粗糙集的概念是由 Z Pawlak 在 1982 年的开创性论文(Pawlak 1982)中引入的。它是一种形式理论,源自对信息系统逻辑特性的基础研究。粗糙集理论一直是关系数据库中数据库挖掘或知识发现的方法。就其抽象形式而言,它是与模糊理论密切相关的不确定性数学的一个新领域。我们可以使用粗糙集方法来发现不精确和嘈杂数据中的结构关系。
粗糙集和模糊集是经典集的互补推广。粗糙集理论的近似空间是具有多个隶属关系的集合,而模糊集则涉及部分隶属关系。这两种方法的快速发展为 Lotfi A. Zadeh 发起的“软计算”提供了基础。软计算包括粗糙集、至少模糊逻辑、神经网络、概率推理、信念网络、机器学习、进化计算和混沌理论。
Rough Set解决的数据分析基本问题:
- 根据属性值表征一组对象。
- 查找属性之间的依赖关系。
- 减少多余的属性。
- 寻找最重要的属性。
- 决策规则生成。
粗糙集理论的目标 –
- 粗糙集分析的主要目标是归纳(学习)概念的近似。粗糙集构成了 KDD 的良好基础。它提供了数学工具来发现隐藏在数据中的模式。
- 可用于特征选择、特征提取、数据约简、决策规则生成、模式提取(模板、关联规则)等。
- 识别数据中的部分或全部依赖关系,消除冗余数据,提供处理空值、缺失数据、动态数据等的方法。
信息系统 –
在 Rough Set 中,数据模型信息存储在表中。每行(元组)代表一个事实或一个对象。事实往往相互不一致。在粗糙集术语中,数据表称为信息系统。
因此,信息表表示从任何域收集的输入数据。 
注意:表的行称为示例(对象、实体)。
信息系统是一对 (U, A),U 是一个非空的有限对象集,A 是一个非空的有限属性集。 A 的元素称为条件属性。
包含决策属性/属性的信息表有时称为决策表。决策系统是一对(U, A union {d}) ,其中 d 是决策属性(我们可以考虑更多决策属性而不是一个)。 
不可分辨——
表可能包含许多具有相同特征的对象。减少表大小的一种方法是为每组具有相同特征的对象只存储一个代表对象。这些对象称为不可分辨对象或元组。
对于任何 P 子集 A,都存在相关的等价关系 IND(P): ![]()
其中 IND(P) 被称为关系的不可分辨性。这里 x 和 y 通过属性 P 彼此不可区分。

在上面的例子中,
IND({p1}) = {{O1, O2}, {O3, O5, O7, O9, O10}, {O4, O6, O8}}
O1 and O2 are characterized by the same values of attribute p1 and the value is 1.
O3, O5, O7, O9, O10 are characterized by the same value of attribute p1 and the value is 2.
O4, O6, O8 are characterized by the same value of attribute p1 and the value is 0.
不可分辨关系是等价关系。不可分辨的集合称为基本集合。
近似值——
它是由其两个近似值定义的清晰集合的形式近似值 –上近似值和下近似值。
- 上近似是可能属于目标集的对象集。

- 下近似值是肯定属于目标集的对象集。
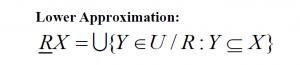
![]() represents the positive region which contains the objects definitely belonging to the target set X.
represents the positive region which contains the objects definitely belonging to the target set X.![]() represents the negative region which contains the objects that can be definitely ruled out as a member of the target set X.
represents the negative region which contains the objects that can be definitely ruled out as a member of the target set X.![]() represents the boundary region which contains the objects that may or may not belong to the target set X.
represents the boundary region which contains the objects that may or may not belong to the target set X.
如果一个集合的边界区域非空,则称该集合是粗糙的,否则该集合是清晰的。 
让我们讨论一个例子。前表被视为信息表。  参考:
参考:
http://zsi.tech.us.edu.pl/~nowak/bien/w2.pdf
https://www.sciencedirect.com/science/article/pii/S2468232216300786
https://www.mimuw.edu.pl/~son/datamining/RSDM/Intro.pdf