在上一篇文章中,我们讨论了假设检验,它是推理统计的支柱。我们之前讨论了基本假设检验,包括零假设和替代假设、z 检验等。现在,在此讨论更多类型 I 和类型 II 错误、显着性水平 (alpha) 和功率 (beta)。
P值:
p 值定义为获得结果的概率或比在正态分布中实际观察到的结果更极端的概率。一般来说,我们取显着性水平=0.05,这意味着如果观察到的p值小于显着性水平,那么我们拒绝原假设。
要计算 p 值,我们需要表特定的检验统计量(t 检验、z 检验、f 检验)以及它是否是单尾、双尾检验。
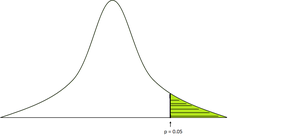
p值
Alpha 和 Beta 测试:
| Null Hypothesis is TRUE | Null Hypothesis is FALSE | |
|---|---|---|
| Reject Null Hypothesis |
Type I Error |
Correct decision
|
| Fail to Reject the Null Hypothesis |
Correct decision |
Type II error
|
- 类型 I 错误 (Alpha):现在,如果我们基于 p 值计算的显着性水平拒绝原假设,则样本实际上可能属于相同(原)分布,而我们错误地拒绝了它,这称为 I 型错误,用 alpha 表示
- Type II Error (Beta) :现在,根据显着性水平和 p 值,如果我们接受一个并不真正属于同一分布的样本,则称为 Type II 错误

功率和置信区间:
- 置信区间:置信区间是我们可以自信地拒绝零假设的区域。它是通过减去 alpha 和 1 来计算的
- 功率:功率是正确拒绝零假设并接受备择假设(H A)的概率。可以通过从 1 中减去 beta 来计算功率。
功效越高,犯第二类错误的概率就越低。较低的功率意味着执行 II 类错误的风险较高,反之亦然。通常,0.80 的功率被认为足够好。功率还取决于以下因素:
- 效应量:效应量只是衡量两个变量之间关系强度的方式。计算效果大小的方法有很多种,例如用于计算两个变量之间相关性的 Pearson 相关系数、用于测量组间差异的 Cohen’s d 检验,或者简单地通过计算不同组的均值之间的差异。
- 样本量: 包含在统计样本中的观察数。
- 显着性:测试中使用的显着性水平 (alpha)。
执行功率分析的步骤
- 陈述原假设 (H 0 ) 和替代假设 (H A )。
- 说明 alpha 风险水平(显着性水平)。
- 选择适当的统计检验。
- 决定效果大小。
- 制定抽样计划并确定样本量。之后收集样本。
- 通过确定 p 值来计算检验统计量。
- 如果 p 值 < alpha,那么我们拒绝原假设。
- 重复上述步骤几次。
例子
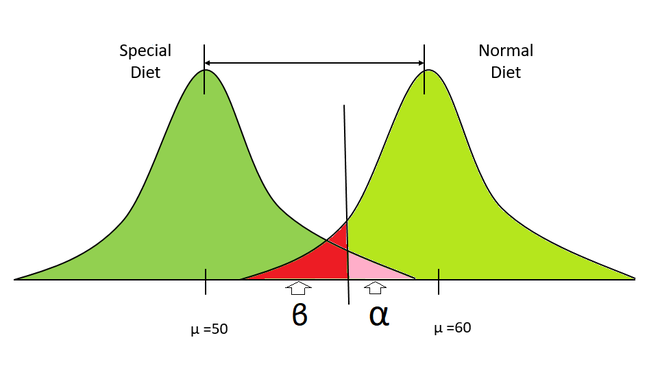
特殊饮食分布与正常饮食分布
- 假设有两个分布代表两组人的体重,左边代表节食的人,右边代表吃正常食物的人。
- 我们从两个分布中抽取一些样本并计算它们的均值。
- 在这里,我们的原假设是两个样本都来自相同的分布(没有饮食计划的影响),替代假设是两个样本都来自不同的分布。
- 现在,我们从这些样本中计算 p 值。
- 如果我们的 p 值小于显着性水平,那么我们正确地拒绝了这两个样本来自同一分布的原假设。
- 否则,我们不拒绝原假设。
- 现在,我们多次重复上述步骤(即 1000、10000)等,并计算正确拒绝零假设即 Power 的概率。
执行:
Python3
# Necessary Imports
import numpy as np
from statsmodels.stats.power import TTestIndPower
import matplotlib.pyplot as plt
# here effect size is taken as (u1-u2) /sd
effect_size = (60-50)/10
alpha = 0.05
samples =20
p_analysis = TTestIndPower()
power = p_analysis.solve_power(effect_size=effect_size, alpha=alpha, nobs1 = samples, ratio =1)
print("Power is ",power)0.8689530131730794