在 R 中使用 Dplyr 包删除多列
在本文中,我们将讨论如何使用 R 编程语言中的 dplyr 包删除多个列。
使用中的数据集:
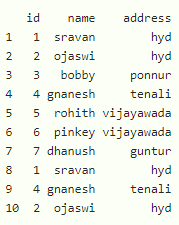
使用列名删除多列
我们可以通过列名使用 select() 方法删除列
语法:
select(dataframe,-c(column_name1,column_name2,.,column_name n)
其中,dataframe 是输入数据帧,-c(column_names) 是要删除的列名称的集合。
示例: R 程序按列名删除多列
R
# load the library
library(dplyr)
# create dataframe with 3 columns id,
# name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove name and id column
print(select(data1,-c(id,name)))
# remove name and address column
print(select(data1,-c(address,name)))
# remove all column
print(select(data1,-c(address,name,id)))R
# load the library
library(dplyr)
# create dataframe with 3 columns
# id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove name and id columns by
# its position
print(select(data1,-c(1,2)))R
# load the library
library(dplyr)
# create dataframe with 3 columns
# id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove column that contains na
print(select(data1,-contains('na')))
# remove column that contains re
print(select(data1,-contains('re')))R
# load the library
library(dplyr)
# create dataframe with 3 columns
# id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove column that starts with na
print(select(data1,-starts_with('na')))
# remove column that starts with ad
print(select(data1,-starts_with('ad')))R
# load the library
library(dplyr)
# create dataframe with 3 columns
# id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove column that ends with d
print(select(data1,-ends_with('d')))
# remove column that starts with ss
print(select(data1,-ends_with('ss')))R
# load the library
library(dplyr)
# create dataframe with 3 columns
# id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# drop column that starts with n
print(data1[,!grepl("^n",names(data1))])
# remove column that starts with a
print(data1[,!grepl("^a",names(data1))])输出:

使用列索引删除多列
我们可以通过列索引/位置使用 select() 方法删除列。索引从 1 开始。
句法:
select(dataframe,-c(column_index1,column_index2,.,column_index n)
其中,dataframe 是输入数据帧,c(column_indexes) 是要删除的列的位置。
示例: R 程序按位置删除多列
电阻
# load the library
library(dplyr)
# create dataframe with 3 columns
# id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove name and id columns by
# its position
print(select(data1,-c(1,2)))
输出:

删除包含值或匹配模式的列
让我们看看如何删除包含字符/字符串的列。
方法一:使用 contains()
显示包含给定子字符串的列,然后 -contains ()删除包含给定子字符串的列。
句法:
select(dataframe,-contains(‘sub_string’))
这里,dataframe 是输入数据帧,sub_string 是列名中存在的将被删除的字符串。
方法二:使用matches()
显示包含给定子字符串的列,然后-matches()删除包含给定子字符串的列
句法:
select(dataframe,-matches(‘sub_string’))
这里,dataframe 是输入数据帧,sub_string 是列名中存在的将被删除的字符串。
示例:使用 contains() 方法删除列的 R 程序
电阻
# load the library
library(dplyr)
# create dataframe with 3 columns
# id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove column that contains na
print(select(data1,-contains('na')))
# remove column that contains re
print(select(data1,-contains('re')))
输出:

删除以特定字符开头或结尾的列
在这里我们还可以根据开始和结束字符选择列。
- starts_with()用于返回以给定字符开头的列, -starts_with()用于删除以给定字符开头的列。
句法:
select(dataframe,-starts_with(‘substring’))
Where, dataframe is the input dataframe and substring is the character/string that starts with it
- Ends_with()用于返回以给定字符结尾的列, -ends_with()用于删除以给定字符结尾的列。
句法:
select(dataframe,-ends_with(‘substring’))
Where, dataframe is the input dataframe and substring is the character/string that ends with it.
示例 1: R 程序删除以字符/substring 开头的列
电阻
# load the library
library(dplyr)
# create dataframe with 3 columns
# id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove column that starts with na
print(select(data1,-starts_with('na')))
# remove column that starts with ad
print(select(data1,-starts_with('ad')))
输出:

示例 2: R 程序删除以字符/substring 结尾的列
电阻
# load the library
library(dplyr)
# create dataframe with 3 columns
# id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove column that ends with d
print(select(data1,-ends_with('d')))
# remove column that starts with ss
print(select(data1,-ends_with('ss')))
输出:

使用正则表达式删除列名
在这里,我们将根据 grepl()函数给出的模式删除列。它将找到一个模式并根据给定的模式删除列
句法:
dataframe[,!grepl(“pattern”,names(dataframe))]
这里,数据帧是输入数据帧,模式是删除列的表达式。
删除列中起始字符开始的列的模式是
句法:
data[,!grepl(“^letter”,names(data))]
示例: R 程序删除以字母开头的列
电阻
# load the library
library(dplyr)
# create dataframe with 3 columns
# id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# drop column that starts with n
print(data1[,!grepl("^n",names(data1))])
# remove column that starts with a
print(data1[,!grepl("^a",names(data1))])
输出:
