Julia 中的可视化
数据可视化是以图表方式表示可用数据的过程。可以安装一些软件包以使用Python和 Julia 等语言可视化数据。下面列出了使数据可视化变得重要的一些原因:
- 可以轻松分析更大的数据。
- 可以发现趋势和模式。
- 可以轻松地从可视化中完成解释
Julia 中的可视化包
与 Julia 一起广泛使用的包是Plots.jl 。但是,它是一个可用于绘图的元包。这个包解释了给出的命令,并使用其他一些库生成了图,这些库被称为backend 。 Julia 中可用的后端库有:
- Plotly/PlotlyJS
- PyPlot
- PGFPlotsX
- Unicode 绘图
- 检查DR
- HDF5
可以单独使用这些 Plots.jl 制作绘图。为此,必须安装该软件包。打开 Julia 终端并输入以下命令:
Pkg.add(“Plots”)
后端软件包也可以以相同的方式安装。本文展示了如何使用 Plots.jl 为两个数字向量和两个不同的数据集绘制数据。要使用数据集,必须安装RDatasets和CSV等软件包。下面给出了用于安装的命令。
Pkg.add(“RDatasets”)
Pkg.add(“CSV”)
线图
可以使用简单的线图绘制一维向量。线图需要两个轴(x 和 y)。例如,考虑一个具有从 1 到 10 的值的向量,它形成了 x 轴。使用rand() ,已生成十个随机值并形成 y 轴。绘图可以使用plot()函数完成,如下所示。
Julia
# generating vectors
# x-axis
x = 1:10
# y-axis
y = rand(10)
# simple plotting
plot(x, y)Julia
# x-axis
x = 1:10
# y-axis
y = rand(10)
# styling the graph
plot(x, y, linecolor =:green,
bg_inside =:pink,
line =:solid, label = "Y")Julia
# another vector in y-axis
z = rand(10)
# to plot on previous graph
plot!(z, linecolor =:red,
line =:dashdot,
labels = "Z")Julia
# loading the dataset
using RDatasets
cars = dataset("datasets", "mtcars")
# plotting bar graph
bar(cars.Model,
cars.MPG,
label = "Miles/Gallon",
title = "Models and Miles/Gallon",
xticks =:all,
xrotation = 45,
size = [600, 400],
legend =:topleft)Julia
bar(cars.Model,
[cars.MPG,cars.QSec], # plotting two attributes
label = ["Miles/Gallon" "QSec"],
title = "Models-Miles/Gallon and Qsec",
xrotation = 45,
size = [600, 400],
legend =:topleft,
xticks =:all,
yticks =0:35)Julia
# importing package
using RDatasets
# loading dataets
cars = dataset("datasets", "mtcars")
# 3-dimensions plotting
plot(cars.Gear, # x-axis
cars.Disp, # yaxis
cars.HP, # z-axis
title = "3-dimensional plot",
xlabel = "no.of.gears",
ylabel = "displacement",
zlabel = "HP")Julia
# import packages
using DataFrames
using CSV
# loading dataset
df = CSV.read("path\\pima-indians-diabetes.csv");
# scatter plot
scatter(df.age, # x-axis
df.dpf, # y-axis
xticks = 20:90,
xrotation = 90,
label = "dpf",
title = "Age and Diabetes Pedigree Function")Julia
# import packages
using DataFrames
using CSV
# loading dataset
# semicolon at the end
# prevents printing
df = CSV.read("path\\pima-indians-diabetes.csv");
# plot histogram
histogram(df.age,
bg_inside = "black",
title = "Frequency of age groups",
label = "Age"
xlabel = "age",
ylabel = "freq",
xticks = 20:85,
xrotation = 90)Julia
using DataFrames
using CSV
# load dataset
df = CSV.read("path\\pima-indians-diabetes.csv");
# dataframe to get counts
axis = DataFrame()
axis = by(df, :outcome, nrow)
println(axis)
# dataframe to form
# x-axis and y-axis
items = DataFrame()
# x-axis
items[:x] = ["Diabetic", "Non-Diabetic"]
# y-axis (count)
items[:y] = axis.nrow
pie(items.x, items.y)输出:
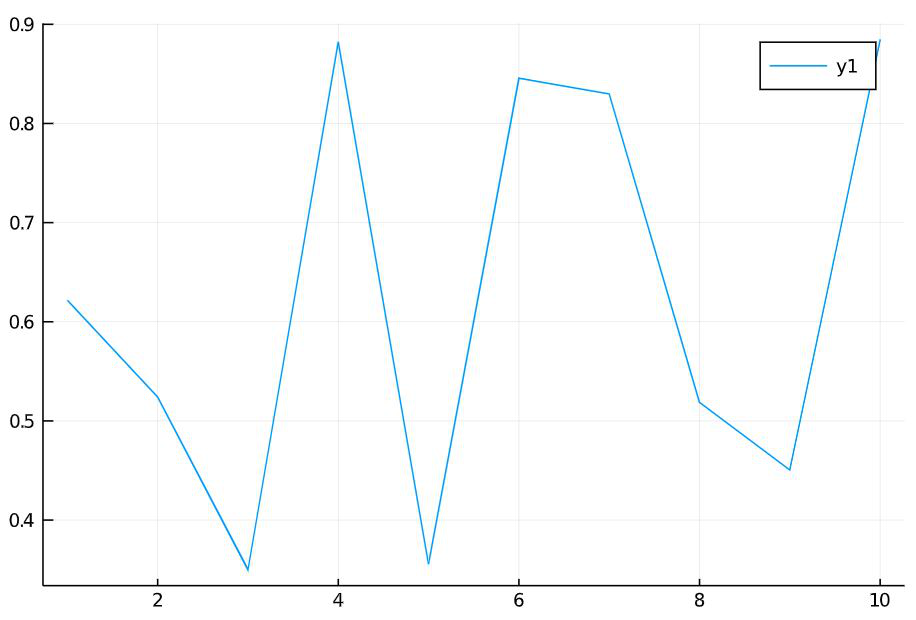
可以使用各种属性对图表进行样式化。下面的例子解释了一些属性:
朱莉娅
# x-axis
x = 1:10
# y-axis
y = rand(10)
# styling the graph
plot(x, y, linecolor =:green,
bg_inside =:pink,
line =:solid, label = "Y")
输出:

