为了训练线性回归模型,我们必须学习一些模型参数,例如特征权重和偏差项。梯度下降是实现此目的的一种方法,它是一种迭代优化算法,能够通过最小化火车数据上的成本函数来调整模型参数。这是一个完整的算法,即,如果有足够的时间并且学习率不是很高,则可以保证找到全局最小值(最优解)。在线性回归和神经网络中广泛使用的两个重要的梯度下降变体是批梯度下降和随机梯度下降(SGD)。
批梯度下降:批梯度下降涉及在每个步骤的整个训练集上进行的计算,因此,对于非常大的训练数据而言,它非常慢。因此,执行批处理GD在计算上变得非常昂贵。但是,这对于凸形或相对平滑的误差歧管非常有用。同样,批处理GD可以随着功能的数量而很好地扩展。
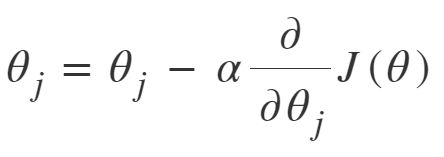
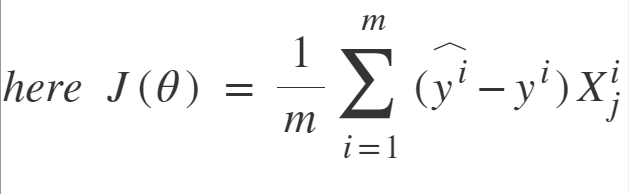
随机梯度下降: SGD尝试解决批量梯度下降中的主要问题,即使用整个训练数据来计算每个步骤的梯度。 SGD本质上是随机的,即,它与批次GD不同,它在每个步骤中都会选取一个“随机”的训练数据实例,然后计算梯度使其速度更快,因为一次只能处理更少的数据。
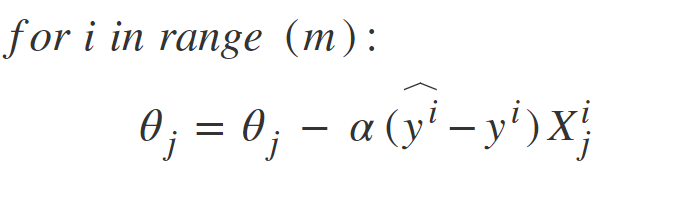
SGD的随机性有一个缺点,即一旦接近最小值,它就不会稳定下来,而是反弹,这给我们提供了很好的模型参数值,但不是最优值,可以通过减少学习来解决降低跳动的每一步的速率,一段时间后SGD可能会稳定在全球最低水平。
批次梯度下降与随机梯度下降之间的区别
| S.NO. | Batch Gradient Descent | Stochastic Gradient Descent |
|---|---|---|
| 1. | Computes gradient using the whole Training sample | Computes gradient using a single Training sample |
| 2. | Slow and computationally expensive algorithm | Faster and less computationally expensive than Batch GD |
| 3. | Not suggested for huge training samples. | Can be used for large training samples. |
| 4. | Deterministic in nature. | Stochastic in nature. |
| 5. | Gives optimal solution given sufficient time to converge. | Gives good solution but not optimal. |
| 6. | No random shuffling of points are required. | The data sample should be in a random order, and this is why we want to shuffle the training set for every epoch. |
| 7. | Can’t escape shallow local minima easily. | SGD can escape shallow local minima more easily. |
| 8. | Convergence is slow. | Reaches rthe convergence much faster. |