后缀树在众多字符串处理和计算生物学问题中非常有用。许多书籍和电子资源从理论上谈论它,并且在少数地方讨论了代码实现。但是,我仍然感觉缺少了一些东西,实现代码以构造后缀树并不容易,它在许多应用程序中都得到了使用。这是试图弥合理论与完整的工作代码实现之间的鸿沟。在这里,我们将讨论Ukkonen的后缀树构造算法。我们将逐步详细地讨论它,并从理论到实现分多个部分。我们将从暴力方式开始,尝试理解不同的概念,Ukkonen算法中涉及的技巧,最后一部分将讨论代码实现。
注意:在第一次或第二次阅读时,您可能会发现算法的某些部分难以理解,并且非常好。稍加尝试和思考,您就应该能够理解这些部分。
Dan Gusfield撰写的《关于字符串,树和序列的算法:计算机科学和计算生物学》一书很好地解释了这些概念。
m个字符的字符串S的后缀树T是有根的有向树,其正好有m个叶子编号为1到m。 (鉴于最后一个字符串字符在字符串是唯一的)
- 根可以有零个,一个或多个孩子。
- 除根之外,每个内部节点都至少具有两个子节点。
- 每个边都用S的非空子字符串标记。
- 从同一节点出来的两个边缘都不能具有以相同字符开头的边缘标签。
从根到叶i的路径上边缘标签的串联给出了从位置i开始的S后缀,即S [i…m]。
注意: Position从1开始(不是零索引位置,但是稍后,在代码实现中,我们将使用零索引位置)
对于m = 6的字符串S = xabxac,后缀树如下所示: 
它具有一个根节点,两个内部节点和6个叶节点。
红色路径的字符串深度为1,它表示从位置6开始的后缀c
蓝色路径的字符串深度为4,它表示从位置3开始的后缀bxca
绿色路径的字符串深度为2,它表示从位置5开始的后缀ac
橙色路径的字符串深度为6,它表示从位置1开始的后缀xabxac
标签为a(绿色)和xa(橙色)的边为非叶子边(在内部节点处结束)。所有其他边缘均为叶子边缘(在叶子上结束)
如果S的一个后缀与S的另一个后缀的前缀匹配(当字符串的最后一个字符不唯一时),则第一个后缀的路径不会在叶子处结束。
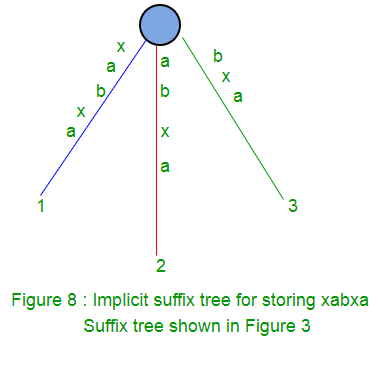
对于字符串S = xabxa,m = 5,以下是后缀树: 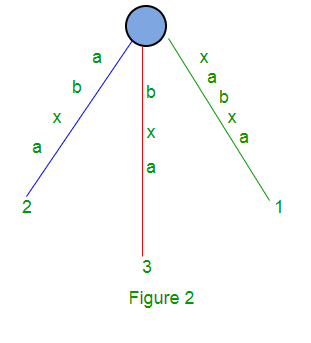
在这里,我们将有5个后缀:xabxa,abxa,bxa,xa和a。
后缀“ xa”和“ a”的路径不以叶子结尾。像上面这样的树(图2)被称为隐式后缀树,因为某些后缀(“ xa”和“ a”)在树中未明确显示。
为避免此问题,我们添加了字符中不存在的字符串。我们通常使用$,#等作为终止字符。
以下是字符串S = xabxa $的后缀树,其中m = 6,现在所有6个后缀都以leaf结尾。 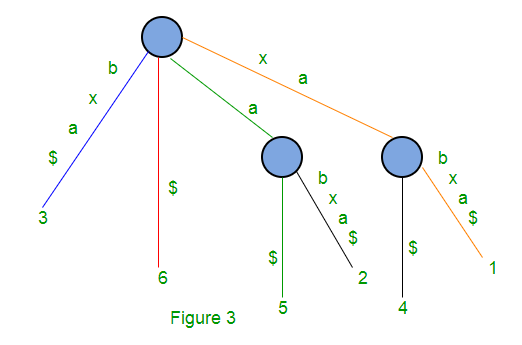
幼稚的算法来构建后缀树
