Python的Vaex 介绍
处理大数据在今天变得非常普遍,因此我们需要一些库来帮助我们处理来自我们系统(即台式机、笔记本电脑)的大数据,同时即时执行代码和低内存使用率。
Vaex是一个Python库,它帮助我们实现这一目标并使处理大型数据集变得非常容易。它特别适用于懒惰的核心外数据帧(类似于 Pandas)。它可以快速地对大型表格数据集进行可视化、探索和计算,并且占用的内存最少。
安装:
使用康达:
conda install -c conda-forge vaex使用点子:
pip install --upgrade vaex为什么是 Vaex?
Vaex 通过惰性计算、虚拟列、内存映射、零内存复制策略、高效的数据清理等帮助我们高效快速地处理大型数据集。 Vaex 具有高效的算法,它强调聚合数据属性而不是查看单个样本。它能够克服其他库的几个缺点(例如:-pandas)。所以,让我们探索 Vaex:-
阅读表现
对于大型表格数据,Vaex 的读取性能比 Pandas 快很多。让我们通过使用两个库导入相同大小的数据集来进行分析。数据集链接
Pandas 的阅读性能:
Python3
import pandas as pd
%time df_pandas = pd.read_csv("dataset1.csv")Python3
import vaex
%time df_vaex = vaex.open("dataset1.csv.hdf5")Python3
print("Size =")
print(df_pandas.shape)
print(df_vaex.shape)Python3
%time df_pandas['column2'] + df_pandas['column3']Python3
%time df_vaex.column2 + df_vaex.column3Python3
%time df_pandas["column3"].mean()Python3
%time df_vaex.mean(df_vaex.column3)Python3
%time df_pandas_filtered = df_pandas[df_pandas['column5'] > 1]Python3
%time df_vaex_filtered = df_vaex[df_vaex['column5'] > 1]Python3
df_vaex.select(df_vaex.column4 < 20,
name='less_than')
df_vaex.select(df_vaex.column4 >= 20,
name='gr_than')
%time df_vaex.mean(df_vaex.column4,
selection=['less_than', 'gr_than'])Python3
%time df_vaex['new_col'] = df_vaex['column3']**2
df_vaex.mean(df_vaex['new_col'])Python3
%time df_vaex.count(binby=df_vaex.column7,
limits=[0, 20], shape=10)Python3
%time df_vaex.viz.histogram(df_vaex.column1,
