- 无监督学习
- 监督学习和无监督学习(1)
- 监督学习(1)
- 监督学习和无监督学习
- 有监督和无监督学习
- 有监督和无监督学习(1)
- 监督学习与无监督学习之间的区别
- 监督学习与无监督学习之间的区别(1)
- 监督学习与无监督学习之间的区别
- 监督学习与无监督学习之间的区别(1)
- R 编程中的有监督和无监督学习(1)
- R 编程中的有监督和无监督学习
- 无监督机器学习(1)
- 监督机器学习
- 机器学习-监督
- 机器学习-监督(1)
- 机器学习-无监督(1)
- 机器学习-无监督
- 无监督机器学习
- 毫升 |半监督学习(1)
- 毫升 |半监督学习
- ML |学习类型–监督学习(1)
- ML |学习类型–监督学习
- 带Python的AI –监督学习:回归
- 带Python的AI –监督学习:回归(1)
- 回归和分类 |监督机器学习(1)
- 回归和分类 |监督机器学习
- 带有Python的AI-无监督学习:聚类
- 带有Python的AI-无监督学习:聚类(1)
📅 最后修改于: 2020-11-26 08:30:30 🧑 作者: Mango
顾名思义,监督学习是在老师的监督下进行的。这个学习过程是依赖的。在监督学习下对ANN进行训练期间,将输入向量呈现给网络,网络将产生输出向量。将该输出向量与期望/目标输出向量进行比较。如果实际输出与期望/目标输出矢量之间存在差异,则会生成错误信号。基于该误差信号,将调整权重,直到实际输出与所需输出匹配为止。
感知器
感知器由Frank Rosenblatt使用McCulloch和Pitts模型开发,是人工神经网络的基本运算单元。它采用监督学习规则,并且能够将数据分为两类。
感知器的操作特征:它由单个神经元组成,该神经元具有任意数量的输入以及可调整的权重,但是神经元的输出取决于阈值,为1或0。它还包含一个权重始终为1的偏置。下图给出了感知器的示意图。
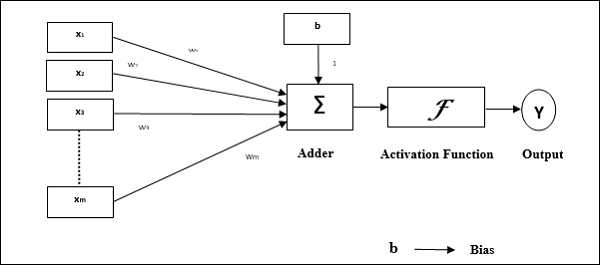
感知器因此具有以下三个基本元素-
-
链接-它会有一组连接链接,这些链接的权重包括始终为权重1的偏置。
-
加法器-将输入乘以各自的权重后,将输入相加。
-
激活函数-限制神经元的输出。最基本的激活函数是Heaviside步进函数,具有两个可能的输出。如果输入为正,则此函数返回1,如果输入为负,则返回0。
训练算法
Perceptron网络可以针对单个输出单元以及多个输出单元进行训练。
单输出单元训练算法
步骤1-初始化以下内容以开始训练-
- 重物
- 偏压
- 学习率$ \ alpha $
为了便于计算和简化,权重和偏差必须设置为0,学习率必须设置为1。
步骤2-如果停止条件不成立,则继续执行步骤3-8。
步骤3-对每个训练向量x继续步骤4-6。
步骤4-如下激活每个输入单元-
$$ x_ {i} \:= \:s_ {i} \ 🙁 i \:= \:1 \:to \:n)$$
步骤5-现在获得具有以下关系的净输入-
$$ y_ {in} \:= \:b \:+ \:\ displaystyle \ sum \ limits_ {i} ^ n x_ {i}。\:w_ {i} $$
在这里, “ b”是偏差, “ n”是输入神经元的总数。
步骤6-应用以下激活函数以获得最终输出。
$$ f(y_ {in})\:= \:\ begin {cases} 1&if \:y_ {in} \:> \:\ theta \\ 0&if \:-\ theta \:\ leqslant \ :y_ {in} \:\ leqslant \:\ theta \\-1&if \:y_ {in} \:
步骤7-如下调整权重和偏差-
情况1-如果y≠t ,
$$ w_ {i}(新)\:= \:w_ {i}(旧)\:+ \:\ alpha \:tx_ {i} $$
$$ b(新)\:= \:b(旧)\:+ \:\ alpha t $$
情况2-如果y = t ,
