本文是以下四篇文章的续篇:
Ukkonen的后缀树构造–第1部分
Ukkonen的后缀树构造–第2部分
Ukkonen的后缀树构造–第3部分
Ukkonen的后缀树构造–第4部分
在阅读当前文章之前,请先阅读第1部分,第2部分,第3部分和第4部分,在这里我们几乎看不到后缀树的基本知识,高级ukkonen算法,后缀链接和三个实现技巧,以及activePoint的一些细节以及示例字符串“ abcabxabcd”,我们经历了构建后缀树的六个阶段。
在这里,我们将经历其余的阶段(7至11),并完整地构建树。
*********************第7阶段******************************* ******
在阶段7中,我们从字符串S读取了第7个字符(a)
- 将END设置为7(这将执行扩展1、2、3、4、5和6)–因为到上一个阶段6为止,到目前为止我们有6个叶边缘。
- 将remainingSuffixCount增加1(此处remainingSuffixCount将为1,即只剩下1个扩展要执行,即后缀“ a”的扩展为7)
- 如下循环运行剩余的SuffixCount次(即一次):
- 如果activeLength为零[上一阶段的activePoint为(root,x,0)],则将activeEdge设置为当前字符(此处activeEdge将为’a’)。这是APCFALZ 。现在activePoint变为(root,’a’,0)。
- 检查是否有来自activeNode的边缘(在此阶段7中是根节点)对于activeEdge。如果没有,请创建叶子边缘。如果有的话,走下去。在我们的示例中,边缘’a’存在于activeNode(即根)之外,这里我们将activeLength从零增加到1( APCFER3 )并停止任何进一步的处理。
- 此时,activePoint为(根,a,1),而remainingSuffixCount仍设置为1(此处无变化)
在阶段7结束时,remainingSuffixCount为1(一个后缀’a’,即最后一个,未在树中显式添加,但在树中隐式存在)。
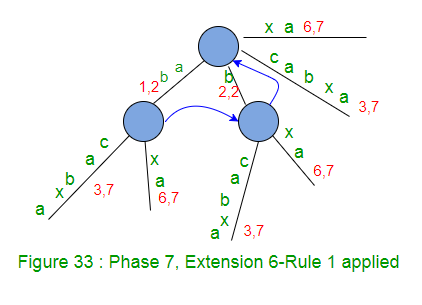
图33上方是阶段7之后的结果树。
*********************第八阶段*************************** ******
在阶段8中,我们从字符串S读取了第8个字符(b)
- 将END设置为8(这将执行扩展1、2、3、4、5和6)–因为到上一个阶段7为止,到目前为止我们有6个叶边缘(图34)。
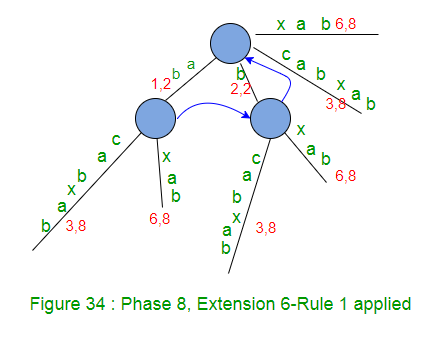
- 将remainingSuffixCount增加1(此处remainingSuffixCount将为2,即还有两个扩展要执行,分别是后缀“ ab”和“ b”的扩展7和8)
- 如下运行循环剩下的SuffixCount次(即两次):
- 检查activeEdge是否有一条从activeNode(在此阶段8中为根)伸出的边缘。如果没有,请创建叶子边缘。如果有的话,走下去。在我们的示例中,边缘“ a”存在于activeNode(即根)之外。
- 如有必要,请步行(技巧1 –跳过/计数)。在当前阶段8中,由于activeLength
- 检查activePoint之后是否已经存在字符串S的当前字符(“ b”)。如果是,则不再进行处理(规则3)。在我们的示例中也是如此,因此我们将activeLength从1增加到2( APCFER3 ),然后在此处停止(规则3)。
- 此时,activePoint为(根,a,2),而remainingSuffixCount仍设置为2(remainingSuffixCount不变)
在阶段8结束时,剩余的SuffixCount为2(两个后缀’ab’和’b’,后两个,未在树中显式添加,而是隐式地在树中添加)。
