本文是以下两篇文章的续篇:
Ukkonen的后缀树构造–第1部分
Ukkonen的后缀树构造–第2部分
在阅读当前文章之前,请先阅读第1部分和第2部分,在该文章中,我们几乎看不到后缀树,高级ukkonen算法,后缀链接和三个实现技巧的基础知识。
在这里,我们以字符串S =“ abcabxabcd”为例,逐步介绍所有内容并创建树。
我们将添加$(在第1部分中讨论了为什么这样做),因此字符串S为“ abcabxabcd $”。
在构建长度为m的字符串S的后缀树时:
- 将有m个阶段1到m(每个字符一个阶段)
在我们当前的示例中,m为11,因此将有11个相位。 - 第一阶段将在树中添加第一个字符“ a”,第二阶段将在树中添加第二个字符“ b”,第三阶段将在树中添加第三个字符“ c”,……,第m阶段将在树中添加第m个字符(这使Ukkonen算法成为一种在线算法)
- i的每个阶段最多将经历i个扩展(从1到i)。如果到目前为止看不到在树中添加的当前字符,则所有i扩展都将完成(扩展规则3在此阶段不适用)。如果之前看到在树中添加了当前字符,则阶段i将尽早完成(适用扩展规则3),而无需经历所有i扩展
- 存在三个扩展规则(1、2和3),并且任何阶段i的每个扩展j(从1到i)都将遵循这三个规则之一。
- 规则1在现有的叶子边缘上添加了一个新字符
- 规则2创建新的叶子边缘(如果路径标签在边缘之间结束,则规则2也可以创建新的内部节点)
- 规则3结束当前阶段(在正在遍历的当前边沿中找到当前字符时)
- 阶段1将读取字符串的第一个字符,并将经过1个扩展名。
(在图中,我们在边缘标签上显示字符只是为了说明,而在编写代码时,我们将仅使用开始和结束索引–第2部分中讨论的Edge-label压缩)
扩展1将在树中添加后缀“ a”。我们从根开始并遍历带有标签“ a”的路径。从根开始没有路径,带有标签“ a”,所以创建一个叶子边缘(规则2)。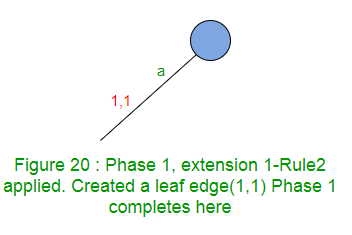
阶段1随着扩展1的完成而完成(因为阶段i最多具有i个扩展)
对于任何字符串,阶段1将仅具有一个扩展名,并且它将始终遵循规则2。 - 阶段2将读取第二个字符,将经历至少1个和最多2个扩展。
在我们的示例中,阶段2将读取第二个字符“ b”。要添加的后缀是“ ab”和“ b”。
扩展1在树中添加后缀“ ab”。
标签“ a”的路径在叶边缘结束,因此在该边缘的末尾添加“ b”。
扩展1只是在第一个边沿(规则1)上将结束索引加1(从1到2)。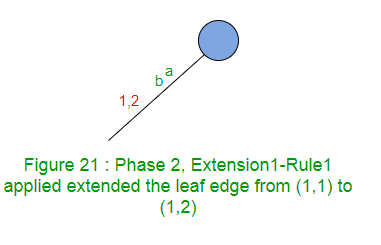
扩展名2在树中添加后缀“ b”。从根开始没有路径,带有标签“ b”,所以创建了叶子边缘(规则2)。
第2阶段随着扩展2的完成而完成。
第二阶段在这里经历了两个扩展。规则1适用于第一扩展,规则2适用于第二扩展。 - 阶段3将读取第三个字符,将经历至少1个和最多3个扩展。
在我们的示例中,阶段3将读取第三个字符’c’。要添加的后缀为“ abc”,“ bc”和“ c”。
扩展1在树中添加后缀“ abc”。
标签“ ab”的路径在叶边缘结束,因此在该边缘的末尾添加“ c”。
扩展1仅在此边缘(规则1)上将结束索引加1(从2到3)。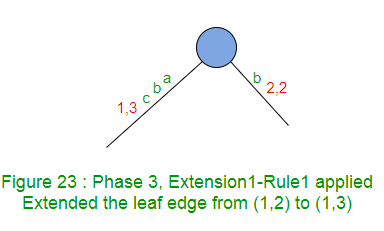
扩展2在树中添加后缀“ bc”。
标签“ b”的路径在叶边缘结束,因此在该边缘的末尾添加“ c”。
扩展2仅在此边缘(规则1)上将结束索引加1(从2到3)。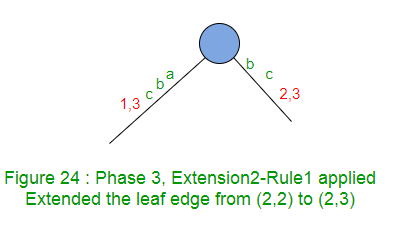
扩展名3在树中添加后缀“ c”。从根开始没有路径,带有标签“ c”,所以创建了叶子边缘(规则2)。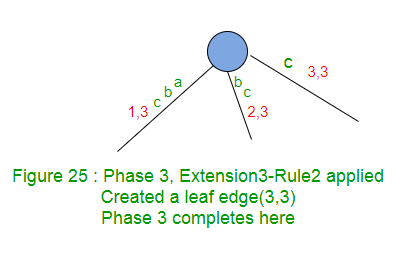