limits = [0, 20])Python
df_vaex.viz.heatmap(df_vaex.column7, df_vaex.column8 +
df_vaex.column9, limits=[-3, 20])Python3
df_vaex.viz.heatmap(df_vaex.column1, df_vaex.column2,
what=(vaex.stat.mean(df_vaex.column4) /
vaex.stat.std(df_vaex.column4)),
limits='99.7%')输出:
Wall time: 1min 8sVaex 的读取性能:(我们使用 vaex.open 在 Vaex 中读取数据集)
蟒蛇3
import vaex
%time df_vaex = vaex.open("dataset1.csv.hdf5")
输出:
Wall time: 1.34 s与 Pandas 相比,Vaex 读取相同大小的数据集花费的时间很少:
蟒蛇3
print("Size =")
print(df_pandas.shape)
print(df_vaex.shape)
输出:
Size =
12852000, 36
12852000, 36Vaex 懒惰地进行计算
Vaex 使用惰性计算技术(即在不浪费 RAM 的情况下即时计算)。在这种技术中,Vaex 不做完整的计算,而是创建一个 Vaex 表达式,并在打印出来时显示一些预览值。因此 Vaex 仅在需要时才执行计算,否则它会存储表达式。这使得 Vaex 的计算速度异常的快。让我们执行一个简单计算的例子:
熊猫数据帧:
蟒蛇3
%time df_pandas['column2'] + df_pandas['column3']
输出:

Vaex 数据帧:
蟒蛇3
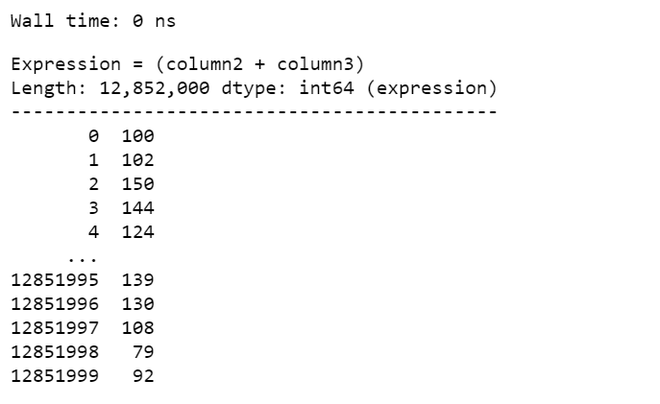
%time df_vaex.column2 + df_vaex.column3
输出:
统计性能:
Vaex 可以在每秒高达十亿 (10 9 ) 个对象/行的 N 维网格上计算诸如平均值、总和、计数、标准偏差等统计数据。因此,让我们在计算统计数据时比较 pandas 和 Vaex 的性能:-
熊猫数据框:
蟒蛇3
%time df_pandas["column3"].mean()
输出:
Wall time: 741 ms
49.49811570183629Vaex 数据框:
蟒蛇3
%time df_vaex.mean(df_vaex.column3)
输出:
Wall time: 347 ms
array(49.4981157)Vaex 遵循零内存复制策略
与 Pandas 不同,Vaex 在数据过滤、选择、子集、清理过程中不会创建内存副本。让我们以数据过滤为例,在实现此任务时,Vaex 使用的内存非常少,因为 Vaex 中没有进行内存复制。并且执行的时间也是最少的。
熊猫:
蟒蛇3
%time df_pandas_filtered = df_pandas[df_pandas['column5'] > 1]
输出:
Wall time: 24.1 s瓦克斯:
蟒蛇3
%time df_vaex_filtered = df_vaex[df_vaex['column5'] > 1]