*********************阶段9 *************************** ******
在阶段9中,我们从字符串S读取第9个字符(c)
- 将END设置为9(这将执行扩展1、2、3、4、5和6)–因为到目前为止,到上一个阶段8为止,我们有6个叶边缘。

- 将remainingSuffixCount递增1(此处remainingSuffixCount将为3,即剩下三个扩展要执行,分别是后缀“ abc”,“ bc”和“ c”的扩展7、8和9)
- 如下运行循环剩下的SuffixCount次(即3次):
- 检查是否有来自activeNode的边缘(在此阶段9中是根节点)连接到activeEdge。如果没有,请创建叶子边缘。如果有的话,走下去。在我们的示例中,边缘“ a”存在于activeNode(即根)之外。
- 如有必要,请步行(技巧1 –跳过/计数)。在当前阶段9中,由于activeLength(2)> = edgeLength(2),需要向下走。而走下来,activePoint变为基于APCFWD(节点A,C,0)(这是第一次APCFWD被在我们的例子使用)。
- 检查activePoint之后是否已经存在字符串S的当前字符(即“ c”)。如果是,则不再进行处理(规则3)。在我们的示例中也是如此,因此我们将activeLength从0增加到1( APCFER3 ),然后在此处停止(规则3)。
- 此时,activePoint为(节点A,c,1),而remainingSuffixCount仍设置为3(remainingSuffixCount不变)
在阶段9结束时,剩余的SuffixCount为3(三个后缀’abc’,’bc’和’c’,后三个,未在树中显式添加,而是隐式地在树中)。
*********************第10阶段******************************** ******
在阶段10中,我们从字符串S中读取第10个字符(d)
- 将END设置为10(这将执行扩展1、2、3、4、5和6)–因为到目前为止,到上一个阶段9为止,我们有6个叶边缘。
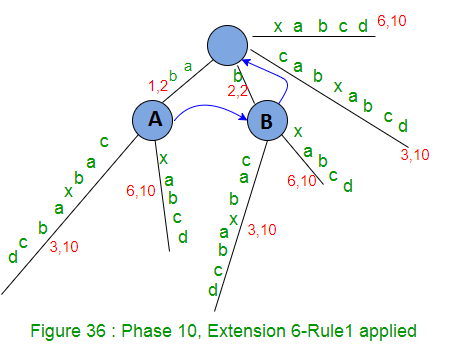
- 将remainingSuffixCount递增1(此处remainingSuffixCount将为4,即还有四个扩展要执行,分别是后缀“ abcd”,“ bcd”,“ cd”和“ d”的扩展7、8、9和10)
- 循环运行剩余的SuffixCount次(即四次),如下所示:
- *********************扩展名7 *************************** ******
- 检查activeEdge(c)是否从activeNode(节点A)出边缘。如果没有,请创建叶子边缘。如果有的话,走下去。在我们的示例中,边缘“ c”存在于activeNode(节点A)之外。
- 如有必要,请步行(技巧1 –跳过/计数)。在当前的扩展程序7中,由于activeLength
- 检查activePoint之后是否已经存在字符串S的当前字符(“ d”)。否则,将适用规则2。在我们的示例中,没有路径以’d’离开activePoint,因此我们创建了带有标签’d’的叶子边缘。由于activePoint在边缘的中间结束,因此我们将在activePoint之后创建一个新的内部节点(规则2)
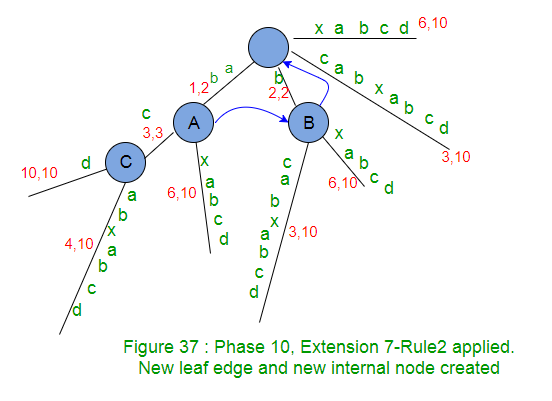
- 当在树中添加后缀“ abcd”时,将剩余的SuffixCount减1(从4减至3)。
- 现在,activePoint将更改为下一个扩展8。当前的activeNode是一个内部节点(节点A),因此必须有一个后缀链接,我们将按照该链接获得新的activeNode,它将成为“节点B”。 activeEdge和activeLength(这是APCFER2C2 )没有变化。因此,新的activePoint是(节点B,c,1)。