第三阶段随着扩展3的完成而完成。
第三阶段在这里经历了三个扩展。规则1适用于前两个扩展,规则2适用于第3个扩展。 - 阶段4将读取第四个字符,将转到至少1个,最多4个扩展名。
在我们的示例中,阶段4将读取第四个字符“ a”。要添加的后缀是“ abca”,“ bca”,“ ca”和“ a”。
扩展1在树中添加后缀“ abca”。
标签“ abc”的路径在叶边缘结束,因此在该边缘的末尾添加“ a”。
扩展1仅在此边缘(规则1)上将结束索引加1(从3到4)。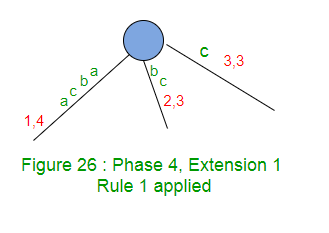
扩展2在树中添加了后缀“ bca”。
标签“ bc”的路径在叶子边缘结束,因此在该边缘的末尾添加“ a”。
扩展2仅在此边缘(规则1)上将结束索引加1(从3到4)。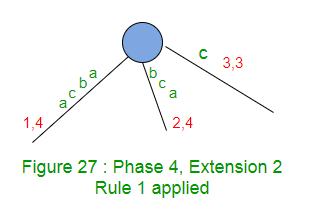
扩展3在树中添加后缀“ ca”。
标签“ c”的路径在叶边缘结束,因此在该边缘的末尾添加“ a”。
扩展3仅在此边缘(规则1)上将结束索引加1(从3到4)。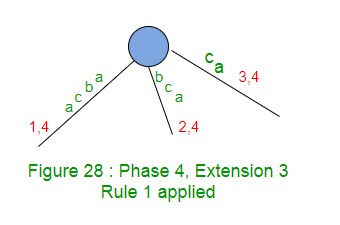
扩展名4在树中添加后缀“ a”。
树中存在标签“ a”的路径。无需更多工作,第四阶段到此结束(规则3和技巧2)。这是隐式后缀树的示例。在这里,后缀“ a”没有明确显示(因为它没有在叶子边缘结束),但是隐式地在树中。因此,扩展名4之后的树结构没有任何变化。它将保持与图28相同。
在扩展4上应用规则3后,第4阶段就完成了。
第四阶段在这里经历了四个扩展。规则1适用于前三个扩展,规则3适用于第4个扩展。
现在,我们将看到很少的观察结果以及如何执行这些观察结果。
- 在任何第i阶段结束时,最多只有i个叶边缘(如果到目前为止没有看到第i个字符,则将有i个叶边缘,否则将少于i个叶边缘)。
例如,在我们的示例中的阶段1、2和3之后,分别有1、2和3个叶边缘,但是在阶段4之后,仅存在3个叶边缘(不是4个)。 - 完成阶段i后,所有叶边缘的“结束”索引为i。我们如何在代码中实现呢?我们是否需要遍历所有这些扩展,通过从根到叶遍历来找到叶边缘并增加“ end”索引?答案是“否”。
为此,我们将维护一个全局变量(例如“ END”),并且将递增该全局变量“ END”,并且所有叶边缘端点索引都将指向该全局变量。因此,如果在阶段i之后有j个叶边缘,则在阶段i + 1中,只需将变量“ END”增加1(在第i + 1个阶段,END将为i + 1)即可完成第一个j扩展(从1到j)。观点)。
在这里,我们只是实现了技巧3 –一片叶子,总是一片叶子。该技巧在任何阶段中使用规则1在恒定时间内处理所有j个叶边缘(即,从扩展1到j)。规则1不适用于同一阶段的后续扩展。这可以在我们上面讨论的四个阶段中进行验证。如果根本上规则1在任何阶段都适用,那么它仅连续地在最初的几个阶段中适用(例如1至j)。一旦在该阶段应用了规则2或规则3,规则1就永远不会在该阶段以后应用。 - 在到目前为止说明的示例中,在任何阶段的任何扩展中(未应用技巧3)在树中添加后缀,我们都通过将路径标签与要添加的后缀进行匹配来从根遍历。如果在阶段i之后有j个叶边缘,则在阶段i + 1中,前j个扩展将遵循规则1,并且将使用技巧3在恒定的时间内完成。还有i + 1-j个扩展尚待执行。对于这些扩展,从哪个节点(根节点或其他内部节点)开始,走哪条路径?答案取决于上一阶段的完成方式。
如果上一阶段我经历了所有i扩展(到目前为止,第i个字符是唯一的),则在下一个阶段i + 1中,技巧3将首先处理后缀i(叶边缘),然后扩展i + 1将从根节点开始,它会插入一个字符[第(i + 1)个]后缀树中通过创建使用规则2叶边缘。
