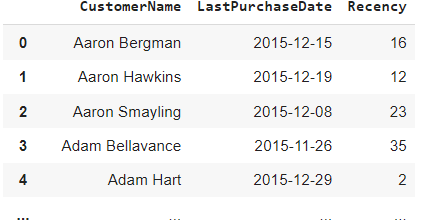
计算新近度
在这里,我们正在计算与公司进行购买的客户的新近度。
Python3
df_recency = df.groupby(by='Customer Name',
as_index=False)['Order Date'].max()
df_recency.columns = ['CustomerName', 'LastPurchaseDate']
recent_date = df_recency['LastPurchaseDate'].max()
df_recency['Recency'] = df_recency['LastPurchaseDate'].apply(
lambda x: (recent_date - x).days)
df_recency.head()
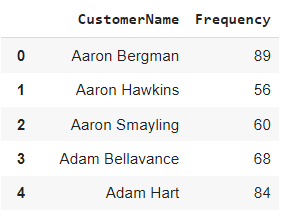
计算频率
我们在这里计算客户从公司订购/购买某些产品的频繁交易频率。
Python3
frequency_df = df.drop_duplicates().groupby(
by=['Customer Name'], as_index=False)['Order Date'].count()
frequency_df.columns = ['CustomerName', 'Frequency']
frequency_df.head()
计算货币价值
在这里,我们正在计算客户从公司购买产品所花费的货币价值。
Python3
df['Total'] = df['Sales']*df['Quantity']
monetary_df = df.groupby(by='Customer Name', as_index=False)['Total'].sum()
monetary_df.columns = ['CustomerName', 'Monetary']
monetary_df.head()
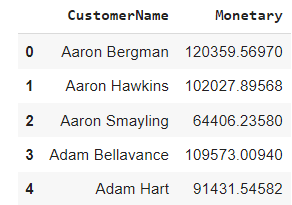
将所有三列合并到一个数据框中
在这里,我们使用合并函数合并单个实体中的所有数据框列,以显示新近度、频率、货币值。
Python3
rf_df = df_recency.merge(frequency_df, on='CustomerName')
rfm_df = rf_df.merge(monetary_df, on='CustomerName').drop(
columns='LastPurchaseDate')
rfm_df.head()
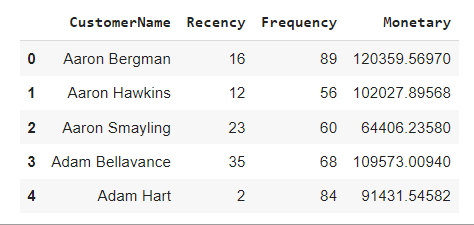
根据客户的新近度、频率和货币分数对客户进行排名
在这里,我们将公司内客户的排名标准化以分析排名。
Python3
rfm_df['R_rank'] = rfm_df['Recency'].rank(ascending=False)
rfm_df['F_rank'] = rfm_df['Frequency'].rank(ascending=True)
rfm_df['M_rank'] = rfm_df['Monetary'].rank(ascending=True)
# normalizing the rank of the customers
rfm_df['R_rank_norm'] = (rfm_df['R_rank']/rfm_df['R_rank'].max())*100
rfm_df['F_rank_norm'] = (rfm_df['F_rank']/rfm_df['F_rank'].max())*100
rfm_df['M_rank_norm'] = (rfm_df['F_rank']/rfm_df['M_rank'].max())*100
rfm_df.drop(columns=['R_rank', 'F_rank', 'M_rank'], inplace=True)
rfm_df.head()
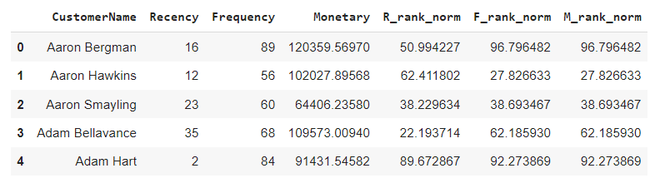
计算 RFM 分数
RFM 分数是根据新近度、频率、货币价值标准化排名计算的。根据这个分数,我们划分我们的客户。在这里,我们以 5 分对它们进行评分。用于计算 rfm 分数的公式为:0.15*Recency score + 0.28*Frequency score + 0.57 *Monetary score
Python3
rfm_df['RFM_Score'] = 0.15*rfm_df['R_rank_norm']+0.28 * \
rfm_df['F_rank_norm']+0.57*rfm_df['M_rank_norm']
rfm_df['RFM_Score'] *= 0.05
rfm_df = rfm_df.round(2)
rfm_df[['CustomerName', 'RFM_Score']].head(7)
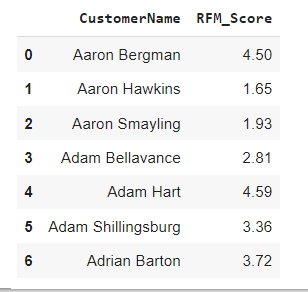
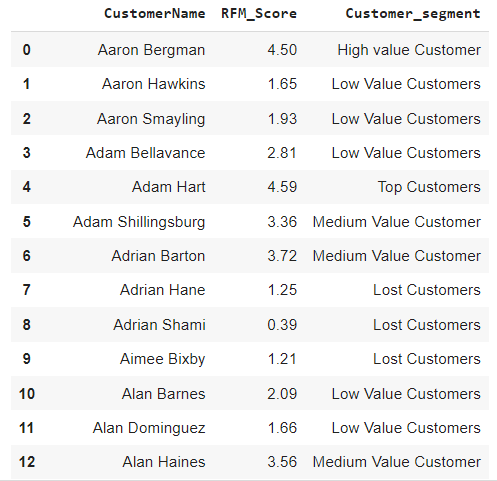
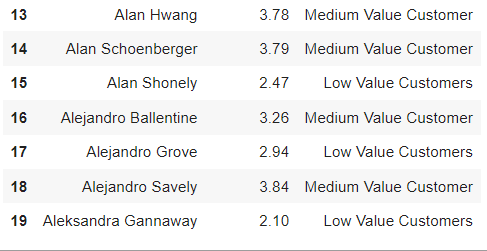
根据 RFM 分数对客户进行评级
- rfm 得分 >4.5:顶级客户
- 4.5 > rfm score > 4 : 高价值客户
- 4>rfm score >3 : 中等价值客户
- 3>rfm score>1.6:低价值客户
- rfm score<1.6:失去客户
Python3
rfm_df["Customer_segment"] = np.where(rfm_df['RFM_Score'] >
4.5, "Top Customers",
(np.where(
rfm_df['RFM_Score'] > 4,
"High value Customer",
(np.where(
rfm_df['RFM_Score'] > 3,
"Medium Value Customer",
np.where(rfm_df['RFM_Score'] > 1.6,
'Low Value Customers', 'Lost Customers'))))))
rfm_df[['CustomerName', 'RFM_Score', 'Customer_segment']].head(20)
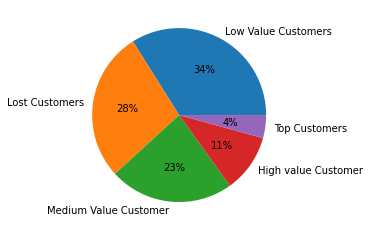
可视化客户细分
在这里,我们将使用饼图来显示所有客户群。
Python3
plt.pie(rfm_df.Customer_segment.value_counts(),
labels=rfm_df.Customer_segment.value_counts().index,
autopct='%.0f%%')
plt.show()