给定长度为m的字符串S,将后缀S [l..m] $(整个字符串)的单个边输入到树中,然后将后缀S [i..m] $输入到成长的树中,对于i从2增加到m令N i表示对从1到i的所有后缀进行编码的中间树。
因此,从N i构造N i +1如下:
- 从N i的根开始
- 从根查找与前缀S [i + 1..m] $相匹配的最长路径
- 匹配在节点处(例如w)或在边缘的中间处(例如(u,v))结束。
- 如果它位于边缘(u,v)的中间,则通过在边缘上与S [i + 1]中的字符匹配的最后一个字符之后插入新节点w,将边缘(u,v)分成两个边缘..m],并且在边缘上第一个不匹配的字符之前。新边(u,w)用与S [i + 1..m]匹配的(u,v)标签的一部分标记,新边(w,v)用(u,v)标签。
- 创建一个从w到标记为i + 1的新叶子的新边(w,i + 1),并用后缀S [i + 1..m]的不匹配部分标记新边。
这需要O(m 2 )来构建长度为m的字符串S的后缀树。
以下是基于上述算法为字符串“ xabxa $”构建后缀树的一些步骤: 

隐式后缀树
在使用Ukkonen算法生成后缀树时,根据字符串S中的字符,我们会在中间步骤中几次看到隐式后缀树。在隐式后缀树中,不会有带有$(或#或任何其他终止字符)标签的边,并且没有内部节点,其中只有一条边缘从中伸出。
要从后缀树S $获取隐式后缀树,
- 从树的边缘标签中删除所有终端符号$,
- 去除没有标签的任何边缘
- 删除任何只有一条边出的节点,然后合并这些边。
Ukkonen算法的高级描述
Ukkonen的算法为S(长度为m)的每个前缀S [1 ..i]构造一个隐式后缀树T i 。
它首先建立T 1使用1个字符,则T 2使用第2次的字符,则T 3使用第三字符,…,使用米的Tm个字符。
隐式后缀树T i +1是建立在隐式后缀树T i之上的。
S的真实后缀树是通过在T m上加上$来构建的。
在任何时候,Ukkonen的算法都会为到目前为止看到的字符建立后缀树,因此它具有在线属性,在某些情况下可能很有用。
花费的时间为O(m)。
Ukkonen的算法分为m个阶段(字符串中长度为m的每个字符一个阶段)
在阶段i + 1中,从树T i构建树T i +1。
每个阶段i + 1进一步分为i + 1个扩展,S [1..i + 1]的每个i + 1后缀一个。
在阶段i + 1的扩展j中,该算法首先从标有子串S [j..i]的根查找路径的末尾。
然后,通过在其末尾添加字符S(i + 1)来扩展子字符串(如果尚不存在)。
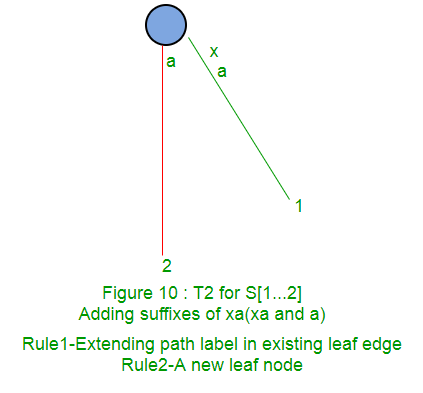
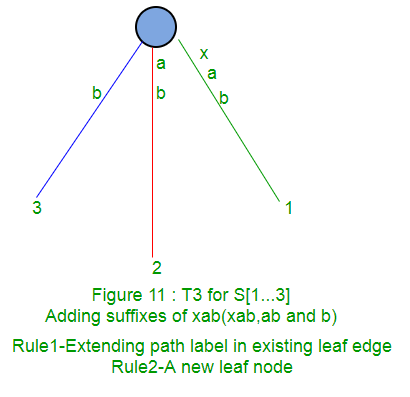
在阶段i + 1的扩展1中,我们将字符串S [1..i + 1]放入树中。由于前一阶段,此处的S [1..i]已经存在于树中。我们只需要在树中添加第S [i + 1]个字符(如果尚未添加)。
