📌 相关文章
- 监督学习与无监督学习之间的区别(1)
- 监督学习与无监督学习之间的区别(1)
- 监督学习(1)
- 监督学习和无监督学习
- 监督学习和无监督学习(1)
- 无监督学习
- 无监督学习(1)
- 监督学习
- 有监督和无监督学习(1)
- 有监督和无监督学习
- R 编程中的有监督和无监督学习(1)
- R 编程中的有监督和无监督学习
- 监督机器学习
- 机器学习-无监督(1)
- 无监督机器学习(1)
- 机器学习-监督(1)
- 机器学习-无监督
- 无监督机器学习
- 机器学习-监督
- 毫升 |半监督学习
- 毫升 |半监督学习(1)
- ML |学习类型–监督学习
- ML |学习类型–监督学习(1)
- 带Python的AI –监督学习:回归
- 带Python的AI –监督学习:回归(1)
- 回归和分类 |监督机器学习
- 回归和分类 |监督机器学习(1)
- 带有Python的AI-无监督学习:聚类(1)
- 带有Python的AI-无监督学习:聚类
📜 监督学习与无监督学习之间的区别
📅 最后修改于: 2020-09-27 01:03:35 🧑 作者: Mango
监督学习与无监督学习之间的区别
监督学习和无监督学习是机器学习的两种技术。但是这两种技术都用于不同的场景和不同的数据集。下面给出两种学习方法的解释以及它们的差异表。

有监督的机器学习:
监督学习是一种机器学习方法,其中使用标记的数据来训练模型。在监督学习中,模型需要找到映射函数以将输入变量(X)与输出变量(Y)映射。
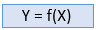
监督学习需要监督以训练模型,这类似于学生在老师在场的情况下学习事物。监督学习可用于两种类型的问题:分类和回归。
了解更多监督机器学习
示例:假设我们有不同类型水果的图像。我们的监督学习模型的任务是识别水果并相应地对其进行分类。因此,要在监督学习中识别图像,我们将提供输入数据和输出数据,这意味着我们将根据每种水果的形状,大小,颜色和口味来训练模型。训练完成后,我们将通过提供新的结果集来测试模型。该模型将识别水果并使用合适的算法预测输出。
无监督机器学习:
无监督学习是另一种机器学习方法,其中从未标记的输入数据推断出模式。无监督学习的目的是从输入数据中找到结构和模式。无监督学习不需要任何监督。相反,它自己从数据中查找模式。
了解更多无监督机器学习
无监督学习可用于两种类型的问题:聚类和关联。
示例:为了理解无监督学习,我们将使用上面给出的示例。因此,与监督学习不同,这里我们将不对模型提供任何监督。我们将仅向模型提供输入数据集,并允许模型从数据中找到模式。借助合适的算法,模型将进行自我训练,并根据水果之间最相似的特征将其分为不同的组。
监督学习和无监督学习之间的主要区别如下:
| Supervised Learning | Unsupervised Learning |
|---|---|
| 监督学习算法使用标记数据进行训练 | 无监督学习算法使用无标记数据进行训练 |
| 监督学习模型采用直接反馈的方式来检测预测结果是否正确 | 无监督学习模型不接受任何反馈 |
| 监督学习模型预测输出 | 无监督学习模型发现数据中隐藏的模式 |
| 在监督学习中,输入数据与输出数据一起提供给模型 | 在无监督学习中,只向模型提供输入数据 |
| 监督学习的目的是训练模型,使其能够在给定新数据时预测输出 | 无监督学习的目标是从未知数据集中发现隐藏的模式和有用的见解 |
| 监督学习需要监督来训练模型 | 无监督学习不需要任何监督来训练模型 |
| 监督学习可以分为分类问题和回归问题 | 无监督学习可以分为聚类和关联问题 |
| 监督学习可以用于那些我们知道输入和相应输出的情况 | 无监督学习可以用于只有输入数据而没有相应输出数据的情况 |
| 监督学习模型可以产生准确的结果 | 与有监督学习相比,无监督学习模型的结果可能不那么准确 |
| 监督学习并不像真正的人工智能那样,我们首先训练每个数据的模型,然后只有它才能预测正确的输出 | 无监督学习更接近真正的人工智能,因为它的学习类似于一个孩子通过他的经验学习日常事务 |
| 它包括线性回归、逻辑回归、支持向量机、多类分类、决策树、贝叶斯逻辑等多种算法 | 包括聚类、KNN、Apriori算法等多种算法 |
注意:有监督和无监督学习都是机器学习方法,对这些学习的选择取决于与数据集的结构和数量以及问题用例有关的因素。