如果上一个阶段i提前完成(并且仅在规则3适用的情况下才会发生-当第i个字符已经出现时),例如在第j个扩展名处(即在第j个扩展名应用规则3),则存在第j个-1叶边缘至今。
根据到目前为止的讨论,我们将在这里再陈述一些事实(可能是重复的,但我们现在要确保对您来说很清楚):- 阶段1从规则2开始,所有其他阶段从规则1开始
- 任何阶段都以规则2或规则3结尾
- 任何阶段i都可能经历一系列j扩展(1 <= j <= i)。在这j个扩展中,前p个(0 <= p
- 在阶段i中,p + q + r <= i
- 在任何阶段i结束时,将有p + q个叶边缘,下一个阶段i + 1将通过规则1进行第一个p + q扩展
在下一阶段i + 1中,技巧3(规则1)将处理第一个j-1后缀(j-1叶子边缘),然后扩展名j开始,在树中添加第j个后缀。为此,我们需要找到最佳的匹配边缘,然后在该边缘的末尾添加新字符。如何找到最佳匹配边缘的末端?我们是否需要从根节点遍历和对阵日后缀由字符添加字符第j树边?这将花费时间,并且整个算法将不是线性的。 activePoint在这里进行救援。
在上一个阶段i中,在第j个扩展的同时,路径遍历在某个点(可能是内部节点或边缘中间的某个点)结束,在该点已经在树中找到了添加第i个字符并应用了规则3的情况,第i + 1阶段的第一个扩展将完全从同一点开始,我们开始针对第(i + 1)个字符匹配路径。 activePoint基于先前扩展中遍历所获得的知识,有助于避免从任何扩展中的根目录遍历不必要的路径。没有在规则1被施加1名p的扩展需要遍历。在应用规则2或规则3的地方进行遍历,这是activePoint告诉遍历的起点,在此处我们将路径与树中添加的当前字符进行匹配。实现的方式是,在我们需要遍历的任何扩展中,已经将activePoint设置到正确的位置(下面将讨论一个例外情况APCFALZ ),并且在当前扩展的结尾,我们将activePoint重置为适当的位置,以便下一步在需要遍历的扩展(同一阶段或下一阶段)中,activePoint已经指向正确的位置。activePoint :这可以是根节点,任何内部节点或边缘中间的任何点。这是在任何扩展中开始遍历的点。对于阶段1的第一个扩展,将activePoint设置为root。其他扩展将通过先前的扩展正确设置activePoint(下面将讨论一个例外情况APCFALZ ),并且当前扩展的责任是在末尾适当地重置activePoint,以在应用规则2或规则3的下一个扩展中使用(相同或下一个阶段)。
为此,我们需要一种存储activePoint的方法。我们将使用三个变量来存储它: activeNode , activeEdge , activeLength 。
activeNode :这可以是根节点或内部节点。
activeEdge :当我们在根节点或内部节点上并且需要走下时,我们需要知道选择哪个边缘。 activeEdge将存储该信息。万一activeNode本身是遍历的起点,则将activeEdge设置为下一阶段要处理的下一个字符。
activeLength :这告诉我们需要多少字符从activeNode向下走(在activeEdge表示的路径上)以到达遍历开始的activePoint。如果activeNode本身是遍历的起点,则activeLength将为零。
