📌 相关文章
- 批量梯度下降和随机梯度下降的区别(1)
- 批量梯度下降和随机梯度下降的区别
- PyTorch的梯度(1)
- PyTorch的梯度
- 批次梯度下降与随机梯度下降之间的区别
- 批次梯度下降与随机梯度下降之间的区别(1)
- 梯度下降的优化技术
- 梯度下降的优化技术
- 梯度下降的优化技术(1)
- 梯度下降的优化技术(1)
- TensorFlow-梯度下降优化
- 线性回归中的梯度下降
- 线性回归中的梯度下降(1)
- 梯度下降的矢量化(1)
- 梯度下降的矢量化
- 梯度下降算法及其变体(1)
- 梯度下降算法及其变体
- Scikit学习-随机梯度下降(1)
- Scikit学习-随机梯度下降
- 梯度下降法与正态方程的区别(1)
- 梯度下降法与正态方程的区别
- 如何在Python实现梯度下降以找到局部最小值?(1)
- 如何在Python实现梯度下降以找到局部最小值?
- ML | Python的小批量梯度下降(1)
- ML | Python的小批量梯度下降
- ML |随机梯度下降(SGD)(1)
- ML |随机梯度下降(SGD)
- 点梯度公式(1)
- 点梯度公式
📜 PyTorch梯度下降
📅 最后修改于: 2020-11-11 00:41:06 🧑 作者: Mango
PyTorch中的梯度下降
我们最大的问题是,我们如何训练模型以确定权重参数,以最小化误差函数。让我们开始介绍梯度下降如何帮助我们训练模型。
首先,当我们使用线性函数初始化模型时,线性模型将从随机初始参数调用开始。它确实给了我们一个随机的初始参数。
现在,基于与该初始参数A相关的误差,现在忽略偏差值。我们的动机是朝着使我们产生较小误差的方向运动。
如果我们采用误差函数的梯度作为切线在当前值处的切线的斜率的导数,则该导数会将我们带向最高误差的方向。
因此,我们将其移向渐变的负方向,这将使我们朝着最低误差的方向发展。我们以电流为权重,然后在同一点减去该函数的导数。
A1=A0-f'(A)
这将使我们朝着最小错误的方向发展。
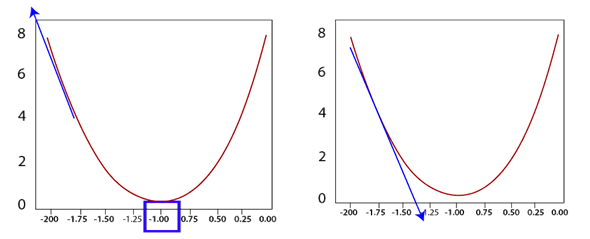
以总结的方式,首先,我们必须计算损失函数的导数,然后提交线的当前权重值。无论权重是多少,它们都会为您提供渐变值。然后从当前权重A0中减去该梯度值,得出新的更新权重A1。新的权重应导致比以前的误差更小的误差。我们将反复进行此操作,直到获得线模型的最佳参数以拟合数据为止。
但是,为了确保最佳效果,我们采用梯度下降。一个人应该以最少的步骤下降。这样,我们将梯度乘以一个称为学习率的最小值。学习率的值是经验值。尽管一个好的标准起始值往往是10分之一或100分之一,但是学习率必须足够小,因为随着直线的调整,您永远都不想在一个方向上急剧移动,因为这可能会导致不必要的发散行为。
在本文中,我们将学习根据经验结果调整收益率,稍后我们将编写梯度下降算法,但接下来我们将通过梯度下降示例进行介绍,让我们参考excel上的演示以直观地看到梯度下降的效果。
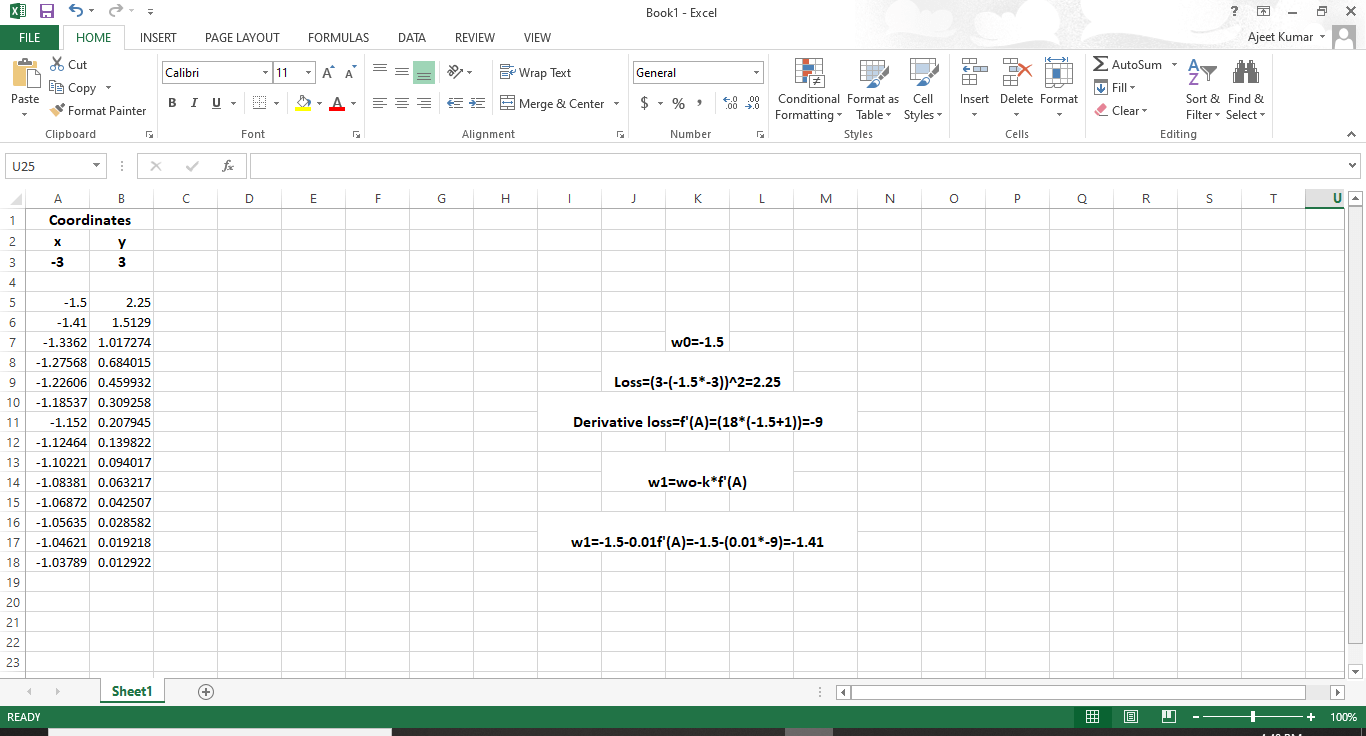
我们将在以后的代码中实现它。