在阶段i + 1的扩展2中,我们将字符串S [2..i + 1]放入树中。由于先前的阶段i,此处的S [2..i]已经存在于树中。我们只需要在树中添加第S [i + 1]个字符(如果尚未添加)
在阶段i + 1的扩展3中,我们将字符串S [3..i + 1]放入树中。由于先前的第i阶段,此处的S [3..i]已经存在于树中。我们只需要在树中添加第S [i + 1]个字符(如果尚未添加)
。
。
在阶段i + 1的扩展i + 1中,我们将字符串S [i + 1..i + 1]放入树中。这是可能无法在树(如果字符被认为是第一次至今)只是一个字符。如果是这样,我们只需添加带有标签S [i + 1]的新叶子边缘。
高级Ukkonen算法
构造树T 1
对于从1到m-1的i
开始{i + 1阶段}
对于j从1到i + 1
开始{扩展名j}
从当前树中标有S [j..i]的根查找路径的末尾。
通过添加字符S [i + 1]扩展该路径(如果尚不存在)
结尾;
结尾;
后缀扩展就是将下一个字符添加到到目前为止构建的后缀树中。
在阶段i + 1的扩展j中,算法找到S [j..i]的末尾(由于先前的阶段i而已在树中),然后扩展S [j..i]以确保后缀S [j..i + 1]在树中。
有3个扩展规则:
规则1 :如果从标有S [j..i]的根开始的路径在叶边缘结束(即S [i]是叶边缘上的最后一个字符),则仅将字符S [i + 1]添加到在那片叶子的边缘贴标签。
规则2 :如果从标记为S [j..i]的根开始的路径在非叶子边缘结束(即路径上S [i]之后有更多字符),而下一个字符不是s [i + 1],则从字符S [i + 1]开始创建带有标签s {i + 1]和数字j的新叶子边缘。
如果s [1..i]在非叶子边缘的内部(中间)结束,则还将创建一个新的内部节点。
规则3 :如果从标有S [j..i]的根开始的路径在非叶子边缘结束(即路径上S [i]之后有更多字符),而下一个字符是s [i + 1](已经在树),什么也不做。
这里要注意的重要一点是,从给定的节点(根节点或内部节点)开始,只有一个边缘从一个字符开始。从同一字符开始,从任何节点出的边都不会超过一个。
以下是使用Ukkonen算法的字符串xabxac的分步后缀树构造: 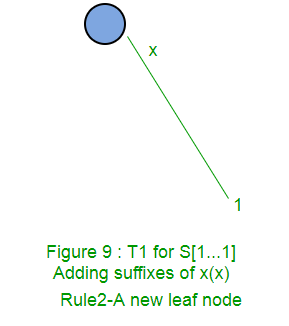

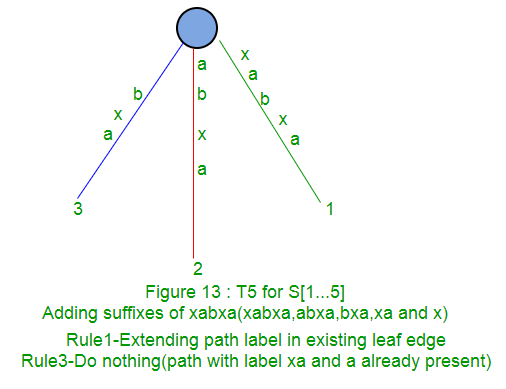
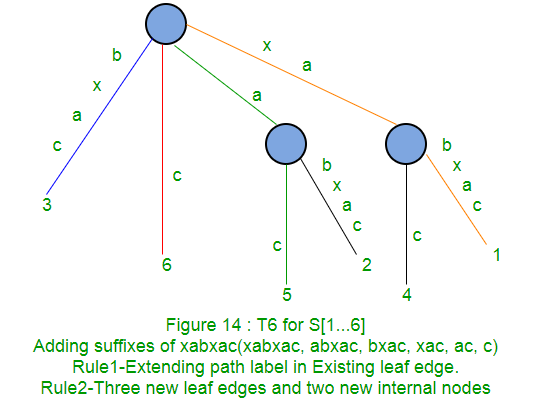
在接下来的部分(第2部分,第3部分,第4部分和第5部分)中,我们将讨论后缀链接,有效点,一些技巧以及最终的代码实现(第6部分)。
参考文献:
http://web.stanford.edu/~mjkay/gusfield.pdf