$$ w_ {i}(新)\:= \:w_ {i}(旧)$$
$$ b(新)\:= \:b(旧)$$
“ y”是实际输出, “ t”是期望/目标输出。
步骤8-测试停止条件,当重量没有变化时会发生这种情况。
多输出单元的训练算法
下图是用于多个输出类别的感知器的体系结构。
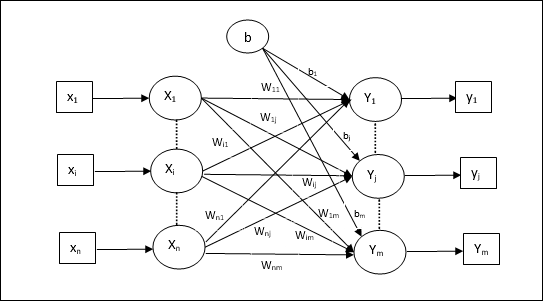
步骤1-初始化以下内容以开始训练-
- 重物
- 偏压
- 学习率$ \ alpha $
为了便于计算和简化,权重和偏差必须设置为0,学习率必须设置为1。
步骤2-如果停止条件不成立,则继续执行步骤3-8。
步骤3-对每个训练向量x继续步骤4-6。
步骤4-如下激活每个输入单元-
$$ x_ {i} \:= \:s_ {i} \ 🙁 i \:= \:1 \:to \:n)$$
步骤5-获得具有以下关系的净输入-
$$ y_ {in} \:= \:b \:+ \:\ displaystyle \ sum \ limits_ {i} ^ n x_ {i} \:w_ {ij} $$
在这里, “ b”是偏差, “ n”是输入神经元的总数。
步骤6-应用以下激活函数以获得每个输出单元j = 1至m的最终输出-
$$ f(y_ {in})\:= \:\ begin {cases} 1&if \:y_ {inj} \:> \:\ theta \\ 0&if \:-\ theta \:\ leqslant \ :y_ {inj} \:\ leqslant \:\ theta \\-1&if \:y_ {inj} \:
步骤7-如下调整x = 1到n和j = 1到m的权重和偏差-
情况1-如果y j ≠t j ,
$$ w_ {ij}(新)\:= \:w_ {ij}(旧)\:+ \:\ alpha \:t_ {j} x_ {i} $$
$$ b_ {j}(新)\:= \:b_ {j}(旧)\:+ \:\ alpha t_ {j} $$
情况2-如果y j = t j ,
$$ w_ {ij}(新)\:= \:w_ {ij}(旧)$$
$$ b_ {j}(新)\:= \:b_ {j}(旧)$$
“ y”是实际输出, “ t”是期望/目标输出。
步骤8-测试停止条件,这将在重量没有变化的情况下发生。
自适应线性神经元(Adaline)
Adaline代表自适应线性神经元,是一个具有单个线性单元的网络。它由Widrow和Hoff于1960年开发。有关Adaline的一些要点如下-
-
它使用双极激活函数。
-
它使用增量规则进行训练,以最小化实际输出与期望/目标输出之间的均方误差(MSE)。
-
权重和偏差是可调的。
建筑
Adaline的基本结构类似于具有额外反馈回路的感知器,借助该回路,可以将实际输出与所需/目标输出进行比较。在根据训练算法进行比较之后,权重和偏差将被更新。

训练算法
步骤1-初始化以下内容以开始训练-
- 重物
- 偏压
- 学习率$ \ alpha $
为了便于计算和简化,权重和偏差必须设置为0,学习率必须设置为1。
步骤2-如果停止条件不成立,则继续执行步骤3-8。
步骤3-对每个双极训练对s:t继续步骤4-6。
步骤4-如下激活每个输入单元-
$$ x_ {i} \:= \:s_ {i} \ 🙁 i \:= \:1 \:to \:n)$$
步骤5-获得具有以下关系的净输入-
$$ y_ {in} \:= \:b \:+ \:\ displaystyle \ sum \ limits_ {i} ^ n x_ {i} \:w_ {i} $$
在这里, “ b”是偏差, “ n”是输入神经元的总数。
步骤6-应用以下激活函数以获得最终输出-
$$ f(y_ {in})\:= \:\ begin {cases} 1&if \:y_ {in} \:\ geqslant \:0 \\-1&if \:y_ {in} \:
步骤7-如下调整权重和偏差-
情况1-如果y≠t ,
$$ w_ {i}(新)\:= \:w_ {i}(旧)\:+ \:\ alpha(t \:-\:y_ {in})x_ {i} $$