输出:
Wall time: 91.4 ms这里数据过滤导致对现有数据的引用,带有布尔掩码,该掩码跟踪选定行和非选定行。 Vaex 对数据执行多次计算:-
蟒蛇3
df_vaex.select(df_vaex.column4 < 20,
name='less_than')
df_vaex.select(df_vaex.column4 >= 20,
name='gr_than')
%time df_vaex.mean(df_vaex.column4,
selection=['less_than', 'gr_than'])
输出:
Wall time: 128 ms
array([ 9.4940431, 59.49137605])Vaex 中的虚拟列
当我们通过向 DataFrame 添加表达式来创建新列时,会创建虚拟列。这些列就像普通列一样,但不占用内存,只存储定义它们的表达式。这使得任务非常快并减少了 RAM 的浪费。 Vaex 不区分常规列和虚拟列。
蟒蛇3
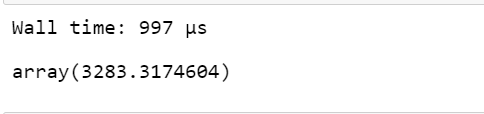
%time df_vaex['new_col'] = df_vaex['column3']**2
df_vaex.mean(df_vaex['new_col'])
输出:
Vaex 中的分箱统计:
Vaex 为 Pandas 的 groupby 提供了一种更快的替代方案,即“binby”,它可以在常规 bin 中快速计算常规 N 维网格的统计数据。
蟒蛇3
%time df_vaex.count(binby=df_vaex.column7,
limits=[0, 20], shape=10)
输出:

Vaex 中的快速可视化:
大型数据集的可视化是一项乏味的任务。但是 Vaex 可以非常快速地计算这些可视化。当在 bin 中计算时,该数据集可以更好地了解数据分布,而 Vaex 在组聚合属性、选择和 bin 方面表现出色。因此,Vaex 能够快速且交互式地进行可视化。通过 Vaex,即使在大型数据集的 3 维中也可以进行可视化。
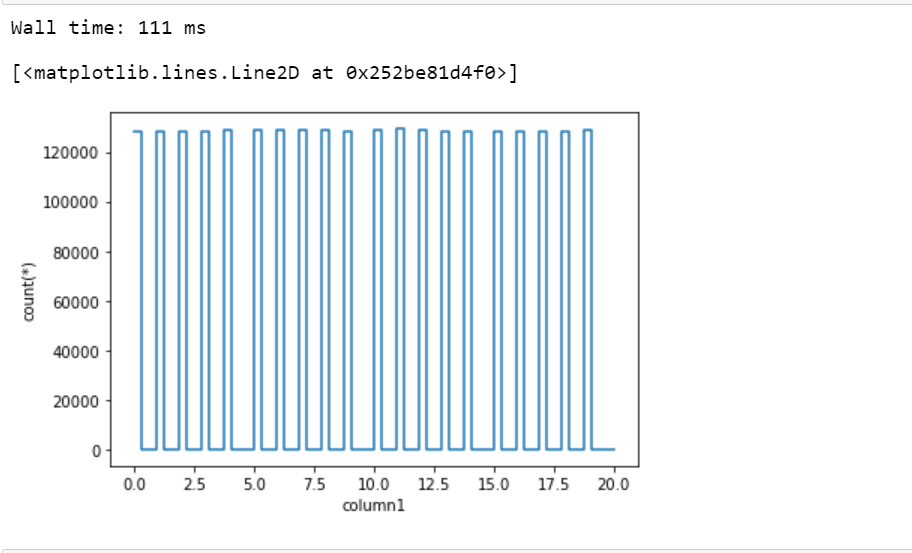
让我们绘制一个简单的一维图:
蟒蛇3
%time df_vaex.viz.histogram(df_vaex.column1,
limits = [0, 20])
输出:
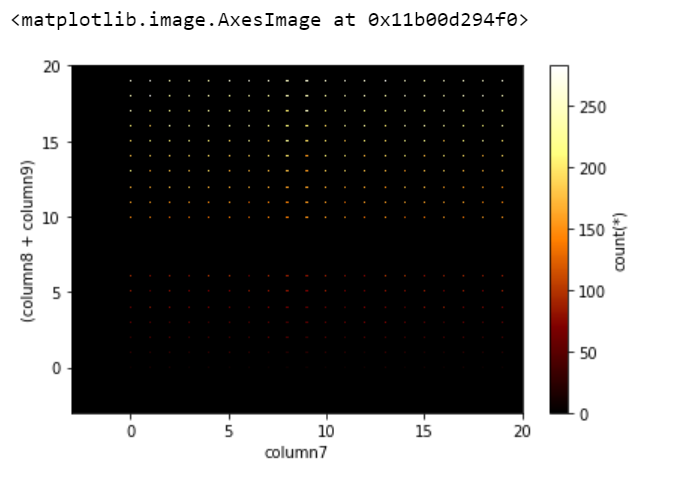
让我们绘制一个二维热图:
Python
df_vaex.viz.heatmap(df_vaex.column7, df_vaex.column8 +
df_vaex.column9, limits=[-3, 20])
输出:
我们可以通过传递“what=
蟒蛇3
df_vaex.viz.heatmap(df_vaex.column1, df_vaex.column2,
what=(vaex.stat.mean(df_vaex.column4) /
vaex.stat.std(df_vaex.column4)),
limits='99.7%')
输出:
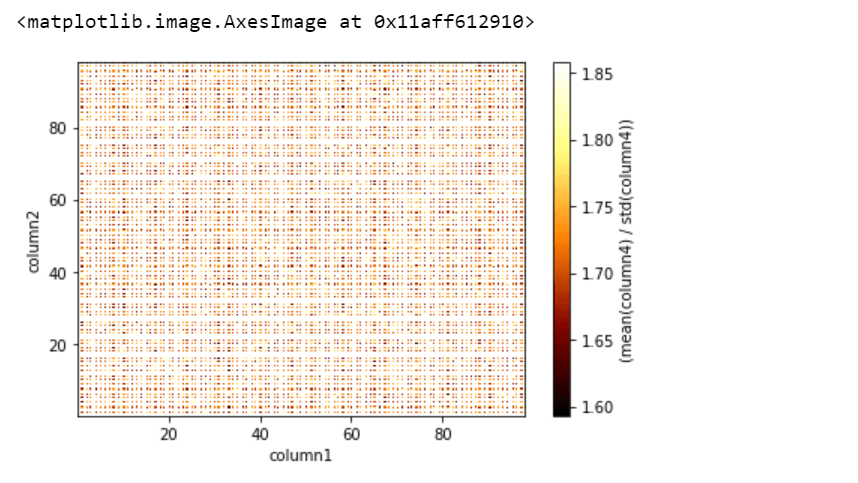
在这里,'vaex.stat.