介绍
顾名思义,分类是将事物“分类”为子类别的任务。但是,通过机器!如果这听起来并不多,想象一下您的计算机能够区分您和陌生人。在土豆和西红柿之间。在 A 级和 F- 之间。
是的。现在听起来很有趣!
在机器学习和统计中,分类是根据包含观察值的训练数据集以及其类别成员资格已知来识别新观察值属于一组类别(子种群)中的哪一个的问题。
分类类型
分类有两种:
- 二元分类:当我们必须将给定的数据分为 2 个不同的类时。示例 – 根据一个人的特定健康状况,我们必须确定该人是否患有某种疾病。
- 多类分类:类的数量超过 2。例如——根据不同种类的花的数据,我们必须确定我们的观察属于哪个种类。
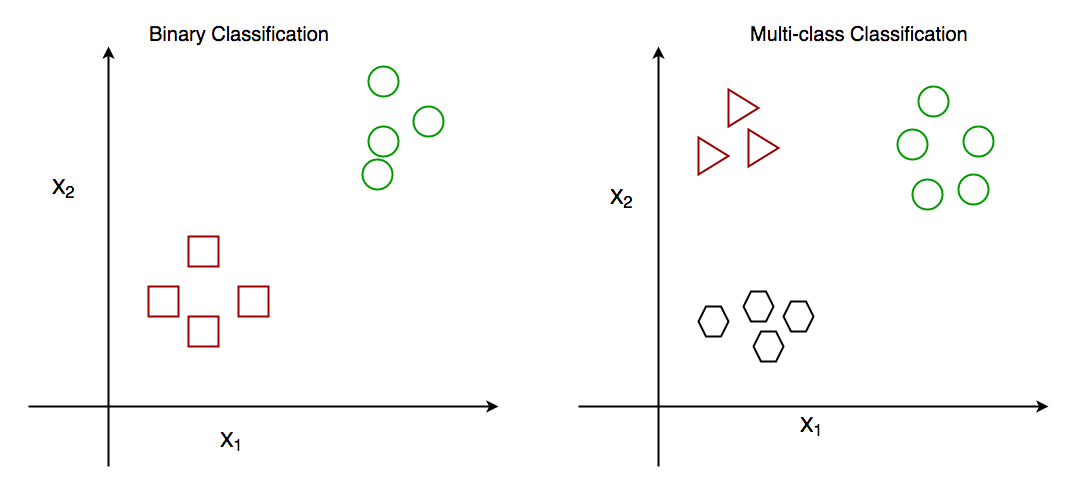
图:二元和多类分类。这里 x1 和 x2 是我们预测类别的变量。
分类是如何工作的?
假设我们必须根据称为特征的 3 个变量来预测给定患者是否患有某种疾病。
这意味着有两种可能的结果:
- 患者患有上述疾病。基本上是标记为“是”或“真”的结果。
- 患者无病。结果标记为“否”或“错误”。
这是一个二元分类问题。
我们有一组称为训练数据集的观察结果,其中包含具有实际分类结果的样本数据。我们在这个数据集上训练一个名为 Classifier 的模型,并使用该模型来预测某个患者是否会患病。
结果,因此现在取决于:
- 这些特征能够“映射”到结果的程度如何。
- 我们数据集的质量。我所说的质量是指统计和数学质量。
- 我们的分类器如何很好地概括了特征和结果之间的这种关系。
- x1 和 x2 的值。
以下是分类任务的广义框图。
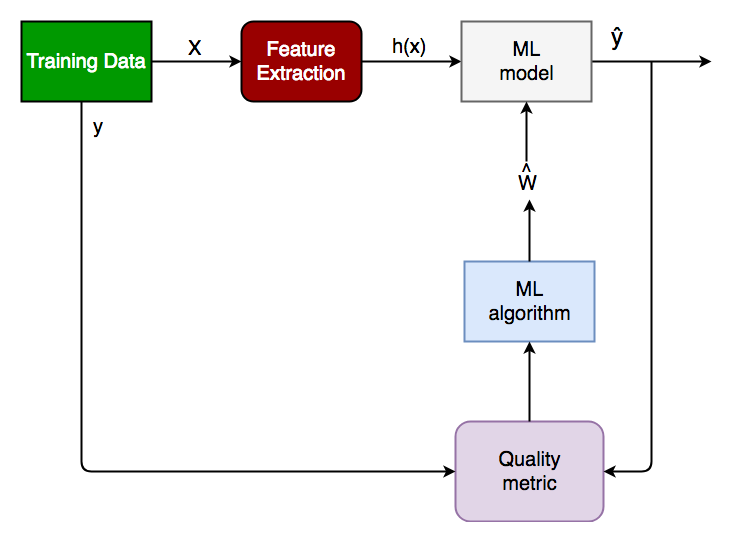
广义分类框图。
- X : 预先分类的数据,以 N*M 矩阵的形式。 N 是编号。观察的数量,M 是特征的数量
- y :Nd 向量对应于 N 个观察中的每一个的预测类别。
- 特征提取:使用一系列变换从输入 X 中提取有价值的信息。
- ML 模型:我们将训练的“分类器”。
- y’ : 分类器预测的标签。
- 质量指标:用于衡量模型性能的指标。
- ML 算法:用于更新权重 w’ 的算法,它更新模型并迭代地“学习”。
分类器的类型(算法)
有各种类型的分类器。他们之中有一些是 :
- 线性分类器:逻辑回归
- 基于树的分类器:决策树分类器
- 支持向量机
- 人工神经网络
- 贝叶斯回归
- 高斯朴素贝叶斯分类器
- 随机梯度下降 (SGD) 分类器
- 集成方法:随机森林、AdaBoost、装袋分类器、投票分类器、ExtraTrees 分类器
这些方法的详细描述超出了一篇文章!
分类的实际应用
- 谷歌的自动驾驶汽车使用支持深度学习的分类技术,使其能够检测和分类障碍物。
- 垃圾邮件过滤是分类技术最广泛和公认的用途之一。
- 检测健康问题、面部识别、语音识别、对象检测、情感分析都以分类为核心。
执行
让我们亲身体验一下分类的工作原理。我们将研究各种分类器,并在众所周知的标准数据集 Iris 数据集上查看它们的性能的相当简单的分析比较。
运行给定脚本的要求
- Python2.7
- Scipy 和 Numpy
- 用于数据可视化的 Matplotlib
- 用于数据输入/输出的 Pandas
- Scikit-learn 提供所有分类器
Python实现 – 项目的 Github 链接
结论
分类是一个非常广阔的研究领域。尽管它只包含机器学习的一小部分,但它是最重要的部分之一。
目前为止就这样了。在下一篇文章中,我们将看到分类在实践中是如何工作的,并了解Python代码。