$$ b(新)\:= \:b(旧)\:+ \:\ alpha(t \:-\:y_ {in})$$
情况2-如果y = t ,
$$ w_ {i}(新)\:= \:w_ {i}(旧)$$
$$ b(新)\:= \:b(旧)$$
“ y”是实际输出, “ t”是期望/目标输出。
$(t \:-\; y_ {in})$是计算出的误差。
步骤8-测试停止条件,当体重没有变化或训练过程中最大的体重变化小于指定的公差时,将发生这种情况。
多适应线性神经元(Madaline)
Madaline代表多重自适应线性神经元,是一个由许多平行的Adaline组成的网络。它将具有单个输出单元。关于Madaline的一些重要点如下-
-
就像多层感知器一样,Adaline将充当输入和Madaline层之间的隐藏单元。
-
正如我们在Adaline架构中所见,输入层和Adaline层之间的权重和偏差是可调的。
-
Adaline和Madaline层具有固定的权重和1的偏差。
-
可以借助Delta规则进行培训。
建筑
Madaline的体系结构由输入层的“ n”个神经元,Adaline层的“ m”个神经元和Madaline层的1个神经元组成。 Adaline层可以视为隐藏层,因为它位于输入层和输出层之间,即Madaline层。
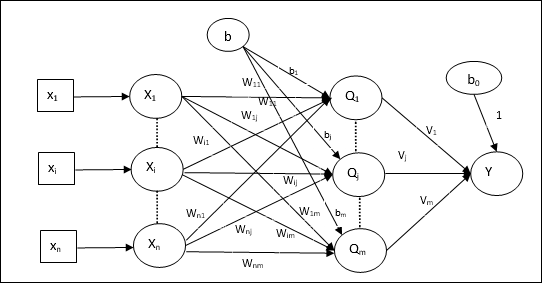
训练算法
至此,我们知道仅输入和Adaline层之间的权重和偏差将被调整,而Adaline和Madaline层之间的权重和偏差是固定的。
步骤1-初始化以下内容以开始训练-
- 重物
- 偏压
- 学习率$ \ alpha $
为了便于计算和简化,权重和偏差必须设置为0,学习率必须设置为1。
步骤2-如果停止条件不成立,则继续执行步骤3-8。
步骤3-对每个双极训练对s:t继续步骤4-6。
步骤4-如下激活每个输入单元-
$$ x_ {i} \:= \:s_ {i} \ 🙁 i \:= \:1 \:to \:n)$$
步骤5-获取每个隐藏层的净输入,即具有以下关系的Adaline层-
$$ Q_ {inj} \:= \:b_ {j} \:+ \:\ displaystyle \ sum \ limits_ {i} ^ n x_ {i} \:w_ {ij} \:\:\:j \: = \:1 \:至\:m $$
在这里, “ b”是偏差, “ n”是输入神经元的总数。
步骤6-应用以下激活函数以获得Adaline和Madaline层的最终输出-
$$ f(x)\:= \:\ begin {cases} 1&if \:x \:\ geqslant \:0 \\-1&if \:x \:
在隐藏(Adaline)单元输出
$$ Q_ {j} \:= \:f(Q_ {inj})$$
网络的最终输出
$$ y \:= \:f(y_ {in})$$
即$ \:\:y_ {inj} \:= \:b_ {0} \:+ \:\ sum_ {j = 1} ^ m \:Q_ {j} \:v_ {j} $
步骤7-计算误差并如下调整权重-
情况1-如果y≠t且t = 1 ,
$$ w_ {ij}(新)\:= \:w_ {ij}(旧)\:+ \:\ alpha(1 \:-:: Q_ {inj})x_ {i} $$
$$ b_ {j}(新)\:= \:b_ {j}(旧)\:+ \:\ alpha(1 \:-:: Q_ {inj})$$
在这种情况下,权重将在净输入接近于0的Q j上更新,因为t = 1 。
情况2-如果y≠t且t = -1 ,
$$ w_ {ik}(新)\:= \:w_ {ik}(旧)\:+ \:\ alpha(-1 \:-:: Q_ {ink})x_ {i} $$
$$ b_ {k}(新)\:= \:b_ {k}(旧)\:+ \:\ alpha(-1 \:-:: Q_ {ink})$$
在这种情况下,权重将在净输入为正的Q k上更新,因为t = -1 。