*********************扩展名8 *************************** ******
- 现在,在延长8日activePoint(在这里我们将添加后缀“BCD”),而目前activePoint后加入字符“d”,正是同样的逻辑适用如先前的扩展7.在以前延长7中,我们添加字符“d”(节点A,c,1)和当前扩展8中,我们将在activePoint(节点B c,1)处添加相同的字符“ d”。因此逻辑将是相同的,在这里我们将创建一个带有标签“ d”的新叶子边缘和一个新的内部节点。并且前一个扩展的新内部节点(C)将通过后缀链接指向当前扩展的新节点(D)。
- 当前扩展7中新创建的内部节点c(在上图中)将在下一个扩展8中设置其后缀链接(请参见下面的图38)。

- 当在树中添加后缀“ bcd”时,将剩余的SuffixCount减1(从3到2)。
- 现在,activePoint将更改为下一个扩展9。当前activeNode是一个内部节点(节点B),因此必须有一个后缀链接,我们将按照该链接获得新的activeNode,即“根节点”。 activeEdge和activeLength(这是APCFER2C2 )没有变化。因此,新的activePoint是(root,c,1)。
*********************扩展名9 *************************** ******
- 现在在扩展名9中(这里我们将添加后缀’cd’),在当前activePoint之后添加字符’d’时,将采用与先前扩展名7和8完全相同的逻辑。请注意,在先前扩展名8中创建的内部节点D现在通过后缀链接指向内部节点E(在当前扩展中创建)。
- 请注意,上一个扩展的节点C(请参见上面的图37)在此处设置了后缀链接,而在当前扩展中创建的节点D将在下一个扩展中获取其后缀链接。如果在下一个扩展中没有创建新节点,会发生什么?我们之前在阶段6(第4部分)中已经看到了这一点,并将在此阶段10的最后扩展中再次看到。

- 在树中添加后缀“ cd”时,将剩余的SuffixCount减1(从2到1)。
- 现在,activePoint将更改为下一个扩展10。基于APCFER2C1 ,当前activeNode为root,activeLength为1,activeNode将保持“ root”,activeLength减1(从1到ZERO),activeEdge将为“ d”。因此,新的activePoint是(root,d,0)。
*********************扩展10 *************************** ******
- 现在在扩展10中(在这里我们将添加后缀’d’),在当前activePoint之后添加字符’d’时,没有以d开头的边超出activeNode根,因此创建了带有标签d的新叶边(规则2)。注意,在上一个扩展9中创建的内部节点E现在通过后缀链接指向根节点(因为在此扩展中没有创建新的内部节点)。

- 当在树中添加后缀“ d”时,将剩余的SuffixCount减1(从1到0)。这意味着没有更多的后缀可以添加,因此阶段10到此结束。请注意,该树是一个显式树,因为所有后缀都显式地添加到树中(为什么??,因为到目前为止在字符串S中之前都没有看到字符d)
- 下一阶段11的activePoint是(root,d,0)。
- 在上一个扩展中创建的内部节点,等待在下一个扩展中设置后缀链接,如果在下一个扩展中没有创建内部节点,则指向根。在代码实现中,如果规则2适用于现有或新创建的节点,则一旦在扩展名j中创建了一个新的内部节点(方式A),我们就将其后缀链接设置为根节点,并在下一个扩展名j + 1中进行设置。 (说B)或规则3适用于某个活动节点(说B),则节点A的后缀链接将更改为新节点B,否则节点A将继续指向根
