用Python介绍 Altair
Altair是Python中的统计可视化库。它本质上是声明式的,基于 Vega 和 Vega-Lite 可视化语法。它正迅速成为寻求快速有效数据集可视化方法的人们的首选。如果您使用过像 matplotlib 这样的命令式可视化库,您将能够正确地欣赏 Altair 的功能。
它被正确地视为声明性可视化库,因为在 Altair 中可视化任何数据集时,用户只需要指定数据列如何映射到编码通道,即声明数据列和编码通道(如 x 和 y 轴)之间的链接,行、列等。简单地框架化,声明性可视化库允许您专注于“什么”而不是“如何”部分,通过在没有用户帮助的情况下自行处理其他绘图细节。
相反,诸如matplotlib之类的命令式库强制您指定可视化的“方式”部分,这会从数据和它们之间的关系中转移注意力。这也使代码变得冗长且耗时,因为您必须自己指定详细信息,例如图例和轴名称。
安装
以下命令可用于像安装任何其他Python库一样安装 Altair:
pip install altair
我们将使用vega_datasets包中的数据集。要安装,应使用以下命令:
pip install vega_datasets
注意 - 应该使用Jupyter Notebook 来执行代码,因为可视化需要一个 Javascript 前端来显示图表。您可以参考以下文章了解如何使用 Jupyter Notebook:Jupyter Notebook 入门。您还可以使用 JupyterLab、Zeppelin 或任何其他笔记本环境或具有笔记本支持的 IDE。
Altair 图表的基本要素
所有 Altair 图表都需要三个基本元素:数据、标记和编码。也可以通过仅指定数据和标记来制作有效图表。
所有 Altair 图表的基本格式是:
alt.Chart(data).mark_bar().encode(
encoding1 = ‘column1’,
encoding2 = ‘column2’,
)
- 做一个图表。
- 传入一些数据。
- 指定所需的标记类型。
- 指定编码。
现在,让我们详细了解一下基本要素。
数据
数据集是您传递给图表的第一个参数。 Altair 中的数据是围绕 Pandas Dataframe 构建的,因此编码变得非常简单,它能够检测编码中所需的数据类型,但您也可以对数据使用以下内容:
- 数据或相关对象,例如 UrlData、InlineData、NamedData
- json 或 csv 格式的文本文件或 url
- 支持 __geo_interface__ 的对象(例如 Geopandas GeoDataFrame、GeoJSON Objects)
使用 DataFrames 将使过程更容易,因此您应该尽可能使用 DataFrames。
标记
Mark 属性指定数据应如何在图中表示。 Altair 中有多种可用的标记方法,格式如下:
mark_markname()
一些基本标记包括区域、条形、点、文本、刻度线和线。 Altair 还提供了一些复合标记,如箱线图、误差带和误差条。这些标记方法还可以接受可选参数,如颜色和不透明度。
使用 Altair 的主要优点之一是只需更改标记类型即可更改图表类型。
编码
可视化中最重要的事情之一是将数据映射到图表的视觉属性。 Altair 中的这种映射称为编码,通过Chart.encode() 方法执行。 Altair 中有多种类型的编码通道可用:位置通道、标记属性通道、超链接通道等。其中最常用的是来自位置通道的 x(x 轴值) 和 y(y 轴值)以及来自标记属性通道的颜色和不透明度。
好处
- 所有类型的图的基本代码保持不变,用户只需更改标记属性即可获得不同的图。
- 与其他命令式可视化库相比,代码更短且更易于编写。用户可以专注于数据列之间的关系而忘记不必要的绘图细节。
- Faceting 和 Interactivity 非常容易实现。
例子
程序1:(简单条形图)
Python3
# Importing altair and pandas library
import altair as alt
import pandas as pd
# Making a Pandas DataFrame
score_data = pd.DataFrame({
'Website': ['StackOverflow', 'FreeCodeCamp',
'GeeksForGeeks', 'MDN', 'CodeAcademy'],
'Score': [65, 50, 99, 75, 33]
})
# Making the Simple Bar Chart
alt.Chart(score_data).mark_bar().encode(
# Mapping the Website column to x-axis
x='Website',
# Mapping the Score column to y-axis
y='Score'
)Python3
# Importing altair
import altair as alt
# Import data object from vega_datasets
from vega_datasets import data
# Selecting the data
iris = data.iris()
# Making the Scatter Plot
alt.Chart(iris).mark_point().encode(
# Map the sepalLength to x-axis
x='sepalLength',
# Map the petalLength to y-axis
y='petalLength',
# Map the species to shape
shape='species'
)输出:
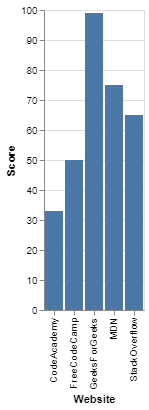
使用 Altair 的简单条形图
程序2:(散点图)
在这个例子中,我们将以散点图的形式可视化来自vega_datasets库的 iris 数据集。本例中用于散点图的标记方法是mark_point()。对于这个双变量分析,我们将 sepalLength 和 petalLength 列映射到 x 和 y 轴编码。此外,为了区分点,我们将形状编码映射到物种列。
蟒蛇3
# Importing altair
import altair as alt
# Import data object from vega_datasets
from vega_datasets import data
# Selecting the data
iris = data.iris()
# Making the Scatter Plot
alt.Chart(iris).mark_point().encode(
# Map the sepalLength to x-axis
x='sepalLength',
# Map the petalLength to y-axis
y='petalLength',
# Map the species to shape
shape='species'
)
输出:
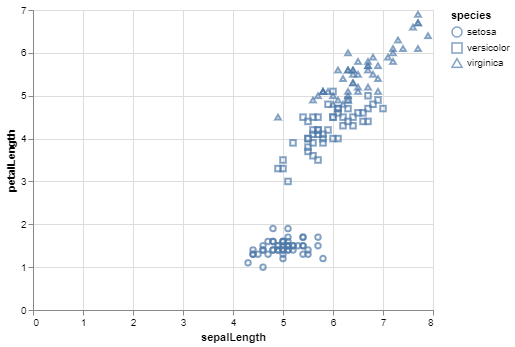
使用 Altair 绘制散点图