什么是机器学习中的回归和分类?
数据科学家使用许多不同类型的机器学习算法来发现大数据中的模式,从而得出可操作的见解。在较高的层次上,这些不同的算法可以根据它们“学习”数据以进行预测的方式分为两类:监督学习和无监督学习。
监督机器学习:大多数实际机器学习使用监督学习。监督学习是您拥有输入变量 (x) 和输出变量 (Y) 并使用算法来学习从输入到输出Y = f(X)的映射函数。目标是很好地近似映射函数,以便当您有新的输入数据 (x) 时,您可以预测该数据的输出变量 (Y)。
监督机器学习算法的技术包括线性和逻辑回归、多类分类、决策树和支持向量机。监督学习要求用于训练算法的数据已经标有正确答案。例如,分类算法将在对图像数据集进行训练后学习识别动物,这些图像数据集正确标记了动物的物种和一些识别特征。
监督学习问题可以进一步分为回归和分类问题。这两个问题的目标都是构建一个简洁的模型,该模型可以从属性变量中预测依赖属性的值。这两个任务之间的区别在于,依赖属性对于回归是数字的,而对于分类是分类的。
回归
回归问题是当输出变量是实数或连续值时,例如“薪水”或“权重”。可以使用许多不同的模型,最简单的是线性回归。它尝试将数据与通过这些点的最佳超平面进行拟合。
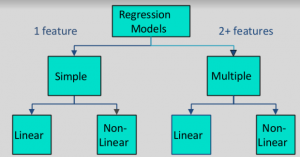
回归模型的类型:
举些例子:
以下哪个是回归任务?
- 预测一个人的年龄
- 预测一个人的国籍
- 预测明天公司股价会不会上涨
- 预测文件是否与目击不明飞行物有关?
解决方案:预测一个人的年龄(因为它是一个真实值,预测国籍是分类的,股价是否会上涨是离散的-是/否答案,预测一个文件是否与UFO有关又是离散的-是/否答案)。
让我们举一个线性回归的例子。我们有一个房屋数据集,我们想预测房屋的价格。以下是它的Python代码。
Python3
# Python code to illustrate
# regression using data set
import matplotlib
matplotlib.use('GTKAgg')
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model
import pandas as pd
# Load CSV and columns
df = pd.read_csv("Housing.csv")
Y = df['price']
X = df['lotsize']
X=X.values.reshape(len(X),1)
Y=Y.values.reshape(len(Y),1)
# Split the data into training/testing sets
X_train = X[:-250]
X_test = X[-250:]
# Split the targets into training/testing sets
Y_train = Y[:-250]
Y_test = Y[-250:]
# Plot outputs
plt.scatter(X_test, Y_test, color='black')
plt.title('Test Data')
plt.xlabel('Size')
plt.ylabel('Price')
plt.xticks(())
plt.yticks(())
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(X_train, Y_train)
# Plot outputs
plt.plot(X_test, regr.predict(X_test), color='red',linewidth=3)
plt.show()Python3
# Python code to illustrate
# classification using data set
#Importing the required library
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
#Importing the dataset
dataset = pd.read_csv(
'https://archive.ics.uci.edu/ml/machine-learning-'+
'databases/iris/iris.data',sep= ',', header= None)
data = dataset.iloc[:, :]
#checking for null values
print("Sum of NULL values in each column. ")
print(data.isnull().sum())
#separating the predicting column from the whole dataset
X = data.iloc[:, :-1].values
y = dataset.iloc[:, 4].values
#Encoding the predicting variable
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
#Splitting the data into test and train dataset
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.3, random_state = 0)
#Using the random forest classifier for the prediction
classifier=RandomForestClassifier()
classifier=classifier.fit(X_train,y_train)
predicted=classifier.predict(X_test)
#printing the results
print ('Confusion Matrix :')
print(confusion_matrix(y_test, predicted))
print ('Accuracy Score :',accuracy_score(y_test, predicted))
print ('Report : ')
print (classification_report(y_test, predicted))上述代码的输出将是:
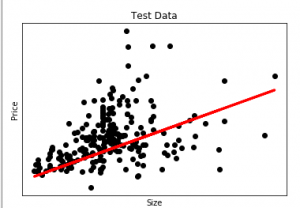
在此图中,我们绘制了测试数据。红线表示预测价格的最佳拟合线。要使用线性回归模型进行单独预测:
print( str(round(regr.predict(5000))) )分类
分类问题是当输出变量是一个类别时,例如“红色”或“蓝色”或“疾病”和“无疾病”。分类模型试图从观察值中得出一些结论。给定一个或多个输入,分类模型将尝试预测一个或多个结果的值。
例如,在过滤“垃圾邮件”或“非垃圾邮件”电子邮件时,查看交易数据时,“欺诈”或“授权”。简而言之,分类要么预测分类类标签,要么基于训练集和分类属性中的值(类标签)对数据进行分类(构建模型),并将其用于对新数据进行分类。有许多分类模型。分类模型包括逻辑回归、决策树、随机森林、梯度提升树、多层感知器、one-vs-rest 和朴素贝叶斯。
例如 :
以下哪个是分类问题?
- 通过他/她的笔迹风格预测一个人的性别
- 根据面积预测房价
- 预测明年季风是否正常
- 预测一张音乐专辑下个月的销量
解决方案:预测一个人的性别,预测明年季风是否正常。另外两个是回归。
正如我们用一些例子讨论了分类。现在有一个分类示例,其中我们使用Python的RandomForestClassifier对 iris 数据集执行分类。您可以从这里下载数据集
数据集描述
Title: Iris Plants Database
Attribute Information:
1. sepal length in cm
2. sepal width in cm
3. petal length in cm
4. petal width in cm
5. class:
-- Iris Setosa
-- Iris Versicolour
-- Iris Virginica
Missing Attribute Values: None
Class Distribution: 33.3% for each of 3 classes蟒蛇3
# Python code to illustrate
# classification using data set
#Importing the required library
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
#Importing the dataset
dataset = pd.read_csv(
'https://archive.ics.uci.edu/ml/machine-learning-'+
'databases/iris/iris.data',sep= ',', header= None)
data = dataset.iloc[:, :]
#checking for null values
print("Sum of NULL values in each column. ")
print(data.isnull().sum())
#separating the predicting column from the whole dataset
X = data.iloc[:, :-1].values
y = dataset.iloc[:, 4].values
#Encoding the predicting variable
labelencoder_y = LabelEncoder()
y = labelencoder_y.fit_transform(y)
#Splitting the data into test and train dataset
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.3, random_state = 0)
#Using the random forest classifier for the prediction
classifier=RandomForestClassifier()
classifier=classifier.fit(X_train,y_train)
predicted=classifier.predict(X_test)
#printing the results
print ('Confusion Matrix :')
print(confusion_matrix(y_test, predicted))
print ('Accuracy Score :',accuracy_score(y_test, predicted))
print ('Report : ')
print (classification_report(y_test, predicted))
输出:
Sum of NULL values in each column.
0 0
1 0
2 0
3 0
4 0
Confusion Matrix :
[[16 0 0]
[ 0 17 1]
[ 0 0 11]]
Accuracy Score : 97.7
Report :
precision recall f1-score support
0 1.00 1.00 1.00 16
1 1.00 0.94 0.97 18
2 0.92 1.00 0.96 11
avg/total 0.98 0.98 0.98 45参考:
- https://machinelearningmastery.com/logistic-regression-for-machine-learning/
- https://machinelearningmastery.com/linear-regression-for-machine-learning/