在阶段i之后,如果存在j个叶边缘,则在阶段i + 1中,将通过技巧3完成前j个扩展。从j + 1到i + 1的扩展将需要activePoint,并且activePoint可能会或可能不会在两个扩展名,具体取决于上一个扩展名的结束点。扩展规则3(APCFER3)的activePoint更改:当规则3在任何阶段i中都适用时,则在我们进入下一个阶段i + 1之前,我们将activeLength递增1。activeNode和activeEdge不变。为什么?因为在规则3的情况下,来自字符串S的当前字符在当前activePoint表示的同一路径上匹配,所以对于下一个activePoint,activeNode和activeEdge保持相同,仅将activeLenth增加1(因为在当前阶段匹配的字符) )。此新的activePoint(相同的节点,相同的边沿和增加的长度)将在阶段i + 1中使用。
向下走动的ActivePoint更改(APCFWD) :根据所应用的扩展规则,activePoint可能会在扩展的末尾更改。当我们走下来时,activePoint可能还会在扩展过程中发生变化。在上面的activePoint示例图中,让我们考虑一个activePoint是(A,s,11)。如果这是某个扩展开始时的activePoint,则当从activeNode A向下走时,将看到其他内部节点。每当我们在走下时遇到一个内部节点时,该节点将变为activeNode(它将适当地更改activeEdge和activeLenght,以便新的activePoint代表与之前相同的点)。在本次深入了解中,以下是activePoint的更改顺序:
(A,s,11)->>>(B,w,7)— >>>(C,a,3)
以上三个activePoints都指向相同的点“ c”
让我们再举一个例子。
如果扩展名开头的activePoint是(D,a,11),则在向下走时,下面是activePoint的更改顺序:
(D,a,10)— >>>(E,d,7)— >>>(F,f,5)— >>(G,j,1)
上面所有的activePoints都指向相同的点“ k”。
如果activePoints是(A,s,3),(A,t,5),(B,w,1),(D,a,2)等,当没有内部节点走下时,那么将对于APCFWD,activePoint保持不变。
这个想法是,在任何时候,离我们要到达的点最近的内部节点应该是activePoint。为什么?这将在下一个扩展中最小化遍历的长度。有效长度为零(APCFALZ)的activePoint更改:让我们考虑上面的activePoint示例图中的activePoint(A,s,0)。假设正在从字符串S处理的当前字符为’x’(或其他任何字符)。在扩展开始时,当activeLength为ZERO时,activeEdge设置为正在处理的当前字符,即’x’,因为这里不需要下移(因为activeLength为ZERO),所以我们要查找的下一个字符是当前字符正在处理。
- 在执行代码时,我们将一一遍历字符串S的所有字符。第i个字符的每个循环将对第i阶段进行处理。循环将运行一个或多个时间,具体取决于剩余要执行的扩展数量(请注意,在i + 1阶段,我们实际上不必显式地执行所有i + 1扩展,因为技巧3会解决这个问题来自上一阶段i)的所有j个叶边缘的j个扩展。我们将使用变量剩下的SuffixCount来跟踪在任何阶段(在执行技巧3之后)要显式执行多少个扩展。同样,在任何阶段结束时,如果remainingSuffixCount为ZERO,这表明应该在树中添加的所有后缀都已显式添加并存在于树中。如果在任何阶段结束时,remainingSuffixCount不为零,则表明未将那么多计数的后缀显式添加到树中(由于规则3,我们提早停止了),但是它们隐式地在树中(这样的树称为隐式后缀树)。这些唯一的字符会在后面的阶段中显式添加这些隐式后缀。
我们将在第4部分和第5部分中继续我们的讨论。在第6部分中将讨论代码实现。
参考文献:
http://web.stanford.edu/~mjkay/gusfield.pdf
普通英语的Ukkonen后缀树算法