使用支持向量机预测股价方向
我们将使用支持向量机来实现一个端到端的项目来为我们进行交易。您可能一定听说过股票市场这个词,众所周知,它造就了数千人的生活,也摧毁了数百万人的生活。如果您不熟悉股票市场,您可以浏览一些有关市场的基本资料。
使用的工具和技术:
- Python
- Sklearn-支持向量分类器
- 雅虎财经
- Jupyter-笔记本
- 蓝移
分步实施
第 1 步:导入库
Python3
# Machine learning
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# For data manipulation
import pandas as pd
import numpy as np
# To plot
import matplotlib.pyplot as plt
plt.style.use('seaborn-darkgrid')
# To ignore warnings
import warnings
warnings.filterwarnings("ignore")Python3
# Read the csv file using read_csv
# method of pandas
df = pd.read_csv('RELIANCE.csv')
dfPython3
# Changes The Date column as index columns
df.index = pd.to_datetime(df['Date'])
df
# drop The original date column
df = df.drop(['Date'], axis='columns')
dfPython3
# Create predictor variables
df['Open-Close'] = df.Open - df.Close
df['High-Low'] = df.High - df.Low
# Store all predictor variables in a variable X
X = df[['Open-Close', 'High-Low']]
X.head()Python3
# Target variables
y = np.where(df['Close'].shift(-1) > df['Close'], 1, 0)
yPython3
split_percentage = 0.8
split = int(split_percentage*len(df))
# Train data set
X_train = X[:split]
y_train = y[:split]
# Test data set
X_test = X[split:]
y_test = y[split:]Python3
# Support vector classifier
cls = SVC().fit(X_train, y_train)Python3
df['Predicted_Signal'] = cls.predict(X)Python3
# Calculate daily returns
df['Return'] = df.Close.pct_change()Python3
# Calculate strategy returns
df['Strategy_Return'] = df.Return *df.Predicted_Signal.shift(1)Python3
# Calculate Cumulutive returns
df['Cum_Ret'] = df['Return'].cumsum()
dfPython3
# Plot Strategy Cumulative returns
df['Cum_Strategy'] = df['Strategy_Return'].cumsum()
dfPython3
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(Df['Cum_Ret'],color='red')
plt.plot(Df['Cum_Strategy'],color='blue')第 2 步:读取股票数据
我们将阅读从雅虎财经网站下载的股票数据。数据以 OHLC(开盘价、最高价、最低价、收盘价)格式存储在 CSV 文件中。要读取 CSV 文件,您可以使用 pandas 的 read_csv() 方法。
句法 :
pd.read_csv(filename, index_col)注:我们从雅虎财经网站下载了过去 1 年的 Reliance Industries Trading In NSE 数据。
使用的文件:
蟒蛇3
# Read the csv file using read_csv
# method of pandas
df = pd.read_csv('RELIANCE.csv')
df
输出:

第 3 步:数据准备
使用前需要处理的数据,以便日期列应作为索引来执行此操作
蟒蛇3
# Changes The Date column as index columns
df.index = pd.to_datetime(df['Date'])
df
# drop The original date column
df = df.drop(['Date'], axis='columns')
df
输出:
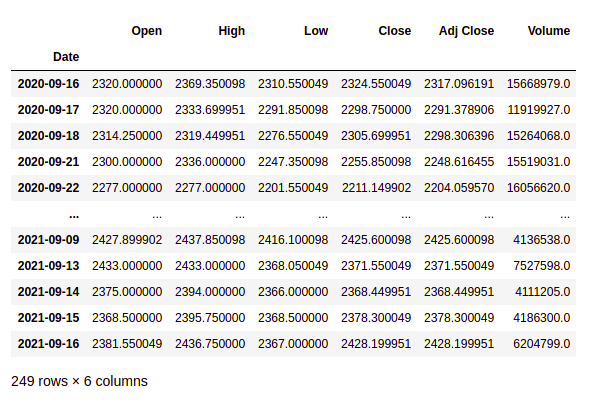
步骤 4:定义解释变量
解释变量或自变量用于预测值响应变量。 X 是一个包含用于预测的变量的数据集。 X 由变量组成,例如“开盘价 - 收盘价”和“最高价 - 最低价”。这些可以理解为算法预测明天趋势的指标。随意添加更多指标并查看性能
蟒蛇3
# Create predictor variables
df['Open-Close'] = df.Open - df.Close
df['High-Low'] = df.High - df.Low
# Store all predictor variables in a variable X
X = df[['Open-Close', 'High-Low']]
X.head()
输出:
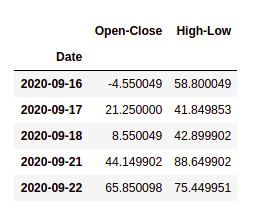
步骤 5:定义目标变量
目标变量是机器学习模型将根据解释变量预测的结果。 y 是一个目标数据集,存储机器学习算法将尝试预测的正确交易信号。如果明天的价格高于今天的价格,那么我们将购买特定的股票,否则我们将没有头寸。我们将在 y 中存储 +1 表示买入信号和 0 表示无头寸。我们将使用 NumPy 中的 where()函数来做到这一点。
句法:
np.where(condition,value_if_true,value_if_false)蟒蛇3
# Target variables
y = np.where(df['Close'].shift(-1) > df['Close'], 1, 0)
y
输出:

第 6 步:将数据拆分为训练和测试
我们将数据拆分为训练和测试数据集。这样做是为了我们可以评估模型在测试数据集中的有效性
蟒蛇3
split_percentage = 0.8
split = int(split_percentage*len(df))
# Train data set
X_train = X[:split]
y_train = y[:split]
# Test data set
X_test = X[split:]
y_test = y[split:]
第 7 步:支持向量分类器 (SVC)
我们将使用sklearn.svm.SVC库中的 SVC()函数在训练数据集上使用 fit() 方法创建我们的分类器模型。
蟒蛇3
# Support vector classifier
cls = SVC().fit(X_train, y_train)
第 8 步:分类器准确度
我们将在列车上计算算法的准确性,并通过比较信号的实际值与信号的预测值来测试数据集。函数accuracy_score() 将用于计算准确度。

测试数据中 50% 以上的准确率表明分类器模型是有效的。
第九步:战略实施
我们将使用 cls.predict()函数预测信号(买入或卖出)。
蟒蛇3
df['Predicted_Signal'] = cls.predict(X)
计算每日回报
蟒蛇3
# Calculate daily returns
df['Return'] = df.Close.pct_change()
计算策略回报
蟒蛇3
# Calculate strategy returns
df['Strategy_Return'] = df.Return *df.Predicted_Signal.shift(1)
计算累积回报
蟒蛇3
# Calculate Cumulutive returns
df['Cum_Ret'] = df['Return'].cumsum()
df
计算策略累积回报
蟒蛇3
# Plot Strategy Cumulative returns
df['Cum_Strategy'] = df['Strategy_Return'].cumsum()
df
绘制策略回报与原始回报
蟒蛇3
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(Df['Cum_Ret'],color='red')
plt.plot(Df['Cum_Strategy'],color='blue')
输出:
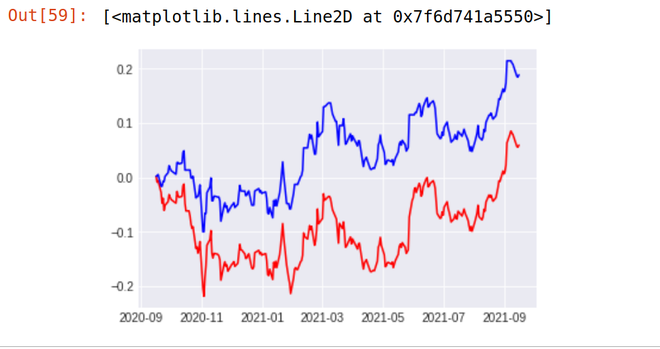
如您所见,我们的策略似乎完全优于 Reliance 股票的表现。我们的策略(蓝线)在过去 1 年的回报率为18.87% ,而 Reliance Industries (红线)的股票在过去 1 年的回报率仅为5.97% 。
回测结果
1. TCS
Stock Return Over Last 1 year - 48%
Strategy result - 48.9 %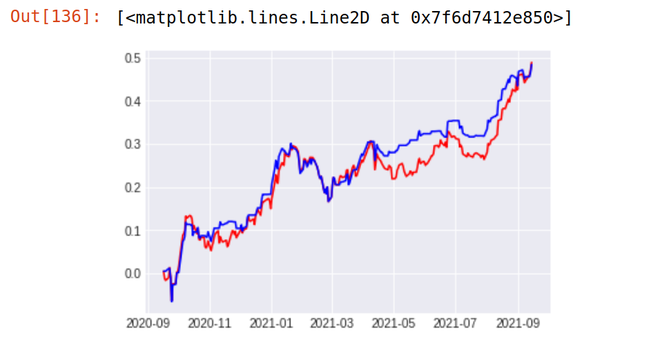
2.ICICI银行
Stock Return Over Last 1 year - 48%
Strategy result - 48.9 %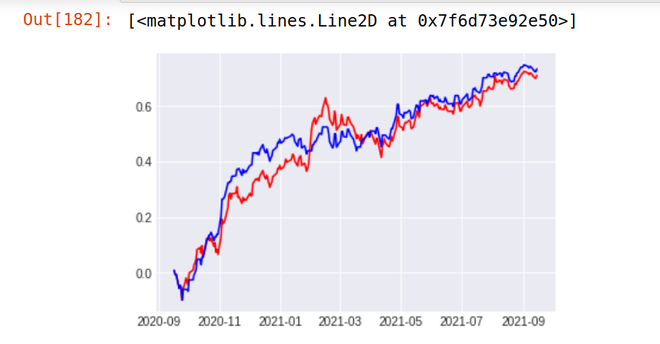
部署战略到活市场
编码策略可以轻松部署在实时市场中,也可以在整个交易所中对任意数量的数据进行回溯测试。使用 BlueShift 平台可以轻松完成部署。它是一个交互式平台,具有实时数据馈送和通过各种经纪人的连接。您可以使用来自不同交易所的数据在 BlueShift 平台上进行任意次数的回溯测试。
结论
- 策略提供者在实时市场中获得可观的回报。目前,我刚刚根据前一天的水平训练了模型,但是为了提高模型的准确性,我们还添加了各种技术指标来训练模型,例如 RSI、ADX、ATR、MACD、随机指标等等。
- 在实时市场中获得更高的准确性 深度学习被证明在实时市场交易中非常有效。我们可以使用强化学习来自动化我们的交易,也可以使用 Stacked LSTM 来使我们的策略回报呈指数增长。
注意:在完成对策略的回溯测试之前不应部署真钱,并且在纸交易期间没有策略的承诺回报