“ y”是实际输出, “ t”是期望/目标输出。
情况3-如果y = t,则
重量不会改变。
步骤8-测试停止条件,当体重没有变化或训练过程中最大的体重变化小于指定的公差时,将发生这种情况。
反向传播神经网络
反向传播神经(BPN)是一种多层神经网络,由输入层,至少一个隐藏层和输出层组成。顾名思义,反向传播将在此网络中进行。通过比较目标输出和实际输出在输出层计算出的误差将被传播回输入层。
建筑
如图所示,BPN的体系结构具有三个相互连接的层,这些层具有权重。隐藏层和输出层在其上也具有偏差,其权重始终为1。从图中可以清楚地看出,BPN的工作分为两个阶段。一相将信号从输入层发送到输出层,另一相将误差从输出层传播到输入层。
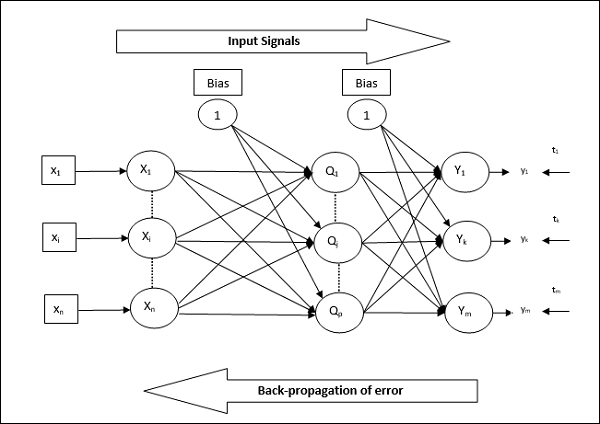
训练算法
为了进行训练,BPN将使用二进制S型激活函数。 BPN的培训将分为以下三个阶段。
-
阶段1-前馈阶段
-
阶段2-错误的反向传播
-
阶段3-权重更新
所有这些步骤将在算法中总结如下
步骤1-初始化以下内容以开始训练-
- 重物
- 学习率$ \ alpha $
为了便于计算和简化,请取一些小的随机值。
步骤2-当停止条件不成立时,继续执行步骤3-11。
步骤3-对于每个训练对,继续步骤4-10。
阶段1
步骤4-每个输入单元接收输入信号x i ,并将其发送给所有i = 1至n的隐藏单元
步骤5-使用以下关系式计算隐藏单元的净输入-
$$ Q_ {inj} \:= \:b_ {0j} \:+ \:\ sum_ {i = 1} ^ n x_ {i} v_ {ij} \:\:\:\:j \:= \ :1 \:至\:p $$
其中b 0j是隐藏单元的偏差, v ij是来自输入层的i单元的隐藏层的j单元的权重。
现在通过应用以下激活函数计算净输出
$$ Q_ {j} \:= \:f(Q_ {inj})$$
将隐藏层单位的这些输出信号发送到输出层单位。
步骤6-使用以下关系式计算输出层单元的净输入-
$$ y_ {ink} \:= \:b_ {0k} \:+ \:\ sum_ {j = 1} ^ p \:Q_ {j} \:w_ {jk} \:\:k \:= \ :1 \:至\:m $$
这里b 0Kis输出单元上的偏压,瓦特JK是从隐藏层j的单元来的输出层中的k单元上的重量。
通过应用以下激活函数计算净输出
$$ y_ {k} \:= \:f(y_ {ink})$$
阶段2
步骤7-根据每个输出单元接收的目标模式,如下计算纠错项:
$$ \ delta_ {k} \:= \ 🙁 t_ {k} \:-\:y_ {k})f ^ {‘}(y_ {ink})$$
在此基础上,如下更新权重和偏差:
$$ \ Delta v_ {jk} \:= \:\ alpha \ delta_ {k} \:Q_ {ij} $$
$$ \ Delta b_ {0k} \:= \:\ alpha \ delta_ {k} $$
然后,将$ \ delta_ {k} $发送回隐藏层。
步骤8-现在每个隐藏单位将是其从输出单位输入的增量的总和。
$$ \ delta_ {inj} \:= \:\ displaystyle \ sum \ limits_ {k = 1} ^ m \ delta_ {k} \:w_ {jk} $$
误差项可以计算如下-
$$ \ delta_ {j} \:= \:\ delta_ {inj} f ^ {‘}(Q_ {inj})$$
在此基础上,如下更新权重和偏差:
$$ \ Delta w_ {ij} \:= \:\ alpha \ delta_ {j} x_ {i} $$
$$ \ Delta b_ {0j} \:= \:\ alpha \ delta_ {j} $$
第三阶段
步骤9-每个输出单元(y k k = 1至m)如下更新权重和偏差-
$$ v_ {jk}(新)\:= \:v_ {jk}(旧)\:+ \:\ Delta v_ {jk} $$
