使用 Turicreate 进行文本分析
什么是文本分析?
文本是一组单词或句子。文本分析是分析文本,然后借助文本提取信息。文本数据是可以使公司变大或变小的最大因素之一。例如
- 人们在电子商务网站上买东西。通过文本分析,电子商务网站可以知道客户喜欢什么,并且通过这些数据可以提高其生产力。
- 使用文本分析和一些机器学习算法,我们的 Alexa Google Home 迷你作品。这两个基于自然语言处理。
- 使用文本分析,我们可以确定电子邮件是垃圾邮件还是非垃圾邮件。
文本分析可以使用文本挖掘来完成。因为文本“数据”可以是结构化的也可以是非结构化的。文本挖掘技术将帮助我们区分它们。
现在让我们使用 Turicreate 进行一些文本分析。我们将构建一个模型,将消息分类为垃圾邮件或非垃圾邮件以进行文本分析。数据集的链接=https://www.kaggle.com/team-ai/spam-text -消息分类
第 1 步:导入 Turicreate 库
python3
import turicreate as tcpython3
data = tc.SFrame("data.csv")
Step 3: We will explore the data first.python3
# It will print the first full rows of the data
data.head().python3
# Text analytics library has a count word function.
# It will separately count the words for each row
# of message column.
data['word_count']= tc.text_analytics.count_words(data['Message'])
# now we can see that the data has one more column if word_count.
data.head()python3
train_data, test_data = data.random_split(.8, seed = 0)python3
# We will use our feature as word count and
# our target "category is to find out spam or ham.
model = tc.logistic_classifier.create(
train_data, target ='Category',
features =['word_count'],
validation_set = test_data)python3
model.evaluate(test_data)python3
test_data.head()
# We will select the first one that is spam
# and select that is spam or not.python3
model.predict(test_data[1])第二步:加载数据集。
蟒蛇3
data = tc.SFrame("data.csv")
第 3 步:我们将首先探索数据。
蟒蛇3
# It will print the first full rows of the data
data.head().
Output: 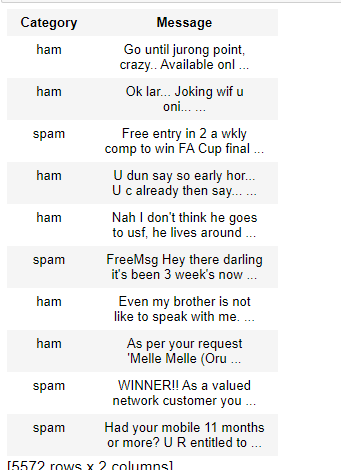
数据集
第 4 步:现在在数据集中添加字数。
这是因为数据有两个东西类别和消息。添加字数将有助于模型特征选择。
蟒蛇3
# Text analytics library has a count word function.
# It will separately count the words for each row
# of message column.
data['word_count']= tc.text_analytics.count_words(data['Message'])
# now we can see that the data has one more column if word_count.
data.head()
输出:
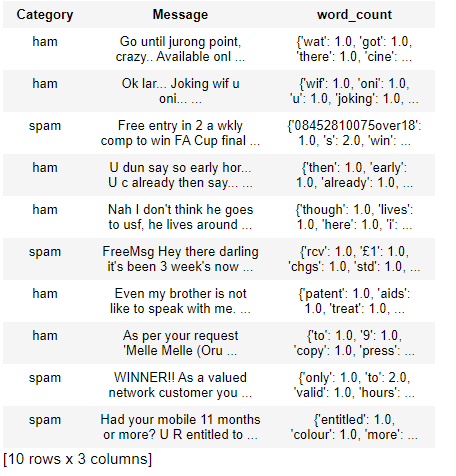
这里数据集中又增加了一行 word_count。
第 5 步:将数据拆分为训练集和测试集。
蟒蛇3
train_data, test_data = data.random_split(.8, seed = 0)
第 6 步:现在我们将建立一个模型来对垃圾邮件和火腿进行分类。
蟒蛇3
# We will use our feature as word count and
# our target "category is to find out spam or ham.
model = tc.logistic_classifier.create(
train_data, target ='Category',
features =['word_count'],
validation_set = test_data)
第 7 步:现在我们将检查模型的准确性。
蟒蛇3
model.evaluate(test_data)
输出:
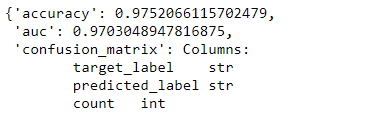
准确度为 0.975,即 97.5%。第 8 步:我们可以通过从我们的测试数据中检查它是否给出正确答案来手动预测。
代码:
蟒蛇3
test_data.head()
# We will select the first one that is spam
# and select that is spam or not.
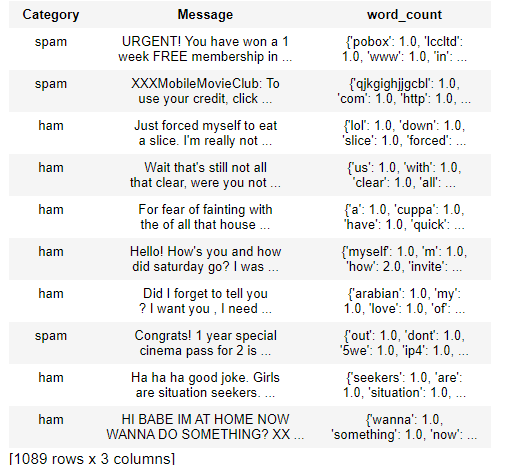
第 9 步:预测测试数据。
蟒蛇3
model.predict(test_data[1])
输出:
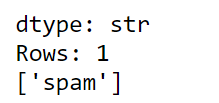
结果是垃圾邮件,因此模型预测正确。