在 SVM 中分离超平面
支持向量机是有监督的机器学习算法,用于模型的分类和回归。其背后的想法很简单,只需找到一个平面或边界来分隔两个类之间的数据。
支持向量:
支持向量是靠近决策边界的数据点,它们是最难分类的数据点,它们是SVM成为最优决策面的关键。最佳超平面来自容量最低的函数类,即独立特征/参数的最少数量。
分离超平面:
下面是散点图的示例:

在上面的散点图中,我们能否找到一条可以将两个类别分开的线。这样的线称为分离超平面。那么,为什么它被称为超平面,因为在二维中,它是一条线,但对于一维,它可以是一个点,对于 3 维,它是一个平面,对于 3 维或更多维,它是一个超平面
现在,我们了解了超平面,我们还需要找到最优化的超平面。这个超平面应该离支持向量最远的想法。这个距离 b/w 分离超平面和支持向量,称为边距。因此,最好的超平面将是其边距最大的。
通常,margin 可以取为 2* p,其中 p 是分离超平面和最近支持向量的 b/w 距离。下面是计算线性可分超平面的方法。
分离超平面可以由两个项定义:称为 b 的截距项和称为w的决策超平面法向量。这些通常被称为机器学习中的权重向量。这里b用于选择超平面,即垂直于法向量。现在由于超平面中的所有平面 x 应满足以下等式:

现在,考虑训练 D 使得 \mathbb{D} = \left \{ \left ( \vec{x_i}, y_i \right ) \right \} 其中 \vec{x_i} \, y_i 代表 n 维数据分别为点和类标签。这里的类标签的值只能是 -1 或 +1(对于 2 类问题)。那么线性分类器是:

然而,功能余量根据上面的定义是无约束的,所以我们需要公式化距离 b/wa 数据点x和决策边界。最短距离 b/w 它们当然是垂直距离,即平行于法向量 \vec{w}。该法向量方向上的酉向量由 \\frac{\vec{w}}{\left \| 给出\vec{w} \right \|}。现在,


在线性分类器方程中用 x 替换 x' 给出:
现在,求解 r 给出以下等式:
其中,r 是边距。现在,由于

或者,每个数据点的上述等式:

这里,几何边距为:

我们需要最大化几何边距,使得:
最大化 与最小化 \frac{1}{\rho} = \frac{||w||}{2} 相同,也就是说,我们需要找到 w 和 b 使得:
与最小化 \frac{1}{\rho} = \frac{||w||}{2} 相同,也就是说,我们需要找到 w 和 b 使得:
在这里,我们正在优化具有线性约束的二次方程。现在,这使我们找到解决对偶问题的方法。
对偶问题:
在优化中,对偶原则指出优化问题可以从不同的角度看待:原始问题和对偶问题对偶问题的解决方案提供了原始(最小化)问题的解决方案的下界。
一个优化问题通常可以写成:

其中,f 是目标函数g,h 是约束函数。上述问题可以通过诸如拉格朗日乘法器之类的技术来解决。
拉格朗日乘数
拉格朗日乘数是一种为具有等式约束的函数寻找局部最小值和最大值的方法。拉格朗日乘子可以描述为
在拉格朗日方程中:
假设,我们定义函数使得

上述函数称为拉格朗日函数,现在,我们需要找到 L(x,y, \lambda) 为 0,即函数 f 和 g 的梯度平行的点。
例子
考虑三个点,其中点 (1,2) 和 (2,0) 属于一类,而 (3,2) 属于另一类,几何上,我们可以观察到最大边界线将平行于连接点的线两个班级。 (1,1) 和 (2,3) 给定一个权重向量为 (1,2)。最优决策面(分离超平面)将在(1.5,2)处相交。现在,我们可以使用这个结论来计算偏差:
.现在,决策面方程变为:

现在,由于 sign(y_i(w^{T}x_i +b)) \geq 1 ,为了最小化 |\vec{w}|,我们需要检查等式约束或支持向量。让我们对一些 a 取 w=(a,2a) 使得:

求解上述方程给出:

这意味着保证金变为:

执行
在这个实现中,我们将使用 sklearn 库验证上面的例子,并尝试对上面的例子进行建模:
Python3
# Import Necessary libraries/functions
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
# define the dataset
X = np.array([[1,1],
[2,0],
[2,3]])
Y = np.array([0,0,1])
# define support vector classifier with linear kernel
clf = SVC(gamma='auto', kernel ='linear')
# fit the above data in SVC
clf.fit(X,Y)
# plot the decision boundary ,data points,suppport vector etcv
w = clf.coef_[0]
a = -w[0] / w[1]
xx = np.linspace(0,12)
yy = a * xx - clf.intercept_[0] / w[1]
y_neg = a * xx - clf.intercept_[0] / w[1] + 1
y_pos = a * xx - clf.intercept_[0] / w[1] - 1
plt.figure(1,figsize= (15, 10))
plt.plot(xx, yy, 'k',
label=f"Decision Boundary (y ={w[0]}x1 + {w[1]}x2 {clf.intercept_[0] })")
plt.plot(xx, y_neg, 'b-.',
label=f"Neg Decision Boundary (-1 ={w[0]}x1 + {w[1]}x2 {clf.intercept_[0] })")
plt.plot(xx, y_pos, 'r-.',
label=f"Pos Decision Boundary (1 ={w[0]}x1 + {w[1]}x2 {clf.intercept_[0] })")
for i in range(3):
if (Y[i]==0):
plt.scatter(X[i][0], X[i][1],color='red', marker='o', label='negative')
else:
plt.scatter(X[i][0], X[i][1],color='green', marker='x', label='positive')
plt.legend()
plt.show()
# calculate margin
print(f'Margin : {2.0 /np.sqrt(np.sum(clf.coef_ ** 2)) }')Margin : 2.236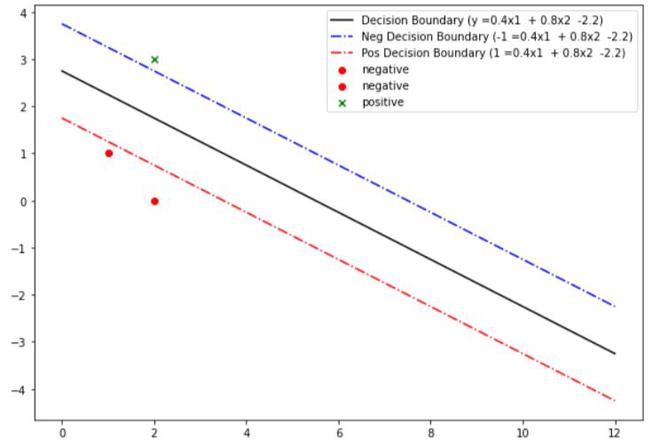
最终的 SVM 决策边界
参考:
- 斯坦福自然语言处理