使用 Dplyr 在 R 中按函数分组
Group_by()函数属于 R 编程语言中的 dplyr 包,它对数据帧进行分组。 Group_by()函数本身不会给出任何输出。之后应该是 summarise()函数,并带有要执行的适当操作。它的工作原理类似于 SQL 中的 GROUP BY 和 Excel 中的数据透视表。
句法:
group_by(col,…)
句法:
group_by(col,..) %>% summarise(action)
使用的数据集:
样品_超市
GROUP_BY()对单个列
这是可以对列进行分组的最简单方法,只需在 group_by()函数传递要分组的列的名称,并在 summarise()函数对该分组列执行的操作。
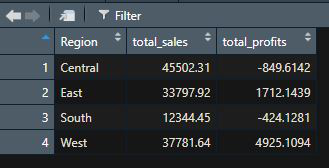
示例:按 group_by() 对单列进行分组
R
library(dplyr)
df = read.csv("Sample_Superstore.csv")
df_grp_region = df %>% group_by(Region) %>%
summarise(total_sales = sum(Sales),
total_profits = sum(Profit),
.groups = 'drop')
View(df_grp_region)R
library(dplyr)
df = read.csv("Sample_Superstore.csv")
df_grp_reg_cat = df %>% group_by(Region, Category) %>%
summarise(total_Sales = sum(Sales),
total_Profit = sum(Profit),
.groups = 'drop')
View(df_grp_reg_cat)R
library(dplyr)
df = read.csv("Sample_Superstore.csv")
df_grp_reg_cat = df %>% group_by(Region, Category) %>%
summarise(mean_Sales = mean(Sales),
mean_Profit = mean(Profit),
.groups = 'drop')
View(df_grp_reg_cat)输出:
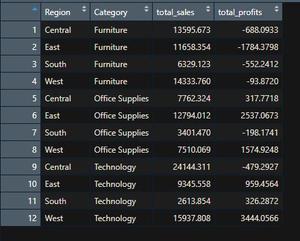
多列上的 Group_by()
Group_by()函数也可以在两列或更多列上执行,列名需要按正确的顺序排列。将根据 group_by函数的第一列名称进行分组,然后根据第二列进行分组。
示例:对多列进行分组
电阻
library(dplyr)
df = read.csv("Sample_Superstore.csv")
df_grp_reg_cat = df %>% group_by(Region, Category) %>%
summarise(total_Sales = sum(Sales),
total_Profit = sum(Profit),
.groups = 'drop')
View(df_grp_reg_cat)
输出:
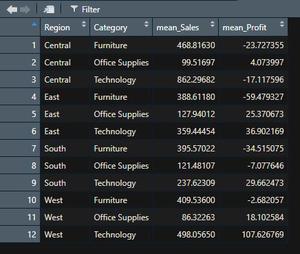
我们还可以通过替换汇总或聚合函数的总和来计算均值、计数、最小值或最大值。例如,我们将找到上面同一个 group_by 示例的平均销售额和利润。
例子:
电阻
library(dplyr)
df = read.csv("Sample_Superstore.csv")
df_grp_reg_cat = df %>% group_by(Region, Category) %>%
summarise(mean_Sales = mean(Sales),
mean_Profit = mean(Profit),
.groups = 'drop')
View(df_grp_reg_cat)
输出: