在Python中使用 Plotly 的直方图
Plotly是一个Python库,用于设计图形,尤其是交互式图形。它可以绘制各种图形和图表,如直方图、条形图、箱线图、散布图等等。它主要用于数据分析和财务分析。 plotly 是一个交互式可视化库。
Plotly 中的直方图
直方图是存储数据并计算和表示每个存储数据的图形。更广泛地说,直方图是一个累积的条形图,具有几种可能的累积函数。要存储的数据可以是数值数据,也可以是分类数据或日期数据。它通常用于处理大量的集合数据。
Syntax: plotly.express.histogram(data_frame=None, x=None, y=None, color=None, facet_row=None, facet_col=None, facet_col_wrap=0, hover_name=None, hover_data=None, animation_frame=None, animation_group=None, category_orders={}, labels={}, color_discrete_sequence=None, color_discrete_map={}, marginal=None, opacity=None, orientation=None, barmode=’relative’, barnorm=None, histnorm=None, log_x=False, log_y=False, range_x=None, range_y=None, histfunc=None, cumulative=None, nbins=None, title=None, template=None, width=None, height=None)
Parameters:
data_frame: DataFrame or array-like needs to be passed for column names
x: Either a name of a column in data_frame, or a pandas Series or array_like object. Values from this column or array_like are used to position marks along the x axis in cartesian coordinates.
y: Either a name of a column in data_frame, or a pandas Series or array_like object. Values from this column or array_like are used to position marks along the y axis in cartesian coordinates.
color: Either a name of a column in data_frame, or a pandas Series or array_like object.
示例:使用提示数据集
Python3
import plotly.express as px
df = px.data.tips()
fig = px.histogram(df, x="total_bill")
fig.show()Python3
import plotly.express as px
df = px.data.tips()
fig = px.histogram(df, x="total_bill",
histnorm='probability density')
fig.show()Python3
import plotly.express as px
df = px.data.tips()
fig = px.histogram(df, x="total_bill", histnorm='percent')
fig.show()Python3
import plotly.express as px
df = px.data.tips()
fig = px.histogram(df, x="total_bill",
histnorm='percent',
nbins = 10)
fig.show()Python3
import plotly.express as px
df = px.data.tips()
fig = px.histogram(df, x="total_bill", color = "smoker")
fig.show()Python3
import plotly.express as px
df = px.data.tips()
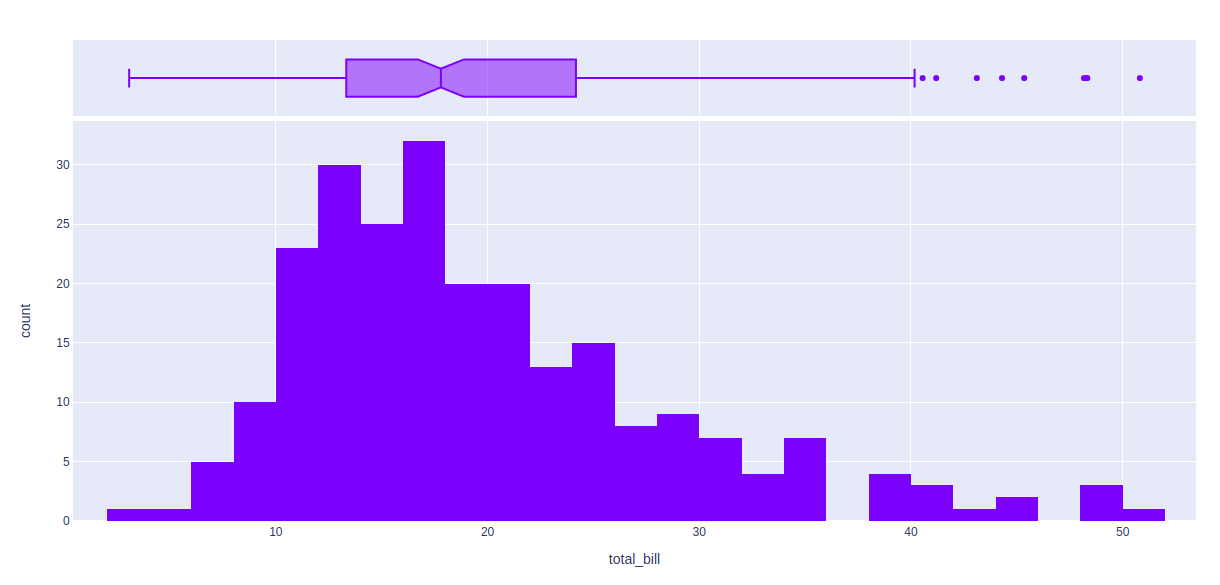
fig = px.histogram(df, x="total_bill", marginal = 'box')
fig.show()输出:

