Scrapy - 命令行工具
先决条件:使用 Scrapy 在Python实现 Web Scraping
Scrapy 是一个Python库,用于网络抓取和搜索整个网络的内容。它使用爬行整个页面的蜘蛛来找出选择器中指定的内容。因此,它是一个非常方便的工具,可以使用不同的选择器提取网页的所有内容。
在 Scrapy 中创建一个蜘蛛并让它爬行有两种方法,我们可以创建一个包含文件和文件夹的目录,并在其中一个文件中编写一些代码并执行搜索命令,或者我们可以通过以下方式与蜘蛛进行交互scrapy 的命令行 shell。所以要在shell中进行交互,我们应该熟悉scrapy的命令行工具。
Scrapy 命令行工具提供了可用于各种目的的各种命令。让我们一一研究每个命令。
创建 Scrapy 项目
首先,确保您的系统上安装了Python 。然后创建一个虚拟环境。
例子:

检查Python并为 scrapy 目录创建 Virtualenv。
我们正在使用虚拟环境来节省内存,因为我们将如此大的包全局下载到我们的系统中,然后它会消耗大量内存,而且我们不会大量需要这个包,直到您专注于继续它.
要激活刚刚创建的虚拟环境,我们必须先进入Scripts文件夹,然后运行 activate 命令
cd Scripts
activate
cd..
例子:

激活虚拟环境
然后我们必须运行下面给出的命令来从 pip 安装scrapy,然后运行下一个命令来创建名为GFGScrapy的scrapy项目。
# This is the command to install scrapy in virtual env. created above
pip install scrapy
# This is the command to start a scrapy project.
scrapy startproject GFGScrapy
例子:

创建scrapy项目
现在我们要在scrapy中创建一个蜘蛛。对于那个蜘蛛,我们应该输入我们想要抓取的站点的 URL。

目录结构
# change the directory to that where the scrapy project is made.
cd GFGScrapy
# input the URL
scrapy genspider spiderman https://quotes.toscrape.com/
因此,我们创建了一个可在上述站点上爬行的爬虫蜘蛛。
例子:

创建蜘蛛
要查看 scrapy 中可用工具的列表或有关它的任何帮助,请键入以下命令。
句法:
scrapy -h
如果我们想要任何特定命令的更多描述,请键入给定的命令。
句法:
scrapy
例子:

这些是scrapy中使用的命令行工具列表
下面讨论了命令及其应用程序的列表:
- bench:该命令用于执行基准测试,表示scrapy软件是否可以在给定的系统环境下运行。
句法:
scrapy bench
- check:检查蜘蛛合约。
句法:
scrapy check [options]
例子:
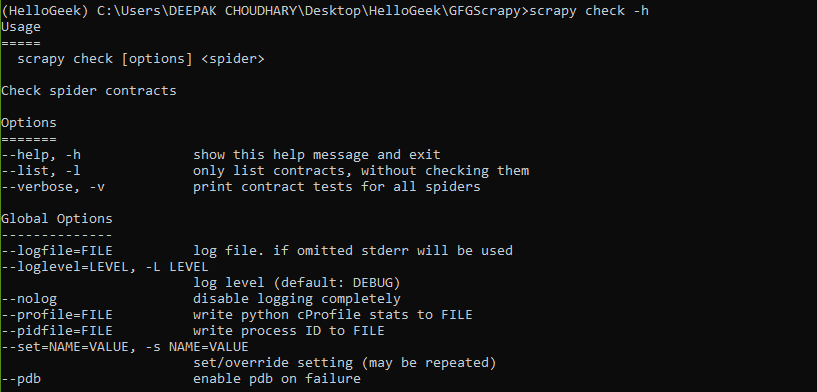
Scrapy 检查命令
- crawl:该命令用于通过指定的 URL 抓取蜘蛛并分别收集数据。
句法:
scrapy crawl spiderman
例子:

蜘蛛在网页中爬行
- edit 和 genspider:这两个命令分别用于修改现有蜘蛛或创建新蜘蛛,
- version 和view:这些命令分别返回scrapy 的版本和蜘蛛看到的站点的URL。
句法:
scrapy -version
此命令打开一个新选项卡,其中包含保存指定 URL 数据的 HTML 文件的 URL 名称,
句法:
scrapy view [url]
例子:

版本检查
- 列表、解析和设置:顾名思义,它们用于创建可用蜘蛛的列表,解析提到的蜘蛛的 URL,并分别在 settings.py 文件中设置值。
自定义命令
除了所有这些默认存在的命令行工具之外,scrapy 还为用户提供了创建自己的自定义工具的能力,如下所述:
在 settings.py 文件中,我们可以选择在名为COMMANDS_MODULE的标题下添加自定义工具。
句法 :
COMMAND_MODULES = ‘spiderman.commands’
格式为
- 首先,创建一个命令文件夹,该文件夹与 settings.py 文件所在的目录相同。
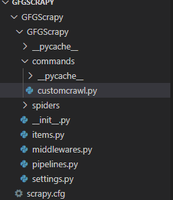
目录结构
- 接下来,我们将在名为customcrawl.py文件的命令文件夹中创建一个 .py 文件,该文件用于编写我们的命令将执行的工作。这里命令的名称是scrapy customcrawl。在这个文件中,我们将使用一个名为Command的类,它继承自ScrapyCommand并包含三个用于创建命令的方法。
程序:
Python3
from scrapy.commands import ScrapyCommand
class Command(ScrapyCommand):
# requires the use of project
requires_project = True
# syntax for command
def syntax(self):
return '[options]'
# description of command
def short_desc(self):
return 'Runs the spider using custom command'
# the main running command
def run(self, args, opts):
# derieves to spider of scrapy project
spider = self.crawler_process.spiders.list()
# calls crawl command for that particular spider
self.crawler_process.crawl(spider[0], **opts.__dict__)
# starts the crawl
self.crawler_process.start()- 从现在开始,我们已经在其中创建了一个命令文件夹和一个 customcrawl.py 文件,现在是时候通过 settings.py 文件提供对该命令的 scrapy 访问权限了。
所以在 settings.py 文件下提到一个名为COMMANDS_MODULE的标题并添加命令文件夹的名称,如下所示:

设置.py文件
- 现在是时候查看输出了
句法:
scrapy custom_command_file_name
例子:

我们的自定义命令运行成功
因此,我们看到了如何定义自定义命令并使用它而不是使用默认命令。我们还可以向库中添加命令,并在scrapy中的setup.py文件下的部分中导入它们。