我们在阶段10中看到以下事实:
- 通过后缀链接连接的内部节点在它们下面具有完全相同的树,例如,在图40上方,A和B在其下面具有相同的树,类似地C,D和E在它们下面也具有相同的树。
- 由于上述事实,在任何扩展中,当通过后缀链接从前一扩展的activeNode派生当前activeNode时,则在当前扩展中将使用与前一扩展完全相同的扩展逻辑。 (在阶段10中,相同的扩展逻辑应用于扩展7、8和9)
- 如果在任何阶段i的扩展名j中创建了一个新的内部节点,则该新创建的内部节点将获得在相同阶段的下一个扩展名j + 1的末尾设置的后缀链接,例如,在阶段10的扩展名7中创建的节点C。 (图37),并将其后缀链接设置为相同阶段10的扩展8中的节点D。类似地,在阶段10的扩展8中创建了节点D(图38),并将其后缀链接设置为同一阶段10的扩展9中的节点E(图39)。同样,在阶段10的扩展9中创建了节点E(图39),并将其后缀链接设置为在同一阶段10的扩展10中的根(图40)。
- 基于上述事实,每个内部节点都将具有到其他内部节点或根的后缀链接。根不是内部节点,它将没有后缀链接。
*********************阶段11 *************************** ******
在阶段11中,我们从字符串S中读取第11个字符($)
- 将END设置为11(这将执行1到10的扩展)–因为到目前为止,在上一个阶段10的末尾,我们有10个叶子边缘。
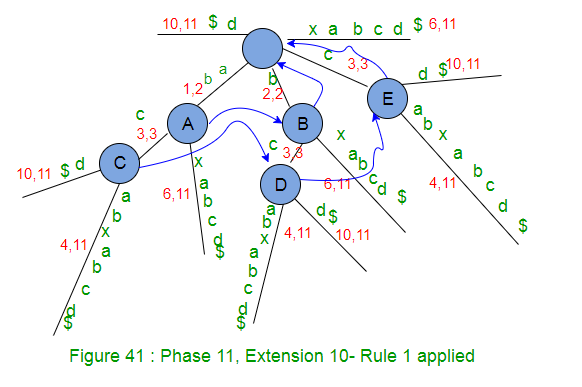
- 将剩余的SuffixCount增加1(从0到1),即在树中仅添加一个后缀’$’。
- 由于activeLength为零,所以activeEdge将更改为正在处理的字符串S( APCFALZ )的当前字符’$’。
- 从activeNode根开始没有边缘出,因此将创建带有标签“ $”的叶边缘(规则2)。
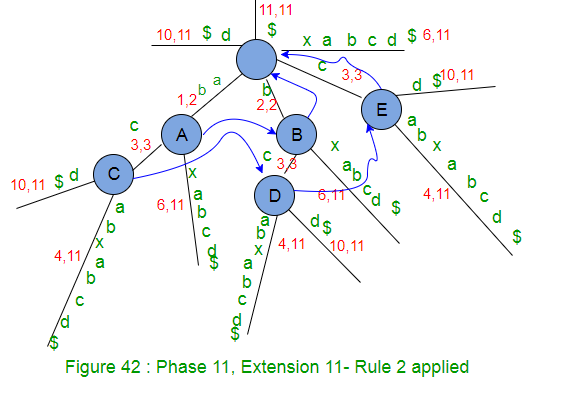
- 当在树中添加后缀“ $”时,将剩余的SuffixCount减1(从1到0)。这意味着没有更多的后缀可以添加,因此阶段11到此结束。请注意,这棵树是一个显式树,因为所有后缀都显式地添加到树中(为什么??,因为到目前为止在字符串S中未出现字符$)
现在,我们在后缀树中添加了字符串’abcabxabcd $’的所有后缀。这棵树有11个叶端,从根到叶端的路径上的标签代表一个后缀。现在剩下的唯一一件事是为每个叶子末端分配一个数字(后缀索引),该数字将成为字符串S中后缀的起始位置。这可以通过在树上进行DFS遍历来实现。遍历DFS时,请跟踪标签长度,并在找到叶子末端时,将后缀索引设置为“ stringSize – labelSize + 1”。索引后缀树将如下所示: 
在上图中,后缀索引显示为以1开头(不是零索引)的字符位置。在代码实现中,后缀索引将设置为零索引,即在上图中我们看到后缀索引j(长度为m的字符串为1到m),在代码实现中,它将为j-1(0到m-1) )
我们完成了!!!!
表示后缀树的数据结构
如何表示后缀树?有节点,边,标签和后缀链接和索引。
以下是在构建后缀树时以及稍后在不同的应用程序/用法中使用后缀树时我们将要执行的一些操作/查询:
- 某个边缘的路径标签长度是多少?
- 某些边缘的路径标签是什么?
- 检查节点中给定字符的传出边缘是否存在。
- 距节点一定距离的边缘上的字符值是多少?
- 内部节点通过后缀链接指向何处?
- 从根到叶的路径上的后缀索引是什么?
- 检查后缀树中是否存在给定的字符串(作为子字符串,后缀或前缀)?
我们可能会想到可以满足这些要求的不同数据结构。
在接下来的第6部分中,我们将讨论将在代码实现中使用的数据结构以及代码。
参考文献:
http://web.stanford.edu/~mjkay/gusfield.pdf
普通英语的Ukkonen后缀树算法