- DAA算法
- DAA-算法分析(1)
- DAA-算法分析
- 圈复杂度
- 圈复杂度(1)
- 圈复杂度
- 圈复杂度
- DAA算法需求(1)
- DAA算法需求
- 所有排序算法的时间复杂度
- DAA算法设计技术(1)
- DAA算法设计技术
- DAA主方法
- 时间复杂度和空间复杂度(1)
- 时间复杂度和空间复杂度
- 算法计算器的时间复杂度 (1)
- DAA |约翰逊算法
- DAA |约翰逊算法(1)
- DAA桶排序
- DAA桶排序(1)
- DAA-爬山算法
- DAA-爬山算法(1)
- 算法及其时间和空间复杂度 (1)
- 欧几里得算法的时间复杂度
- 欧几里得算法的时间复杂度
- 欧几里得算法的时间复杂度(1)
- 算法计算器的时间复杂度 - 无论代码示例
- DAA |流网络和流(1)
- DAA |流网络和流
📅 最后修改于: 2020-12-10 03:43:20 🧑 作者: Mango
算法的复杂性
术语“算法复杂性”用于衡量算法解决给定问题所需的步骤。它评估由算法作为输入数据大小的函数执行的操作的计数的顺序。
为了评估复杂度,始终考虑操作计数的顺序(近似值),而不是计算确切的步骤。
O(f)表示法表示算法的复杂性,也称为渐近表示法或“ Big O ”表示法。在此,f对应于其大小与输入数据相同的函数。渐进计算O(f)的复杂度决定了算法(如输入数据大小的函数)以哪种顺序消耗资源(例如CPU时间,内存等)。
复杂性可以以任何形式找到,例如常数,对数,线性,n * log(n),二次,三次,指数等。它只是常数,对数,线性等的阶数,完成特定算法所遇到的步骤。为了使其更加精确,我们通常将算法的复杂性称为“运行时间”。
算法的典型复杂性
- 恒定复杂度:施加O(1)的复杂度。为了解决给定的问题,它要执行恒定数量的步骤,例如1、5、10等。操作次数与输入数据大小无关。
- 对数复杂度:施加O(log(N))的复杂度。它执行log(N)步骤的顺序。为了对N个元素执行运算,通常将对数底为2。对于N = 1,000,000,复杂度为O(log(N))的算法将经历20步(以恒定的精度)。在这里,对数基数对操作计数顺序没有必要的影响,因此通常将其省略。
- 线性复杂度:
- 它强加了O(N)的复杂性。它包含与在N个元素上实现运算的元素总数相同的步骤数。例如,如果存在500个元素,则大约需要500步。基本上,在线性复杂度中,元素的数量线性地取决于步骤的数量。例如,N个元素的步数可以是N / 2或3 * N。
- 它还强加了O(n * log(n))的运行时间。它对N个元素执行N * log(N)的阶数,以解决给定的问题。对于给定的1000个元素,线性复杂度将执行10,000个步骤来解决给定的问题。
- 二次复杂度:施加O(n 2 )的复杂度。对于N个输入数据大小,它要对N个元素进行N 2个操作计数,才能解决给定问题。如果N = 100,它将忍受10,000步。换句话说,每当操作顺序趋于与输入数据大小呈二次关系时,就会导致二次复杂性。例如,对于N个元件,步骤被发现是在3×N 2/2左右。
- 三次复杂度:施加O(n 3 )的复杂度。对于N个输入数据大小,它将对N个元素执行N 3步的顺序以解决给定的问题。例如,如果存在100个元素,它将执行1,000,000个步骤。
- 指数复杂度:施加O(2 n ),O(N!),O(n k ),…的复杂度。对于N个元素,它将执行操作计数的顺序,该顺序取决于输入数据大小。例如,如果N = 10,则指数函数2 N将得出1024。类似地,如果N = 20,则将得出1048 576,如果N = 100,则将得出具有30个数字的数字。指数函数N!增长更快;例如,如果N = 5将得到120。同样,如果N = 10将得到3,628,800,依此类推。
由于常量对操作计数的顺序影响不大,因此最好忽略它们。因此,要考虑算法是线性且等效效率高的算法,必须对相同数量的元素分别进行N,N / 2或3 * N次运算才能解决特定问题。
如何估算算法花费的时间?
因此,要找出答案,我们将首先了解我们拥有的算法的类型。有两种算法:
- 迭代算法:在迭代方法中,函数反复运行,直到满足条件或失败为止。它涉及循环构造。
- 递归算法:在递归方法中,函数将自行调用,直到满足条件为止。它集成了分支结构。
但是,值得注意的是,以迭代方式编写的任何程序都可以编写为递归。同样,可以将递归程序转换为迭代,使这两种算法彼此等效。
但是要分析迭代程序,我们必须计算循环要执行的次数,而在递归程序中,我们使用递归方程,即,我们根据F(n)写出F(n)的函数。 / 2)。
假设程序既不是迭代的也不是递归的。在那种情况下,可以得出结论,运行时间不依赖于输入数据大小,即,无论输入大小如何,运行时间都将是恒定值。因此,对于此类程序,复杂度将为O(1) 。
对于迭代程序
请考虑以下用简单的英语编写且与任何语法都不对应的程序。
范例1:
在第一个示例中,我们有一个整数i和一个从i等于1到n的for循环。现在出现了一个问题,名字被打印了几次?
A()
{
int i;
for (i=1 to n)
printf("Edward");
}
由于i等于1到n,因此上面的程序将printEdward数次。因此,复杂度将为O(n) 。
范例2:
A()
{
int i, j:
for (i=1 to n)
for (j=1 to n)
printf("Edward");
}
在这种情况下,首先,外循环将运行n次,这样,每次内循环也将运行n次。因此,时间复杂度将为O(n 2 ) 。
范例3:
A()
{
i = 1; S = 1;
while (S<=n)
{
i++;
S = S + i;
printf("Edward");
}
}
从上面的示例可以看出,我们有两个变量; i,S,然后有S <= n,这意味着S从1开始,并且每当S值达到S大于n的点时,整个循环就会停止。
在这里,i以1的步长递增,而S将以i的值递增,即i的增量是线性的。但是,S的增量取决于i。
原来;
i = 1,S = 1
第一次迭代后;
i = 2,S = 3
第二次迭代后;
i = 3,S = 6
第3次迭代后;
i = 4,S = 10…依此类推。
由于我们不知道n的值,因此我们假设它为k。现在,如果我们注意到上述情况下S的值正在增加;对于i = 1,S = 1; i = 2,S = 3; i = 3,S = 6; i = 4,S = 10; …
因此,它不过是前n个自然数之和的一系列,即到i达到k时,S的值为k(k + 1)/ 2。
要停止循环, 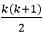 必须大于n,当我们求解此方程时,我们将得到
必须大于n,当我们求解此方程时,我们将得到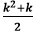 > n 。因此,可以得出结论,我们得到的O(√N),在这种情况下的复杂性。
> n 。因此,可以得出结论,我们得到的O(√N),在这种情况下的复杂性。
对于递归程序
考虑以下递归程序。
范例1:
A(n)
{
if (n>1)
return (A(n-1))
}
解;
在这里,我们将看到简单的反向替换方法来解决上述问题。
T(n)= 1 + T(n-1) …等式(1)
步骤1:将n-1替换为等式n中的n。 (1)
T(n-1)= 1 + T(n-2)…等式(2)
步骤2:将n-2替换为等式中n的位置。 (1)
T(n-2)= 1 + T(n-3)…等式(3)
步骤3:代入方程式。 (2)在等式中。 (1)
T(n)= 1 + 1+ T(n-2)= 2 + T(n-2)…等式。 (4)
步骤4:代入eqn。 (3)在等式中。 (4)
T(n)= 2 +1 + T(n-3)= 3 + T(n-3)=…… = k + T(nk)…等式。 (5)
现在,根据等式。 (1),即T(n)= 1 + T(n-1),算法将一直运行到n> 1。基本上,n从一个很大的数字开始,然后逐渐减小。因此,当T(n)= 1时,算法最终停止,这种终止条件称为锚条件,基本条件或停止条件。
因此,对于k = n-1,T(n)将变为。
步骤5:用eqn代替k = n-1。 (5)
T(n)=(n-1)+ T(n-(n-1))=(n-1)+ T(1)= n-1 + 1
因此,T(n)= n或O(n)。