先决条件 – 递归下降解析器
1. 递归预测下降解析器:
递归下降解析器是一种自顶向下的语法分析方法,其中使用一组递归过程来处理输入。一个过程与文法的每个非终结符相关联。在这里,我们考虑一种称为预测递归下降解析器的递归下降解析的简单形式,其中前瞻符号明确地确定通过每个非终端的过程主体的控制流。分析输入字符串期间的过程调用序列隐式定义了输入的解析树,如果需要,可用于构建显式解析树。在递归下降解析中,解析器可能有多个产品可供选择,用于单个输入实例,回溯的概念开始发挥作用。
回溯——
这意味着,如果产生式的一个派生失败,语法分析器将使用相同产生式的不同规则重新启动过程。这种技术可能会多次处理输入字符串以确定正确的产生式。自顶向下的解析器从根节点(起始符号)开始并将输入字符串与产生式规则匹配以替换它们(如果匹配)。
要理解这一点,请看以下 CFG 示例:
S -> aAb | aBb
A -> cx | dx
B -> xe 对于输入字符串——read,一个自顶向下的解析器,会像这样。
它将从产生式规则中的 S 开始,并将其产量与输入的最左侧字母相匹配,即“a”。 S (S -> aAb) 的产生与它相匹配。所以自顶向下的解析器前进到下一个输入字母(即“d”)。解析器尝试扩展非终结符 ‘A’ 并从左侧检查其产生式 (A -> cx)。它与下一个输入符号不匹配。所以自顶向下的解析器回溯以获得 A 的下一个产生式规则,(A -> dx)。
现在解析器以有序的方式匹配所有输入字母。字符串被接受。

2.非递归预测下降解析器:
一种不需要任何回溯的递归下降解析形式称为预测解析。它也被称为 LL(1) 解析表技术,因为我们将为要解析的字符串构建一个表。它有能力预测将使用哪个产生式来替换输入字符串。为了完成它的任务,预测解析器使用一个前瞻指针,它指向下一个输入符号。为了使解析器回溯自由,预测解析器对文法施加了一些限制,并且只接受一类称为 LL(k) 文法的文法。
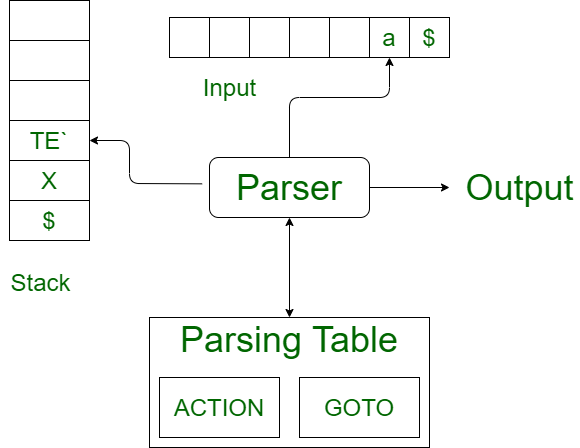
预测解析使用堆栈和解析表来解析输入并生成解析树。堆栈和输入都包含一个结束符号 $ 来表示堆栈为空并且输入已被消耗。解析器参考解析表对输入和堆栈元素组合做出任何决定。可能存在没有生产匹配输入字符串,使解析过程失败。
递归预测下降解析器和非递归预测下降解析器的区别:
|
Recursive Predictive Descent Parser |
Non-Recursive Predictive Descent Parser |
|---|---|
| It is a technique which may or may not require backtracking process. | It is a technique that does not require any kind of backtracking. |
| It uses procedures for every non-terminal entity to parse strings. | It finds out productions to use by replacing input string. |
| It is a type of top-down parsing built from a set of mutually recursive procedures where each procedure implements one of non-terminal s of grammar. | It is a type of top-down approach, which is also a type of recursive parsing that does not uses technique of backtracking. |
| It contains several small functions one for each non- terminals in grammar. | The predictive parser uses a look ahead pointer which points to next input symbols to make it parser back tracking free, predictive parser puts some constraints on grammar. |
| It accepts all kinds of grammars. | It accepts only a class of grammar known as LL(k) grammar. |