$$ b_ {0k}(新)\:= \:b_ {0k}(旧)\:+ \:\ Delta b_ {0k} $$
步骤10-每个输出单元(z j j = 1至p)如下更新权重和偏差-
$$ w_ {ij}(新)\:= \:w_ {ij}(旧)\:+ \:\ Delta w_ {ij} $$
$$ b_ {0j}(新)\:= \:b_ {0j}(旧)\:+ \:\ Delta b_ {0j} $$
步骤11-检查停止条件,可能是达到的时期数或目标输出与实际输出匹配。
广义增量学习法则
增量规则仅适用于输出层。另一方面,广义增量规则(也称为反向传播规则)是一种创建所需隐藏层值的方法。
数学公式
对于激活函数$ y_ {k} \:= \:f(y_ {ink})$,隐藏层和输出层的净输入都可以由下式给出:
$$ y_ {ink} \:= \:\ displaystyle \ sum \ limits_i \:z_ {i} w_ {jk} $$
和$ \:\:y_ {inj} \:= \:\ sum_i x_ {i} v_ {ij} $
现在必须最小化的错误是
$$ E \:= \:\ frac {1} {2} \ displaystyle \ sum \ limits_ {k} \:[t_ {k} \:-\:y_ {k}] ^ 2 $$
通过使用链式规则,我们可以
$$ \ frac {\ partial E} {\ partial w_ {jk}} \:= \:\ frac {\ partial} {\ partial w_ {jk}}(\ frac {1} {2} \ displaystyle \ sum \ limit_ {k} \:[t_ {k} \:-\:y_ {k}] ^ 2)$$
$$ = \:\ frac {\ partial} {\ partial w_ {jk}} \ lgroup \ frac {1} {2} [t_ {k} \:-\:t(y_ {ink})] ^ 2 \ rgroup $$
$$ = \:-[t_ {k} \:-\:y_ {k}] \ frac {\ partial} {\ partial w_ {jk}} f(y_ {ink})$$
$$ = \:-[t_ {k} \:-\:y_ {k}] f(y_ {ink})\ frac {\ partial} {\ partial w_ {jk}}(y_ {ink})$$
$$ = \:-[t_ {k} \:-\:y_ {k}] f ^ {‘}(y_ {ink})z_ {j} $$
现在让我们说$ \ delta_ {k} \:= \:-[t_ {k} \:-\:y_ {k}] f ^ {‘}(y_ {ink})$
到隐藏单元z j的连接权重可以通过-
$$ \ frac {\ partial E} {\ partial v_ {ij}} \:= \:-\ displaystyle \ sum \ limits_ {k} \ delta_ {k} \ frac {\ partial} {\ partial v_ {ij} } \ 🙁 y_ {ink})$$
输入$ y_ {ink} $的值,我们将得到以下内容
$$ \ delta_ {j} \:= \:-\ displaystyle \ sum \ limits_ {k} \ delta_ {k} w_ {jk} f ^ {‘}(z_ {inj})$$
权重更新可以如下进行-
对于输出单元-
$$ \ Delta w_ {jk} \:= \:-\ alpha \ frac {\ partial E} {\ partial w_ {jk}} $$
$$ = \:\ alpha \:\ delta_ {k} \:z_ {j} $$
对于隐藏的单元-
$$ \ Delta v_ {ij} \:= \:-\ alpha \ frac {\ partial E} {\ partial v_ {ij}} $$
$$ = \:\ alpha \:\ delta_ {j} \:x_ {i} $$