Python| Pandas TimedeltaIndex.drop_duplicates
Python是一种用于进行数据分析的出色语言,主要是因为以数据为中心的Python包的奇妙生态系统。 Pandas就是其中之一,它使导入和分析数据变得更加容易。
Pandas TimedeltaIndex.drop_duplicates()函数返回删除重复值的索引。该函数提供了选择保留哪些重复值和删除哪些重复值的灵活性。
Syntax : TimedeltaIndex.drop_duplicates(keep=’first’)
Parameters :
keep : {‘first’, ‘last’, False}, default ‘first’
-> first : Drop duplicates except for the first occurrence.
-> last : Drop duplicates except for the last occurrence.
-> False : Drop all duplicates
Return : deduplicated : Index
示例 #1:使用TimedeltaIndex.drop_duplicates()函数从给定的 TimedeltaIndex 对象中删除所有重复值。只保留第一次出现。
# importing pandas as pd
import pandas as pd
# Create the TimedeltaIndex object
tidx = pd.TimedeltaIndex(data =['06:05:01.000030', '+23:59:59.999999',
'22 day 2 min 3us 10ns', '+23:59:59.999999',
'+23:29:59.999999', '+12:19:59.999999'])
# Print the TimedeltaIndex object
print(tidx)
输出 : 
现在我们将使用TimedeltaIndex.drop_duplicates()函数删除所有重复值,同时保留第一次出现。
# drop all duplicates and keep the first occurrence
tidx.drop_duplicates(keep ='first')
输出 : 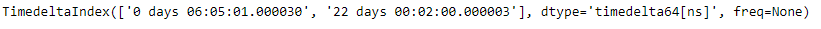
正如我们在输出中看到的, TimedeltaIndex.drop_duplicates()函数返回了一个新对象,该对象除了第一次出现之外,所有重复值都已删除。示例 #2:使用TimedeltaIndex.drop_duplicates()函数从给定的 TimedeltaIndex 对象中删除所有重复值。保留最后一个重复值。
# importing pandas as pd
import pandas as pd
# Create the TimedeltaIndex object
tidx = pd.TimedeltaIndex(data =['1 days 02:00:00', '1 days 06:05:01.000030',
'1 days 02:00:00', '1 days 02:00:00', '21 days 06:15:01.000030'])
# Print the TimedeltaIndex object
print(tidx)
输出 : 
现在我们将使用TimedeltaIndex.drop_duplicates()函数删除所有重复值,同时保留最后一次出现的值。
# drop all duplicates and keep the first occurrence
tidx.drop_duplicates(keep ='last')
输出 : 
正如我们在输出中看到的那样, TimedeltaIndex.drop_duplicates()函数返回了一个新对象,该对象除了最后一次出现之外,所有重复值都已删除。