在Ukkonen的后缀树构造–第1部分中,我们看到了高级的Ukkonen的算法。第二部分是第1部分的续篇。
在阅读当前文章之前,请先阅读第1部分。
在长度为m的字符串S的后缀树构造中,存在m个阶段,并且对于阶段j(1 <= j <= m),我们在到目前为止构建的树中添加了第j个字符,这是通过j扩展来完成的。所有扩展都遵循三个扩展规则之一(在第1部分中讨论)。
为了进行第i + 1阶段的第j个扩展(添加字符S [i + 1]),我们首先需要从当前树中标记为S [j..i]的根开始查找路径的末尾。一种方法是从根开始并遍历匹配S [j..i] 字符串的边缘。这将花费O(m 3 )时间来构建后缀树。使用少量观察和实现技巧,便可以在O(m)中完成,我们现在将看到它。
后缀链接
对于带有路径标签xA的内部节点v,其中x表示单个字符,A表示(可能为空)子字符串,如果存在另一个带有路径标签A的节点s(v),则从v到s( v)称为后缀链接。
如果A为空字符串,则来自内部节点的后缀链接将转到根节点。
根节点将没有任何后缀链接(因为它不被视为内部节点)。 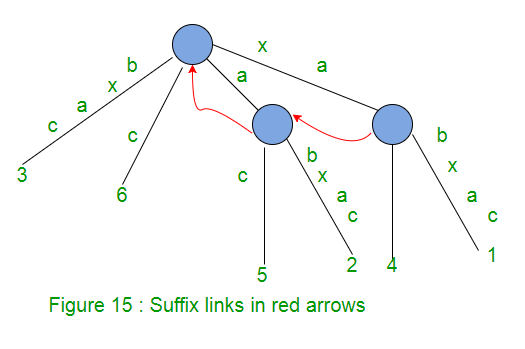
在某个阶段i的扩展j中,如果添加了带有路径标签xA的新内部节点v,则在同一阶段i的扩展j + 1中:
- 标为A的路径已经在内部节点(如果A为空,则是根节点)结束
- 或将在字符串A的末尾创建一个新的内部节点
在相同阶段i的扩展j + 1中,我们将创建一个后缀链接,该链接从在第j个扩展中创建的内部节点到路径标记为A的节点。
因此,在给定阶段,任何新创建的内部节点(带有路径标签xA)在下一个扩展的末尾都将有一个后缀链接(指向另一个带有路径标签A的节点)。
在阶段i之后的任何隐式后缀树T i中,如果内部节点v具有路径标签xA,则T i中存在带有路径标签A的节点s(v),并且节点v将使用以下方式指向节点s(v):后缀链接。
任何时候,更改树中的所有内部节点都将具有从它们到另一个内部节点(或根)的后缀链接,但最近添加的内部节点除外,后者将在下一个扩展的末尾收到其后缀链接。
如何使用后缀链接来加快实现速度?
在阶段i + 1的扩展j中,我们需要从当前树中标记为S [j..i]的根开始查找路径的末尾。一种方法是从根开始并遍历匹配S [j..i] 字符串的边缘。后缀链接提供了一条捷径来查找路径的终点。 

因此,我们可以看到,要找到路径S [j..i]的末尾,我们不需要从根开始遍历。我们可以从路径S [j-1..i]的末尾开始,沿着一条边向上走到节点v(即转到父节点),跟随后缀链接到达s(v),然后沿着路径y(在图17中为abcd)。
这说明使用后缀链接是对过程的改进。
注意:在第3部分中,我们将介绍activePoint,这将有助于避免“走动”。我们可以直接从节点v转到节点s(v)。
当存在从节点v到节点s(v)的一个后缀链路,然后,如果有标记y字符串从节点v到叶的路径,则必须有标有y字符串从节点s(v)至一个路径一片树叶。在图17中,有一个从节点v到叶子的路径标签“ abcd”,然后有一个从节点s(v)到叶子的相同标签“ abcd”的路径。
这个事实可以用来改善从s(v)到沿着路径y的叶子的走动。这称为“跳过/计数”技巧。
跳过/计数技巧
当从节点S(v)至叶,而不是由字符匹配路径字符作为我们旅行走,我们可以直接跳到下一个节点,如果字符在边缘数量小于我们需要旅行的字符数。如果边缘字符的数量比我们要旅行的字符数更多,我们直接跳到该边缘上的最后一个字符。
如果执行的是,在任何边缘的字符数,应该在一定的时间来获得的字符在字符串S的给定位置这样的方式,然后跳过/计数招会做走下来的正比于节点的数量就可以了,而不是它上面的字符数。 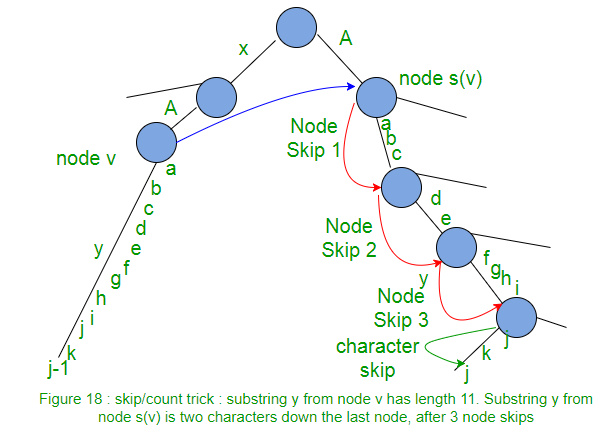
通过使用后缀链接和跳过/计数技巧,可以在O(m 2 )中构建后缀树,因为有m个阶段,每个阶段取O(m)。
边缘标签压缩
到目前为止,通道的标签被表示为在字符串的字符。这样的后缀树将占用O(m 2 )空间来存储路径标签。为了避免这种情况,我们可以在每条边上使用两对索引(开始,结束)作为路径标签,而不是子字符串本身。索引的开始和结束告诉路径标签在字符串S中的开始和结束位置。这样,后缀树需要O(m)空间。 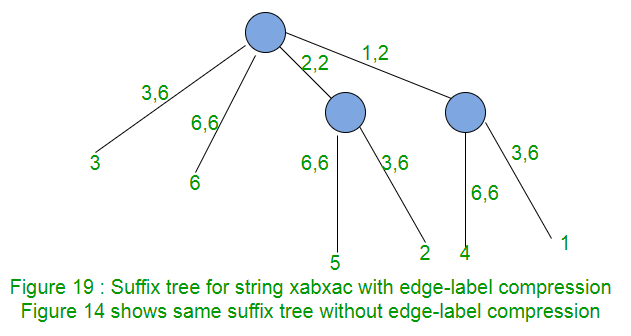
关于扩展规则在连续扩展和阶段中交互的方式有两种观察。这两个观察结果导致了另外两个实现技巧(第一个技巧“跳过/计数”在向下行走时已经看到)。
观察1:规则3是止挡
在阶段i中,有i个扩展(从1到i)要完成。
当规则3适用于阶段i + 1的任何扩展j(即,标记为S [j..i]的路径以字符S [i + 1]继续)时,则规则3也将适用于同一阶段的所有其他扩展(即,扩展在阶段i + 1中从j + 1到i + 1)。这是因为如果标记为S [j..i]的路径以字符S [i + 1]继续,则标记为S [j + 1..i],S [j + 2..i],S [j + 3的路径..i],…,S [i..i]也将以字符S [i + 1]继续。
考虑应用了规则3的第1部分中的图11,图12和图13。
在图11中,在树中添加了“ xab”,在图12中(阶段4),我们添加了下一个字符“ x”。在此完成3个扩展(添加3个后缀)。树中已经存在最后一个后缀“ x”。
在图13中,我们在树中添加了字符“ a”(阶段5)。树中添加了前三个后缀,树中已经存在后两个后缀“ xa”和“ a”。这表明如果后缀S [j..i]存在于树中,则所有其余后缀S [j + 1..i],S [j + 2..i],S [j + 3..i] ,…,S [i..i]也将出现在树中,无需进行任何工作来添加剩余的后缀。
因此,只要规则3适用于该阶段的任何扩展,就无需在任何阶段进行任何工作。如果在扩展名j中创建了一个新的内部节点v,并且在下一个扩展名j + 1中应用了规则3,那么我们需要添加从节点v到当前节点(如果我们在内部节点上)或根节点的后缀链接。 ActiveNode(将在第3部分中进行讨论)将在设置后缀链接时有所帮助。
绝招2
一旦应用规则3,就停止任何阶段的处理。所有进一步的扩展已经隐式存在于树中。
观察二:一片叶子,永远一片叶子
一旦创建了叶子并将其标记为j(后缀从字符串S中的位置j开始),则该叶子将始终是连续阶段和扩展中的叶子。将叶子标记为j后,扩展规则1将在所有连续阶段中始终应用于扩展j。
考虑第1部分中的图9至图14。
在图10(阶段2)中,规则1应用于标记为1的叶子。此后,在所有连续阶段中,规则1始终应用于该叶子。
在图11(阶段3)中,规则1应用于标记为2的叶子。此后,在所有连续阶段中,规则1始终应用于该叶子。