标准化类型
默认情况下,表示 bin 的模式是样本计数。我们可以使用 Plotly 更改此模式。 Ir=t 可以使用 histnorm 参数来完成。可以使用此参数传递的不同值是 -
- 百分比或概率:给定 bin 的 histfunc 输出除以所有 bin 的 histfunc 输出的总和。
- 密度:给定 bin 的 histfunc 的输出除以 bin 的大小。
- 概率密度:给定 bin 的 histfunc 的输出被归一化,使其对应于随机
示例 1:
Python3
import plotly.express as px
df = px.data.tips()
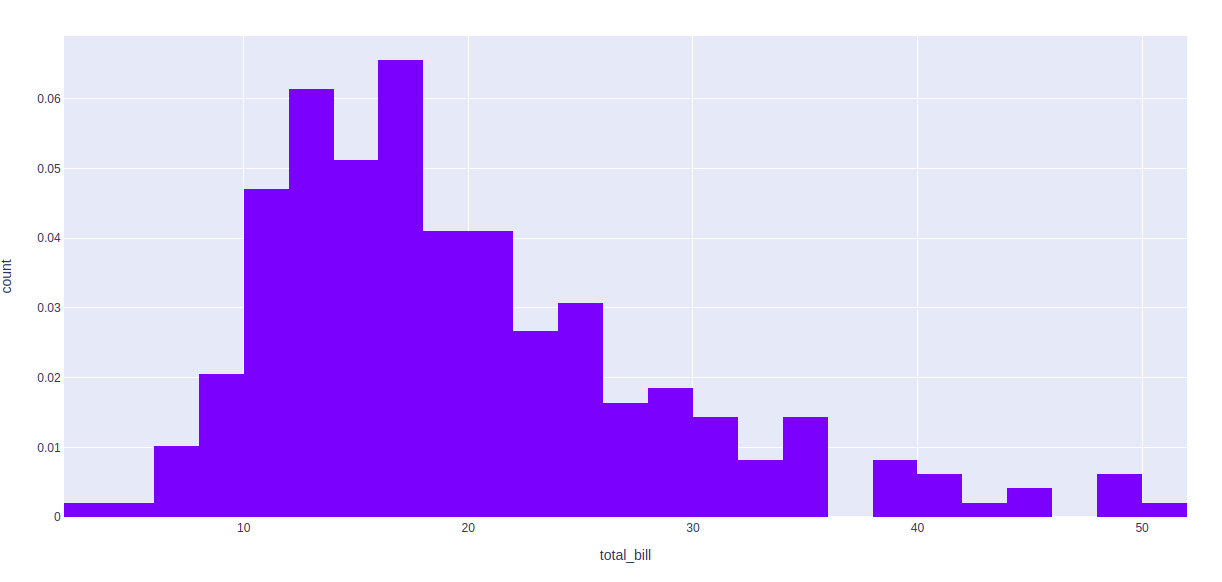
fig = px.histogram(df, x="total_bill",
histnorm='probability density')
fig.show()
输出:
示例 2:
Python3
import plotly.express as px
df = px.data.tips()
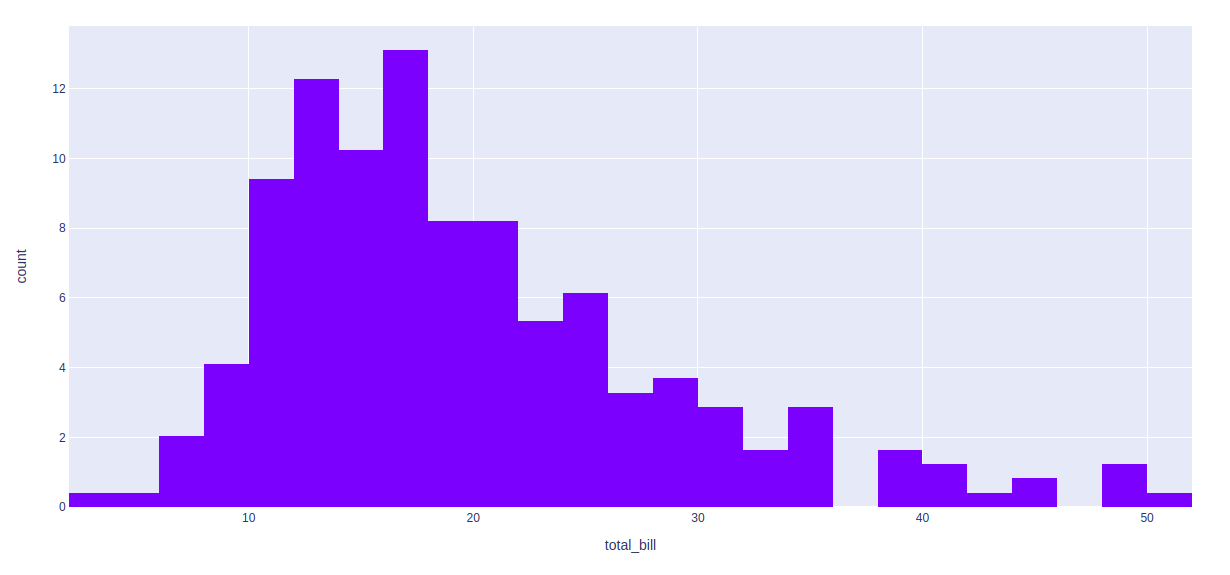
fig = px.histogram(df, x="total_bill", histnorm='percent')
fig.show()
输出:
选择 bin 数量
默认情况下,选择 bin 的数量使得该数量与 bin 中的典型样本数量相当。在 plotly 中,可以使用 nbins 参数自定义数量以及值的范围。
例子:
Python3
import plotly.express as px
df = px.data.tips()
fig = px.histogram(df, x="total_bill",
histnorm='percent',
nbins = 10)
fig.show()
输出:

直方图中的堆积值
通过使用颜色参数,可以在一列中显示不同的值。
例子:
Python3
import plotly.express as px
df = px.data.tips()
fig = px.histogram(df, x="total_bill", color = "smoker")
fig.show()
输出:

可视化底层分布
在情节中,通过使用边际参数,我们可以可视化值的分布。边际参数具有三个值:
- 小地毯
- 盒子
- 小提琴
例子:
Python3
import plotly.express as px
df = px.data.tips()
fig = px.histogram(df, x="total_bill", marginal = 'box')
fig.show()
输出: