在 Seaborn 中使用散点图可视化变量之间的关系
为了了解数据集中的变量如何相互关联以及这种关系如何依赖于其他变量,我们进行了统计分析。此统计分析有助于可视化趋势并识别数据集中的各种模式。可用于获取 Seaborn 中两个变量之间关系的函数之一是relplot() 。
Relplot() 将 FacetGrid 与两个轴级函数 scatterplot( )和lineplot()中的任何一个结合起来。散点图是 relplot() 的默认类型。使用它,我们可以通过点云可视化两个变量的联合分布。我们可以使用各种方式在 seaborn 中绘制散点图。最常见的是当两个变量都是数字时。
示例:让我们以一个数据集为例,该数据集包含不同车辆的二氧化碳排放数据。要获取数据集,请单击此处。
# import libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# set grid style
sns.set(style ="darkgrid")
# import dataset
dataset = pd.read_csv('FuelConsumption.csv')
让我们绘制基本散点图,以可视化目标变量“CO2EMISIONS”和“ENGINE SIZE”之间的关系
sns.relplot(x ="ENGINESIZE", y ="CO2EMISSIONS",
data = dataset);
输出: 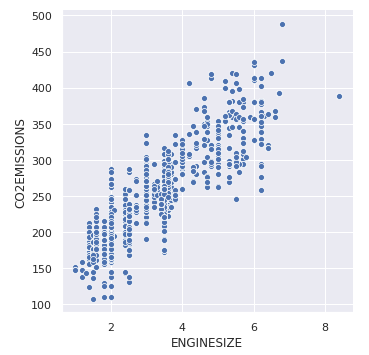
我们可以通过向图中添加另一个维度来添加一个可视化变量。这可以通过使用“色调”来完成,它为第三个变量的点着色,从而为其添加含义。
sns.relplot(x ="ENGINESIZE", y ="CO2EMISSIONS",
hue ="FUELTYPE", data = dataset);
输出: 
为了突出不同的类,我们可以添加标记样式
sns.relplot(x ="ENGINESIZE", y ="CO2EMISSIONS",
hue ="FUELTYPE", style ="FUELTYPE",
data = dataset);
输出: 
在前面的示例中,色调语义用于分类变量,因此它具有默认的定性调色板。但是如果我们使用数值变量而不是分类变量,那么使用的默认调色板是顺序的,也可以修改。
sns.relplot(x ="ENGINESIZE", y ="CO2EMISSIONS",
hue ="CYLINDERS", data = dataset);
输出: 
我们还可以更改第三个变量的点大小。
sns.relplot(x ="ENGINESIZE", y ="CO2EMISSIONS",
size ="CYLINDERS", data = dataset);
输出: 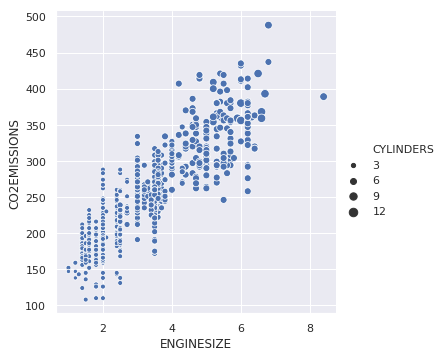
在评论中写代码?请使用 ide.geeksforgeeks.org,生成链接并在此处分享链接。