使用 Dplyr 删除 R 中的重复行
在本文中,我们将使用 Dplyr 包删除 R 编程语言中的重复行。
方法一:distinct()
此函数用于删除数据框中的重复行并获取唯一数据
句法:
distinct(dataframe)
我们还可以根据数据框中的多列/变量删除重复的行
句法:
distinct(dataframe,column1,column2,.,column n)
使用中的数据集:

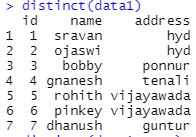
示例 1:从数据框中删除重复行的 R 程序
R
# load the package
library(dplyr)
# create dataframe with three columns
# named id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove duplicate rows
print(distinct(data1))R
# load the package
library(dplyr)
# create dataframe with three columns
# named id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove duplicate rows based on name
# column
print(distinct(data1,name))R
# load the package
library(dplyr)
# create dataframe with three columns
# named id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove duplicate rows based on
# name and address columns
print(distinct(data1,address,name))R
# load the package
library(dplyr)
# create dataframe with three columns
# named id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove duplicate rows using duplicated()
# function based on name column
print(data1[!duplicated(data1$name), ] )
print("=====================")
# remove duplicate rows using duplicated()
# function based on id column
print(data1[!duplicated(data1$id), ] )
print("=====================")
# remove duplicate rows using duplicated()
# function based on address column
print(data1[!duplicated(data1$address), ] )
print("=====================")R
# load the package
library(dplyr)
# create dataframe with three columns
# named id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# get unique data from the dataframe
print(unique(data1))R
# load the package
library(dplyr)
# create dataframe with three columns
# named id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# get unique data from the dataframe
# in id column
print(unique(data1$id))
# get unique data from the dataframe
# in name column
print(unique(data1$name))
# get unique data from the dataframe
# in address column
print(unique(data1$address))输出:
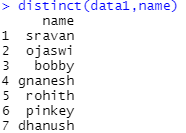
示例 2:基于单列删除重复行
电阻
# load the package
library(dplyr)
# create dataframe with three columns
# named id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove duplicate rows based on name
# column
print(distinct(data1,name))
输出:
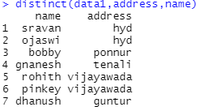
示例 3:删除基于多列的重复行
电阻
# load the package
library(dplyr)
# create dataframe with three columns
# named id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove duplicate rows based on
# name and address columns
print(distinct(data1,address,name))
输出:
方法二:使用duplicated()函数
duplicated()函数将返回重复的行,!duplicated()函数将返回唯一的行。
句法:
dataframe[!duplicated(dataframe$column_name), ]
这里,dataframe 是输入数据帧,column_name 是数据帧中的列,根据该列删除重复数据。
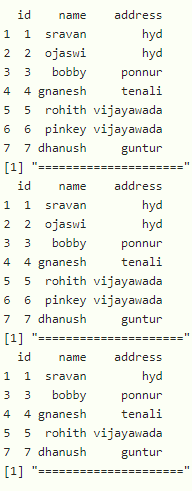
示例:基于特定列删除重复数据的 R 程序
电阻
# load the package
library(dplyr)
# create dataframe with three columns
# named id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# remove duplicate rows using duplicated()
# function based on name column
print(data1[!duplicated(data1$name), ] )
print("=====================")
# remove duplicate rows using duplicated()
# function based on id column
print(data1[!duplicated(data1$id), ] )
print("=====================")
# remove duplicate rows using duplicated()
# function based on address column
print(data1[!duplicated(data1$address), ] )
print("=====================")
输出:
方法 3:使用 unique()函数
unique()函数用于通过返回唯一数据来删除重复行
句法:
unique(dataframe)
要从列中获取唯一数据,请传递列的名称以及数据框的名称,
句法:
unique(dataframe$column_name)
其中,dataframe 是输入数据帧,column_name 是数据帧中的列。
示例 1:使用 unique()函数删除重复项的 R 程序
电阻
# load the package
library(dplyr)
# create dataframe with three columns
# named id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# get unique data from the dataframe
print(unique(data1))
输出:

示例 2:用于删除特定列中重复项的 R 程序
电阻
# load the package
library(dplyr)
# create dataframe with three columns
# named id,name and address
data1=data.frame(id=c(1,2,3,4,5,6,7,1,4,2),
name=c('sravan','ojaswi','bobby',
'gnanesh','rohith','pinkey',
'dhanush','sravan','gnanesh',
'ojaswi'),
address=c('hyd','hyd','ponnur','tenali',
'vijayawada','vijayawada','guntur',
'hyd','tenali','hyd'))
# get unique data from the dataframe
# in id column
print(unique(data1$id))
# get unique data from the dataframe
# in name column
print(unique(data1$name))
# get unique data from the dataframe
# in address column
print(unique(data1$address))
输出:
