对于理解机器学习背后的概念以及深度学习,线性代数原理至关重要。线性代数是数学的一个分支,它允许以简洁的方式定义和执行高维坐标和平面相互作用的运算。它的主要重点是线性方程组。
在本文中,将讨论 –
- 基向量背后的想法?
- 基向量的定义
- 基向量的性质
- 给定空间的基向量
- 从数据科学的角度来看,这很重要
基向量背后的想法是什么?
所以,这里的想法如下, 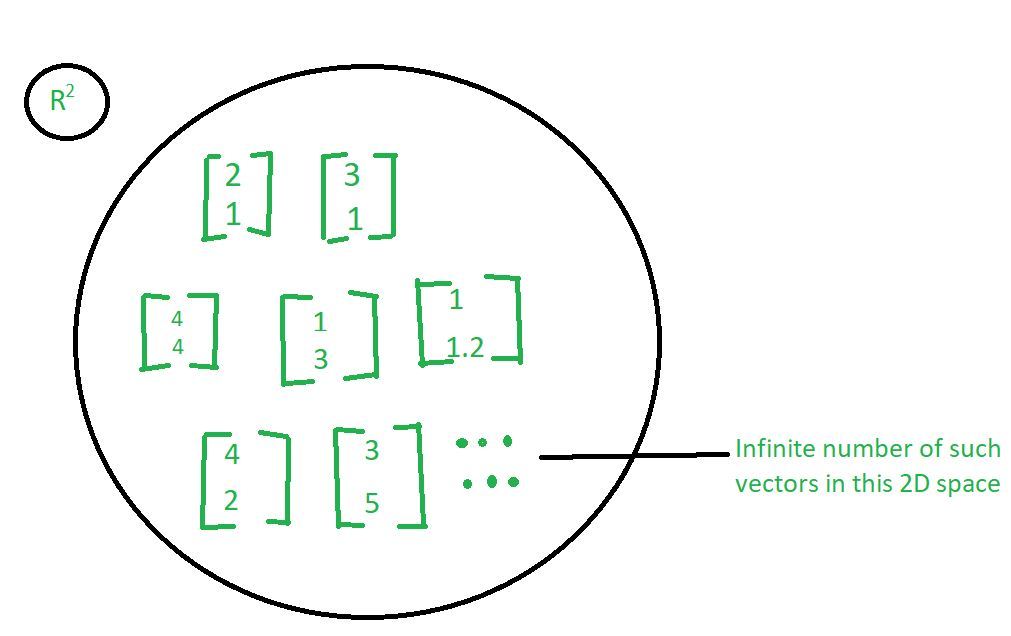
让我们取一个 R 平方空间,这基本上意味着,我们正在查看二维向量。这意味着正如我们在上图中所看到的那样,这些向量中的每一个都有 2 个分量。我们可以采用许多向量。因此,将有无限数量的向量,它们是二维的。所以,关键是我们可以使用一些基本元素,然后是这些基本元素的某种组合来表示所有这些向量。
现在,让我们以 2 个向量为例, 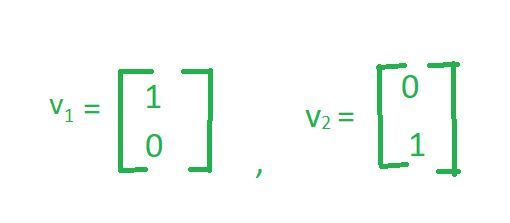
现在,如果你采用 R 平方空间中给出的任何向量,让我们说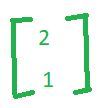
我们可以将这个向量写成一些线性组合,这个向量加上这个向量如下。 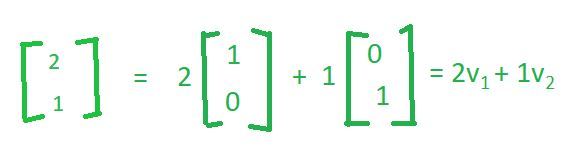
同样,如果你取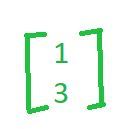
我们也可以将这个向量写成一些线性组合,这个向量加上这个向量如下。 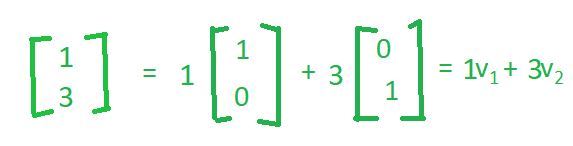
相似地, 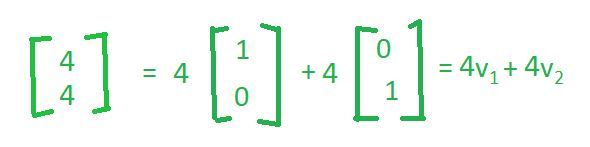
这对于您在此空间中拥有的任何向量都是正确的。
因此,在某种意义上,我们所说的是这两个向量( v1 和 v2 )表征空间或者它们构成空间的基,并且该空间中的任何向量都可以简单地写为这两个向量的线性组合。现在您可以注意到,线性组合实际上是数字本身。因此,例如,如果我希望将vector(2, 1)写为 vector(1, 0)和vector(0, 1)的线性组合,则标量倍数为2和1 ,这与vector( 4、4)等。
所以,关键是虽然我们这里有无数个向量,但它们都可以作为 2 个向量的线性组合生成,我们在这里看到这 2 个向量是vector(1, 0)和vector(0, 1) 。现在,这两个向量呼吁整个空间的基础。
基向量的定义:如果您可以将给定空间中的每个向量写成一些向量的线性组合,并且这些向量彼此独立,那么我们将它们称为该给定空间的基向量。
基向量的性质:
- 基向量必须彼此线性无关:
如果我将 v1 乘以任何标量,我将永远无法得到向量 v2。这证明了 v1 和 v2 彼此线性无关。我们希望基向量彼此线性无关,因为我们希望每个向量,即在生成唯一信息的基础上。如果它们变得相互依赖,那么这个向量就不会带来任何独特的东西。 - 基向量必须跨越整个空间:
单词跨度基本上意味着该空间中的任何向量,我都可以写成基向量的线性组合,就像我们在前面的例子中看到的那样。 - 基向量不是唯一的:人们可以找到许多组基向量。唯一的条件是它们必须是线性独立的并且应该跨越整个空间。因此,让我们通过与之前采用的相同的示例来详细了解此属性。
让我们考虑另外 2 个相互线性无关的向量。
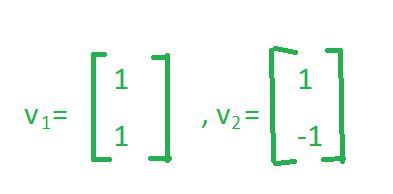
首先我们必须检查这两个向量是否符合基向量的性质?
您可以看到这两个向量彼此线性无关,因为将 v1 乘以任何标量永远无法得到向量 v2。因此,例如,如果我将 v1 乘以 -1,我将得到vector(-1, -1) ,但不会得到vector(1, -1) 。为了验证第二个属性,让我们采用vector(2, 1) 。现在,让我们看看我们是否可以将这个vector(2, 1) 表示为 vector(1, 1)和vector(1, -1)的线性组合。
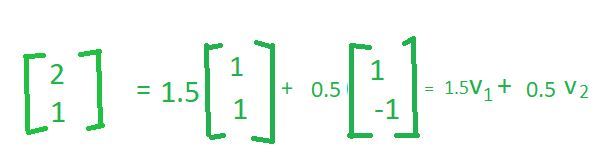
所以,如果你看看这个,我们已经成功地将这个vector(2, 1) 表示为 vector(1, 1)和vector(1, -1)的线性组合。你可以注意到,在前面的例子中,当我们使用vector(1, 0)和vector(0, 1) 时,我们说这可以写成vector(1, 0) 的2 次和vector(0, 1) ;然而,现在数字发生了变化。尽管如此,我可以将其写为这两个基向量的线性组合。
同样,如果你取向量(1,3)
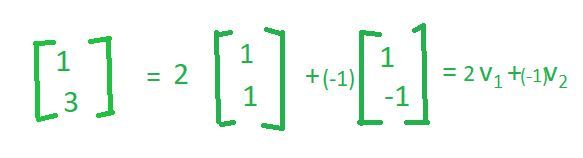
同样,如果你取向量(4,4)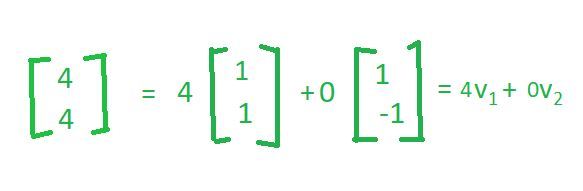
所以,这是相同基向量的另一个线性组合。所以,我想在这里提出的关键点是基向量不是唯一的。有很多方法可以定义基向量;然而,它们都具有相同的属性,如果我有一组向量,我称之为基向量,那么这些向量必须相互独立,并且它们应该跨越整个空间。因此,这个 v1 和 v2 也是 R 2 的基向量。
要记住的要点:
这里要注意的一件有趣的事情是,我们不能有 2 个具有不同向量数量的基组。我的意思是在前面的例子中,尽管基向量是v1(1, 0)和v2(0, 1) ,但只有 2 个向量。类似地,在这种情况下,基向量是v1(1, 1)和v2(1, -1) 。但是,仍然只有 2 个向量。因此,虽然您可以拥有多组基向量,但所有这些都等价于每组中向量的数量将相同,但它们不能不同。所以你应该记住的事情是,对于相同的空间,你不能有 2 个基组,一个带有 n 个向量,另一个带有 m 个向量,这是不可能的。所以,如果是同一个空间的基本集合,那么每个集合中向量的个数应该是一样的。
查找基向量:
让我们以 R 4空间为例。这实际上意味着每个向量中有 4 个分量。 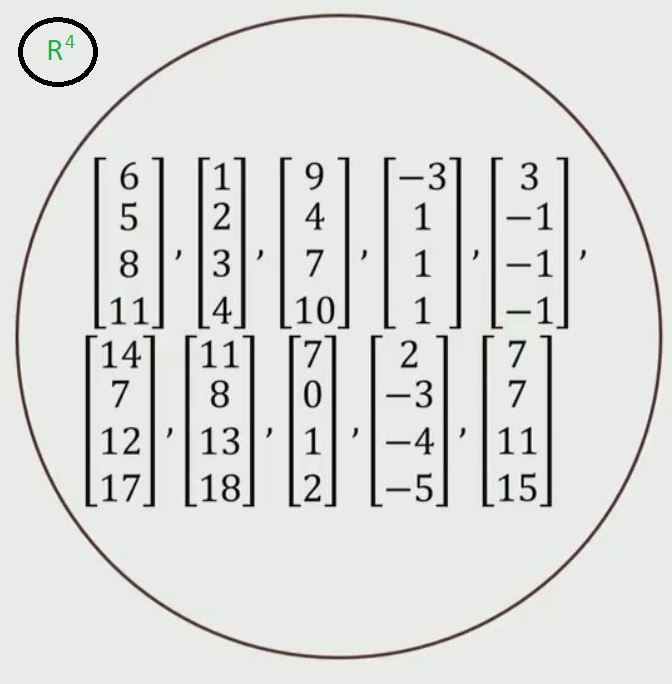
- 步骤 1:要找到给定向量集的基向量,按矩阵形式排列向量,如下所示。
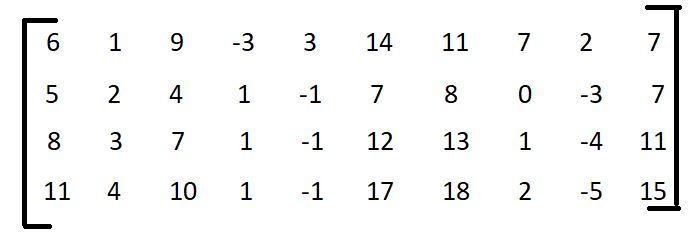
- 第二步:求这个矩阵的秩。
如果您确定该矩阵的秩,它将为您提供线性独立列的数量。矩阵的秩会告诉我们,有多少列是解释所有这些列的基础,以及我们需要多少列。因此,我们可以将剩余的列生成为这些列的线性组合。要找出矩阵的秩,请参阅此链接。因此,为此,矩阵的秩为 2。
- 第 3 步:
可以从上述矩阵中选取任意两个独立的列作为基向量。
解释:
如果矩阵的秩为 1,则我们只有 1 个基向量,如果秩为 2,则有 2 个基向量,如果为 3,则有 3 个基向量,依此类推。在这种情况下,由于矩阵的秩为 2,因此我只需要 2 个列向量来表示该矩阵中的每一列。因此,基组的大小为 2。因此,我们可以在这里选择任意 2 个线性无关的列,然后这些列可以作为基向量。
因此,例如,我们可以选择v1(6, 5, 8, 11)和v2(1, 2, 3, 4)并且说,这是所有这些列的基向量,或者我们可以选择v1(3, -1, -1, -1)和v2(7, 7, 11, 15)等等。我们可以选择任意 2 列,只要它们彼此线性无关,这是我们从上面知道的,基向量不需要是唯一的。所以,我选择任何 2 个线性独立的列来表示这些数据。
从数据科学的角度来看很重要
现在,让我向您解释为什么从数据科学的角度来看,这个基向量概念非常重要。看看前面的例子。我们有 10 个样本,我们想要存储这 10 个样本,因为每个样本有 4 个数字,我们将存储 4 x 10 = 40 个数字。
现在,让我们假设我们对这 10 个样本进行相同的练习,然后我们发现我们只有 2 个基向量,这将是该集合中的 2 个向量。我们可以做的是,我们可以存储这 2 个基向量,它们将是 2 x 4 = 8 个数字,对于剩下的 8 个样本,而不是存储所有样本和每个样本中的所有数字,我们可以做什么对于每个样本,我们只能存储 2 个数字,这些数字是我们将用来构建它的线性组合。所以,不是存储这 4 个数字,我们可以简单地存储这 2 个常数,因为我们已经存储了基向量,每当我们想要重构它时,我们可以简单地取第一个常数并将其乘以 v1 加上第二个常数乘法它通过 v2,我们将得到这个数字。
所以总结一下,
We store 2 basis vectors which give me: 4 x 2 = 8 numbers
And then for the remaining 8 samples, we simply store 2 constants e.g: 8 x 2 = 16 numbers
So, this would give us: 8 + 16 = 24 numbers
Hence instead of storing 4 x 10 = 40 numbers, we can store only 24 numbers, which is the approximately half reduction in number. And we will be able to reconstruct the whole data set by storing only 24 numbers.
因此,例如,如果您有一个 30 维向量,而基向量仅为 3,那么您可以看到数据存储方面的缩减类型。所以,这是数据科学的一种观点。
为什么数据存储的减少将从数据科学的观点中受益?
根据数据的基本特征来理解和表征数据非常重要。所以,你可以存储更少的东西,我们可以做更智能的计算,还有很多其他的原因让我们想要这样做,
- 您可以识别此基础以识别此数据之间的模型。
- 您可以确定在数据中进行降噪的基础。