DeepWalk 算法
图数据结构:
在现实世界中,网络只是互连节点的集合。为了表示这种类型的网络,我们需要一个与之类似的数据结构。幸运的是,我们有一个数据结构,即图。
该图包含由边(可以表示互连 b/w 节点)连接的顶点(表示网络中的节点)
深度行走:
深度游走是一种为学习网络中顶点的潜在表示而提出的算法。这些潜在表示用于表示黑白两个图的社会表示。它使用随机路径遍历技术来深入了解网络内的局部结构。它通过将这些随机路径用作序列来实现,然后将其用于训练 Skip-Gram 语言模型。
Skip-Gram 模型用于通过最大化句子中窗口 w 内出现的单词之间的共现概率来预测句子中的下一个单词。对于我们的实现,我们将使用 Word2Vec 实现,它使用余弦距离来计算概率。
Deepwalk 过程分为几个步骤:
- 随机游走生成器采用图 G 并均匀采样一个随机顶点 v i作为随机游走W vi的根。从最后访问的顶点的邻居中均匀地步行样本,直到达到最大长度 (t)。
- Skip-gram 模型在出现在窗口 w 内的随机游走中迭代所有可能的搭配。对于每个,我们将每个顶点vj映射到其当前表示向量Φ(vj ) ∈ R d。
- 给定vj的表示,我们希望在步行中最大化其邻居的概率(第 3 行)。我们可以使用多种分类器选择来学习这种后验分布
随机游走
给定一个无向图G = (V, E) ,其中n =| V |和m =| E|,自然随机游走是一个随机过程,它从给定的顶点开始,然后均匀地随机选择其邻居之一进行访问。
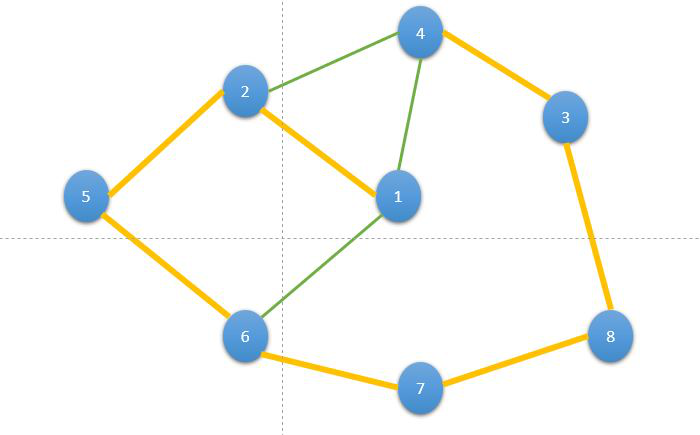
- 在上图中,从 1 我们有两个节点 2 和 4。从中,我们选择其中任何一个,让我们选择 2。
- 现在,从 2 中,我们有两个选择 4 和 5,我们从中随机选择 5。所以我们的随机游走变成了 Node 1 → 2 → 5 。
- 一遍又一遍地重复上面的过程,直到我们覆盖了图中的所有节点。这个过程被称为随机游走。一种这样的随机游走是 1 → 2 → 5 → 6 → 7 → 8 → 3 → 4 。
Skip-Gram 模型
Word Embeddings 是一种将单词映射到固定大小的特征向量的方法,使单词的处理更加容易。 2013 年,Google 提出了 word2vec,一组用于产生词嵌入的相关模型。在word2vec 的 skip-gram架构中,输入是中心词,预测是上下文词。考虑一个词数组 W,如果 W(i) 是输入(中心词),那么W(i-2)、W(i-1)、W(i+1) 和 W(i+2)是如果滑动窗口大小为 2,则为上下文词。
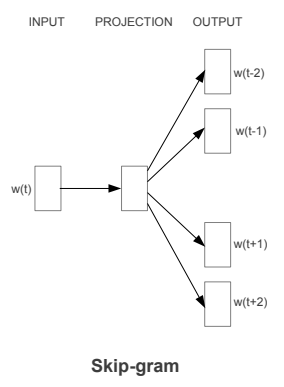
下面是skip-gram模型的模板架构:

好处:
- Deepwalk 是可扩展的,因为它一次处理整个图。这允许深度游走创建可能无法在频谱算法上运行的大图的有意义的表示。
- 在处理稀疏性时,与其他算法相比,Deepwalk 更快。
- Deepwalk 可用于许多目的,例如异常检测、聚类、链接预测等。
执行
- 在这个实现中,我们将使用networkx和karateclub API。出于我们的目的,我们将使用带有自聚类的图嵌入:Facebook 数据集。数据集可以从这里下载
Python3
# Install karateclub API
! pip install karateclub
# imports
import networkx as nx
import pandas as pd
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from karateclub import DeepWalk
# import dataset
df = pd.read_csv("/content/politician_edges.csv")
df.head()
# create Graph
G = nx.from_pandas_edgelist(df, "node_1", "node_2", create_using=nx.Graph())
print(len(G))
# train model and generate embedding
model = DeepWalk(walk_length=100, dimensions=64, window_size=5)
model.fit(G)
embedding = model.get_embedding()
# print Embedding shape
print(embedding.shape)
# take first 100 nodes
nodes =list(range(100))
# plot nodes graph
def plot_nodes(node_no):
X = embedding[node_no]
pca = PCA(n_components=2)
pca_out= pca.fit_transform(X)
plt.figure(figsize=(15,10))
plt.scatter(pca_out[:, 0], pca_out[:, 1])
for i, node in enumerate(node_no):
plt.annotate(node, (pca_out[i, 0], pca_out[i, 1]))
plt.xlabel('Label_1')
plt.ylabel('label_2')
plt.show()
plot_nodes(nodes)输出:
node_1 node_2
0 0 1972
1 0 5111
2 0 138
3 0 3053
4 0 1473
-------------
# length of nodes
5908
-------------
# embedding shape
(5908, 64)
节点图
参考:
- 深行