在图12(阶段4)中,规则1应用于标记为3的叶子。此后,在所有连续阶段中,规则1始终应用于该叶子。
在任何阶段i中,都有一个连续的扩展初始序列,其中应用规则1或规则2,然后一旦应用规则3,则阶段i结束。
同样,规则2总是创建一个新叶子(有时还创建一个内部节点)。
如果在应用规则1或2时,J i代表阶段i中的最后一个扩展(即,在第i个阶段之后,将有标记为1,2,3,…,J i的J i叶子),则J i <= J i +1
当在阶段i + 1中没有创建新叶子时,J i将等于J i + 1 (即,在J i + 1扩展中应用了规则3)
在图11(阶段3)中,规则1适用于第一个扩展中的第一个,规则2适用于第三个扩展中的,所以这里J 3 = 3
在图12(阶段4)中,没有创建新的叶子(规则1在第3个扩展中应用,规则3在第4个扩展中应用,从而结束了该阶段)。这里J 4 = 3 = J 3
在图13(阶段5)中,未创建新叶子(规则1在第3个扩展中应用,规则3在第4个扩展中应用,从而结束了该阶段)。这里J 5 = 3 = J 4
Ĵ我会少大于j i + 1的时相I + 1中创建一些新叶。
在图14(阶段6)中,创建了新叶子(规则1在第3个扩展中应用,然后规则2在最后3个扩展中应用,该3个扩展结束了该阶段)。这里J 6 = 6> J 5
因此,我们可以看到在阶段i + 1中,只有规则1才适用于扩展到J i的扩展1(实际上并不需要太多工作,可以在固定时间内完成,这就是窍门3),扩展J i + 1此后,规则2可能适用于零个或多个扩展,然后最终适用于规则3,从而结束了该阶段。
现在,使用两个索引(开始,结束)来表示边缘标签,对于任何叶子边缘,结束将始终等于相位编号,即对于相位i,对于叶子边缘,结束= i,对于叶子i + 1,对于相位i + 1,结束= i + 1叶片边缘。
绝招3
在任何阶段i中,叶边缘看起来都可能像(p,i),(q,i),(r,i),…。其中p,q,r是不同边的起始位置,而i是所有边的终止位置。然后在阶段i + 1中,这些叶边缘将看起来像(p,i + 1),(q,i + 1),(r,i + 1),…。这样,在每个阶段中,必须在所有叶片边缘中增加最终位置。为此,我们需要遍历所有叶边缘并增加其末端位置。要在固定时间内执行相同的操作,请保持全局索引e,并且e将等于相数。因此,现在叶的边缘将看起来像(p,e),(q,e),(r,e)。在任何阶段,只需递增e即可完成所有叶边缘的扩展。图19显示了这一点。
因此,使用后缀链接和技巧1、2和3,可以在线性时间内构建后缀树。
如果后缀是另一个的前缀,则树Tm可以是隐式树。因此,我们可以先添加$终端符号,然后运行算法以获得真实的后缀树(真实的后缀树显式包含所有后缀)。为了用相应的后缀起始位置标记每个叶子(所有叶子都标记为全局索引e),可以在树上进行线性时间遍历。
至此,我们已经完成了使用Ukkonen算法创建后缀树所需的大多数知识。在接下来的第3部分中,我们将以字符串S =“ abcabxabcd”为例,并逐步研究所有内容并创建树。在构建树时,我们将讨论更多的实现问题,ActivePoints将解决这些问题。
我们将在第4部分和第5部分中继续讨论算法。在第6部分中将讨论代码实现。
参考文献:
http://web.stanford.edu/~mjkay/gusfield.pdf