- 无监督机器学习
- 监督机器学习
- 无监督机器学习(1)
- 机器学习-无监督
- 机器学习-监督(1)
- 监督学习(1)
- 监督学习
- 无监督学习(1)
- 监督学习和无监督学习
- 无监督学习
- 监督学习和无监督学习(1)
- 有监督和无监督学习(1)
- 有监督和无监督学习
- 监督学习与无监督学习之间的区别
- 监督学习与无监督学习之间的区别(1)
- 监督学习与无监督学习之间的区别
- 监督学习与无监督学习之间的区别(1)
- R 编程中的有监督和无监督学习
- R 编程中的有监督和无监督学习(1)
- 回归和分类 |监督机器学习(1)
- 回归和分类 |监督机器学习
- 无监督机器学习——网络安全的未来(1)
- 无监督机器学习——网络安全的未来
- C++中的机器学习(1)
- C++中的机器学习
- 机器学习中的 P 值
- 机器学习中的 P 值(1)
- 机器学习 (1)
- 毫升 |半监督学习(1)
📅 最后修改于: 2020-12-13 15:56:24 🧑 作者: Mango
监督学习是培训机器中涉及的重要学习模型之一。本章将详细讨论。
监督学习算法
有几种可用于监督学习的算法。一些广泛使用的监督学习算法如下所示-
- k最近邻居
- 决策树
- 朴素贝叶斯
- 逻辑回归
- 支持向量机
随着本章的深入,让我们详细讨论每种算法。
k最近邻居
k最近邻居,简称为kNN,是一种统计技术,可用于解决分类和回归问题。让我们讨论使用kNN对未知对象进行分类的情况。考虑对象的分布,如下图所示-
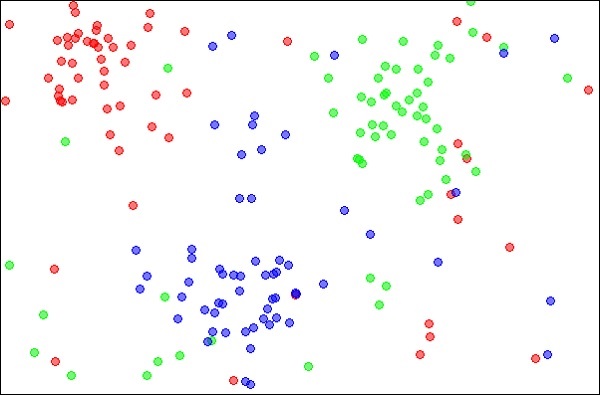
资源:
https://zh.wikipedia.org/wiki/K-nearest_neighbors_algorithm
该图显示了三种类型的对象,分别用红色,蓝色和绿色标记。在上述数据集上运行kNN分类器时,每种类型的对象的边界都将被标记,如下所示-
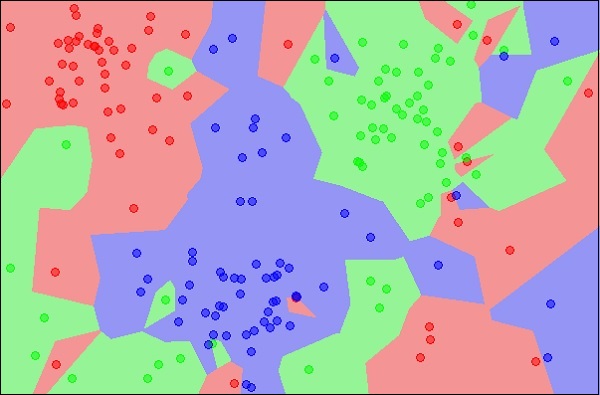
资源:
https://zh.wikipedia.org/wiki/K-nearest_neighbors_algorithm
现在,考虑要分类为红色,绿色或蓝色的新未知对象。如下图所示。
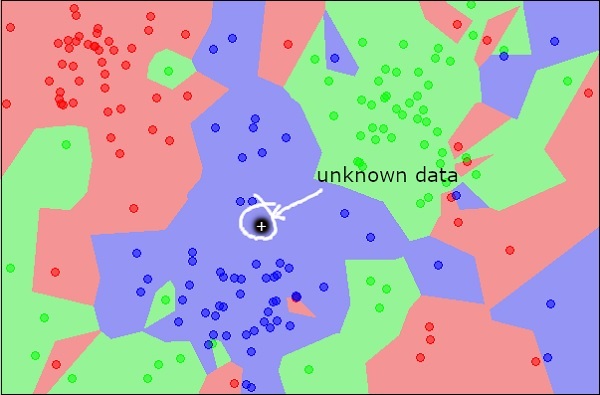
从视觉上看,未知数据点属于一类蓝色对象。从数学上讲,这可以通过测量此未知点与数据集中其他每个点的距离来得出结论。当您这样做时,您将知道它的大多数邻居都是蓝色的。到红色和绿色物体的平均距离肯定会比到蓝色物体的平均距离大。因此,该未知物体可以被分类为属于蓝色类别。
kNN算法也可以用于回归问题。在大多数ML库中,都可以立即使用kNN算法。
决策树
下面显示了流程图格式的简单决策树-
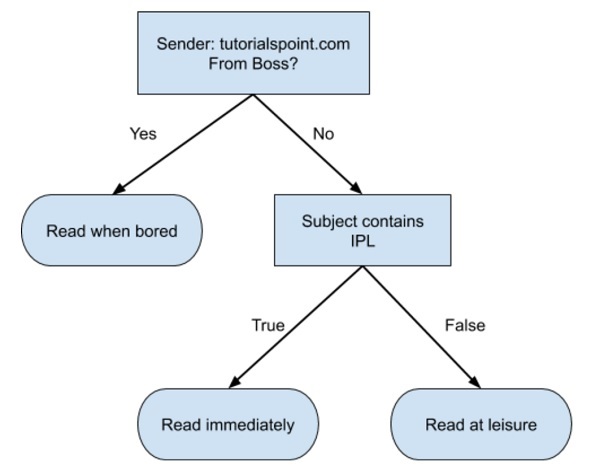
您将根据此流程图编写代码以对输入数据进行分类。流程图是不言而喻的,琐碎的。在这种情况下,您尝试对传入的电子邮件进行分类,以决定何时阅读。
实际上,决策树可能很大而且很复杂。有几种可用于创建和遍历这些树的算法。作为机器学习爱好者,您需要了解和掌握创建和遍历决策树的这些技术。
朴素贝叶斯
朴素贝叶斯用于创建分类器。假设您要从水果篮中分类(分类)不同种类的水果。您可以使用诸如水果的颜色,大小和形状之类的功能,例如,任何红色,圆形,直径约10厘米的水果都可以视为Apple。因此,要训练模型,您将使用这些功能并测试给定功能与所需约束匹配的可能性。然后将不同特征的概率合并,得出给定水果是苹果的概率。朴素贝叶斯通常需要少量的训练数据进行分类。
逻辑回归
看下图。它显示了数据点在XY平面中的分布。
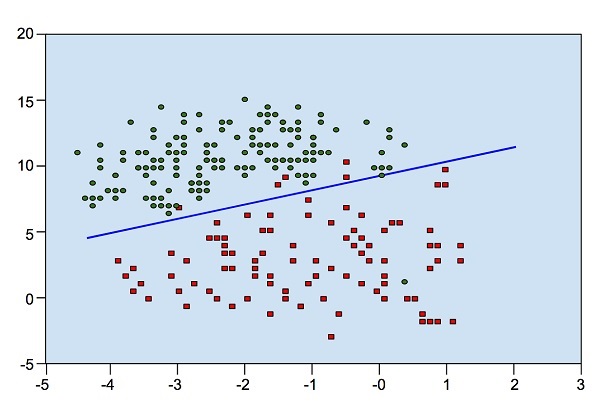
从图中,我们可以直观地检查红点与绿点的分离。您可以绘制边界线以分离出这些点。现在,要分类一个新的数据点,您只需确定该点位于线的哪一边。
支持向量机
查看以下数据分布。这里,这三类数据无法线性分离。边界曲线是非线性的。在这种情况下,找到曲线的方程变得很复杂。

资料来源: http : //uc-r.github.io/svm
支持向量机(SVM)在确定这种情况下的分离边界时非常方便。