属性及说明
- linecolor:设置线条的颜色。颜色名称前面应该有一个冒号(':')。
- bg_inside:设置绘图的背景颜色。
- line:设置线路类型。可能的值为:solid、:dash、:dashsot、:dashdotdot
- label:为绘制的线设置标签名称。
- 标题:设置情节的标题。
在 Julia 中,可以在先前绘制的图形上绘制另一个向量。允许这个plot!()的函数。在 Jupyter notebook 中,必须先编写上一个示例的代码片段,然后才能在新单元格中编写下面给出的 on。
朱莉娅
# another vector in y-axis
z = rand(10)
# to plot on previous graph
plot!(z, linecolor =:red,
line =:dashdot,
labels = "Z")
输出 :

在这里可以找到上一张图上绘制的虚线。此处编写的样式仅适用于新线,不会影响之前绘制的线。
绘制数据集
例如,这里使用的数据集是mtcars和Prisma-Indian Diabetes数据集。为了理解每个属性,在每个示例中都将添加新属性并在其下方进行解释。但是,所有样式属性都可以用于任何绘图。 mtcars数据集包含 1973-74 年可用的 32 种汽车模型的信息。该数据集中的属性列出并解释如下:
- mpg – 英里/加仑(美国)。
- cyl – 气缸数。
- disp – 位移 (cu.in)。
- hp——总马力。
- drat – 后轴比率。
- 重量 - 重量
- qsec – 1/4 英里时间
- vs – 发动机形状,其中 0 表示 V 形,1 表示直线。
- 上午——传输。 0 表示自动,1 表示手动。
- gears – 前进档数
- carb——化油器的数量。
首先,这个数据集可以被可视化。
条形图
简单的条形图可用于比较两个事物或表示随时间的变化或表示两个项目之间的关系。现在在这个数据集中有 32 个独特的模型,它们将用作绘制条形图的 x 轴。 MPG(英里每加仑)在 y 轴上用于绘图。查看下面的代码片段及其输出。
朱莉娅
# loading the dataset
using RDatasets
cars = dataset("datasets", "mtcars")
# plotting bar graph
bar(cars.Model,
cars.MPG,
label = "Miles/Gallon",
title = "Models and Miles/Gallon",
xticks =:all,
xrotation = 45,
size = [600, 400],
legend =:topleft)
输出 :

属性说明:
- cars.Model l – 包含属性汽车型号名称的 x 轴。
- cars.MPG – y 轴,包含每加仑英里数的属性。
- xticks=:all – 这决定是否在 x 轴上显示所有值。对于上面的例子,如果xticks=:all 没有给出,那么一些值将不会出现在 x 轴上,但它们的值将被绘制出来,那么输出将如下所示。

- xrotation :指定 x 轴属性值必须旋转的角度。默认情况下,该值为“0”并且它们水平显示。值 45 稍微倾斜它,值 90 垂直旋转它。
- size :指定绘图的高度和宽度。
- 图例:指定绘制值的标签必须出现的位置。这里包含英里/加仑的框和蓝色阴影框是图例。
在同一个图中绘制数据集的两个属性
朱莉娅
bar(cars.Model,
[cars.MPG,cars.QSec], # plotting two attributes
label = ["Miles/Gallon" "QSec"],
title = "Models-Miles/Gallon and Qsec",
xrotation = 45,
size = [600, 400],
legend =:topleft,
xticks =:all,
yticks =0:35)
输出:

3维线图
之前用向量解释的线图也可以与数据集一起使用。如果传递了三个属性,则图形将绘制为 3 个维度。例如:在 x 轴上绘制齿轮数,在 y 轴上绘制位移,在 z 轴上绘制马力。
朱莉娅
# importing package
using RDatasets
# loading dataets
cars = dataset("datasets", "mtcars")
# 3-dimensions plotting
plot(cars.Gear, # x-axis
cars.Disp, # yaxis
cars.HP, # z-axis
title = "3-dimensional plot",
xlabel = "no.of.gears",
ylabel = "displacement",
zlabel = "HP")
输出:

属性说明:
属性xlabel、ylabel、zlabel包含应显示为每个轴的标签的值。这里的标签是no.of.gears、displacement 和 HP 。
此处显示数据集Prisma-Indian Diabetes 数据集,以了解如何读取本地存储中的数据集。该数据集具有以下属性:怀孕(怀孕次数)、葡萄糖、bp(血压)、皮肤厚度、胰岛素、bmi、dpf(糖尿病谱系函数)、年龄、结果(0 - 非糖尿病,1 - 糖尿病) .最初从 Internet 下载此数据集。
散点图
它用于显示绘制数据中的模式。例如,我们可以使用此图来分析糖尿病谱系函数随年龄变化的任何模式。看看下面的代码片段。
朱莉娅
# import packages
using DataFrames
using CSV
# loading dataset
df = CSV.read("path\\pima-indians-diabetes.csv");
# scatter plot
scatter(df.age, # x-axis
df.dpf, # y-axis
xticks = 20:90,
xrotation = 90,
label = "dpf",
title = "Age and Diabetes Pedigree Function")

直方图
主要用于显示数据的频率。这些条形图称为箱。箱越高,越多的数据落在该范围内。例如,让我们使用直方图检查所取数据集中每个年龄组的人数。看下面的代码片段:
朱莉娅
# import packages
using DataFrames
using CSV
# loading dataset
# semicolon at the end
# prevents printing
df = CSV.read("path\\pima-indians-diabetes.csv");
# plot histogram
histogram(df.age,
bg_inside = "black",
title = "Frequency of age groups",
label = "Age"
xlabel = "age",
ylabel = "freq",
xticks = 20:85,
xrotation = 90)
输出:
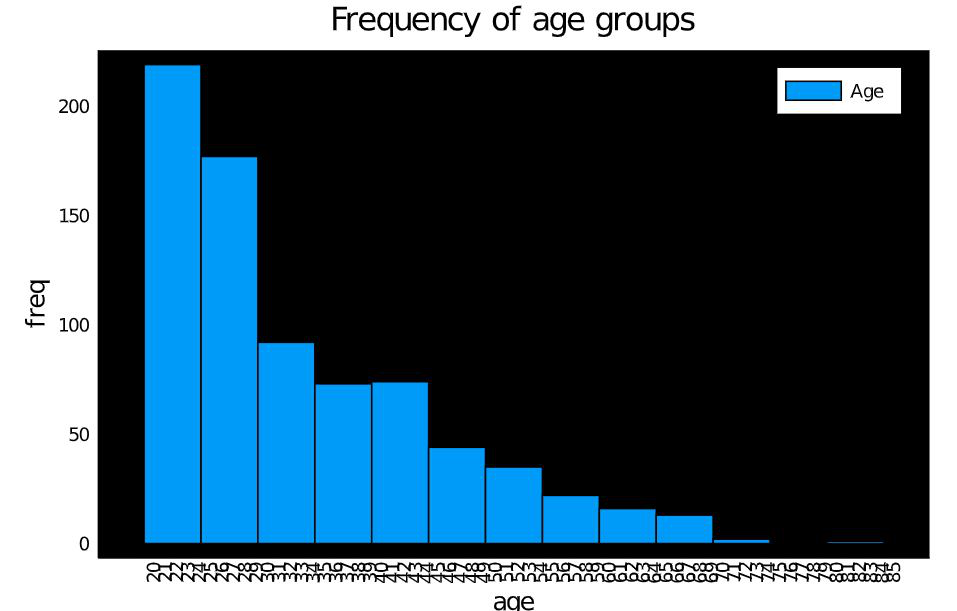
饼形图
饼图是一种用于表示比例的统计图表。在此示例中,让我们表示数据集中糖尿病和非糖尿病患者的数量。为此,必须先进行计数,然后将其绘制在图表中。看看下面的代码片段。
朱莉娅
using DataFrames
using CSV
# load dataset
df = CSV.read("path\\pima-indians-diabetes.csv");
# dataframe to get counts
axis = DataFrame()
axis = by(df, :outcome, nrow)
println(axis)
# dataframe to form
# x-axis and y-axis
items = DataFrame()
# x-axis
items[:x] = ["Diabetic", "Non-Diabetic"]
# y-axis (count)
items[:y] = axis.nrow
pie(items.x, items.y)
输出:

