使用 Pandas 简化数据摄取
数据摄取是将数据从不同来源传输到一种方法的过程,在该方法中,企业可以对其进行分析、存档或利用。此过程中涉及的通常步骤是从当前位置提取数据、转换数据,最后将其加载到某个位置以进行高效研究。 Python提供了许多这样的工具,以及用于数据摄取的框架。这些包括 Bonobo、Beautiful Soup4、Airflow、Pandas 等。在本文中,我们将了解 Pandas 库的数据摄取。
Pandas 的数据摄取:
Pandas 的数据摄取是将数据从各种来源转移到 Pandas DataFrame 结构的过程。数据源可以是各种文件格式,例如逗号分隔数据、JSON、HTML 网页表格、Excel。在本文中,我们将了解如何将数据从此类格式传输到目标,即 Pandas 数据帧对象。
方法:
将任何此类数据传输到数据帧对象的基本方法如下:
- 准备源数据。
- 数据可以存在于任何远程服务器或本地机器上。如果文件位于远程服务器上,我们需要知道文件的 URL。如果本地存在数据,则需要本地计算机上的文件路径。
- 使用 Pandas 'read_x' 方法
- Pandas 提供了“read_x”方法,用于将数据加载和转换为 Dataframe 对象。
- 根据数据格式,使用“读取”方法。
- 从 DataFrame 对象打印数据。
- 打印数据帧对象,以验证转换是否顺利。
摄取的文件格式:
在本文中,我们将把以下文件中的数据转换为数据帧结构——
- 从 CSV 文件中读取数据
- 从 Excel 文件中读取数据
- 从 JSON 文件中读取数据
- 从剪贴板读取数据
- 从网页中读取 HTML 表格中的数据
- 从 SQLite 表中读取数据
从 CSV 文件中读取数据
要加载逗号分隔文件(CSV)中的数据,我们将按照以下步骤操作:
- 准备您的示例数据集。在这里,我们有一个 CSV 文件,其中包含有关印度地铁城市的信息。它描述了城市是一级城市还是二级城市,它们的地理位置,它们所属的州,以及它是否是沿海城市。
- 使用 Pandas 方法“read_csv”
- 使用的方法 – read_csv(file_path)
- 参数 – 字符串格式,包含文件的路径及其名称,或远程服务器上存在的 URL。它读取文件数据,并将其转换为有效的二维数据帧对象。此方法可用于读取以“.csv”和“.txt”文件格式存在的数据。
文件内容如下:
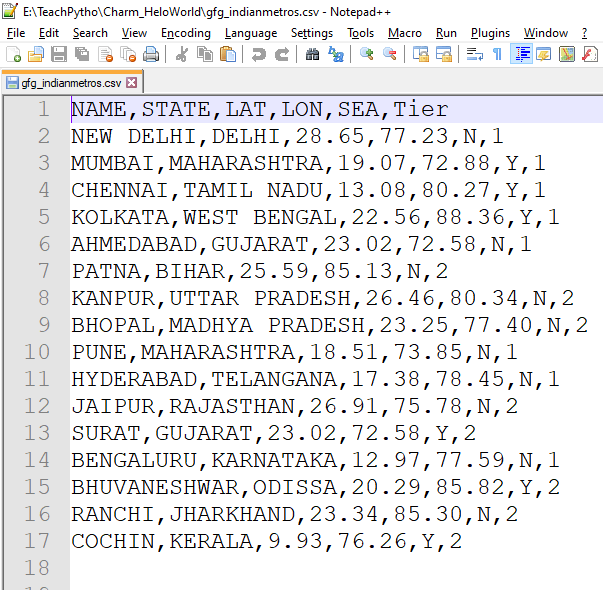
“gfg_indianmetros.csv”文件的内容
在 Pandas Data Frame 中获取数据的代码是:
Python
# Import the Pandas library
import pandas
# Load data from Comma separated file
# Use method - read_csv(filepath)
# Parameter - the path/URL of the CSV/TXT file
dfIndianMetros = pandas.read_csv("gfg_indianmetros.csv")
# print the dataframe object
print(dfIndianMetros)Python
# Import the Pandas library
import pandas
# Load data from an Excel file
# Use method - read_excel(filepath)
# Method parameter - The file location(URL/path) and name
dfBakery = pandas.read_excel("gfg_bakery.xlsx")
# print the dataframe object
print(dfBakery)Python
# Import the Pandas library
import pandas
# Load data from a JSON file
# Use method - read_json(filepath)
# Method parameter - The file location(URL/path) and name
dfCodeCountry = pandas.read_json("gfg_codecountry.json")
# print the dataframe object
print(dfCodeCountry)Python
# Import the required library
import pandas
# Copy file contents which are in proper format
# Whatever data you have copied will
# get transferred to dataframe object
# Method does not accept any parameter
pdCopiedData = pd.read_clipboard()
# Print the data frame object
print(pdCopiedData)HTML
Data Ingestion with Pandas Example
Welcome To GFG
Date
Empname
Year
Rating
Region
2020-01-01
Savio
2004
0.5
South
2020-01-02
Rahul
1998
1.34
East
2020-01-03
Tina
1988
1.00023
West
2021-01-03
Sonia
2001
2.23
North
Python
# Import the Pandas library
import pandas
# Variable containing the elements
# between tag from webpage
html_string = """
Date
Empname
Year
Rating
Region
2020-01-01
Savio
2004
0.5
South
2020-01-02
Rahul
1998
1.34
East
2020-01-03
Tina
1988
1.00023
West
2021-01-03
Sonia
2001
2.23
North
2008-01-03
Milo
2008
3.23
East
2006-01-03
Edward
2005
0.43
West
"""
# Pass the string containing html table element
df = pandas.read_html(html_string)
# Since read_html, returns a list object,
# extract first element of the list
dfHtml = df[0]
# Print the data frame object
print(dfHtml)
Python
# Import the required libraries
import sqlite3
import pandas
# Prepare a connection object
# Pass the Database name as a parameter
conn = sqlite3.connect("Novels.db")
# Use read_sql_query method
# Pass SELECT query and connection object as parameter
pdSql = pd.read_sql_query("SELECT * FROM novels", conn)
# Print the dataframe object
print(pdSql)
# Close the connection object
conn.close()
输出:
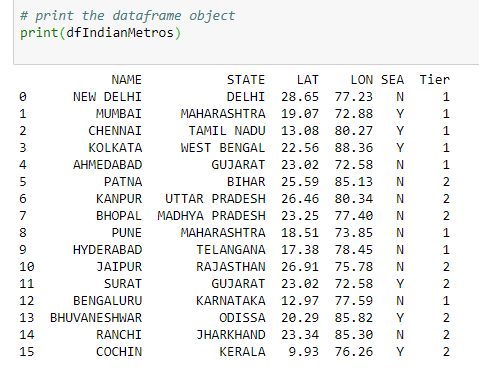
数据框对象中的 CSV 数据
从 Excel 文件中读取数据
要加载 Excel 文件(.xlsx、.xls)中存在的数据,我们将按照以下步骤操作-
- 准备您的示例数据集。在这里,我们有一个 Excel 文件,其中包含有关 Bakery 及其分支机构的信息。它描述了员工人数,面包店分店的地址。
- 使用 Pandas 方法 'read_excel' 。
- 使用的方法——read_excel(file_path)
- 参数 – 该方法接受文件路径及其名称,以字符串格式作为参数。该文件可以在远程服务器上,也可以在本地机器上。它读取文件数据,并将其转换为有效的二维数据框对象。此方法可用于读取以“.xlsx”和“.xls”文件格式存在的数据。
文件内容如下:
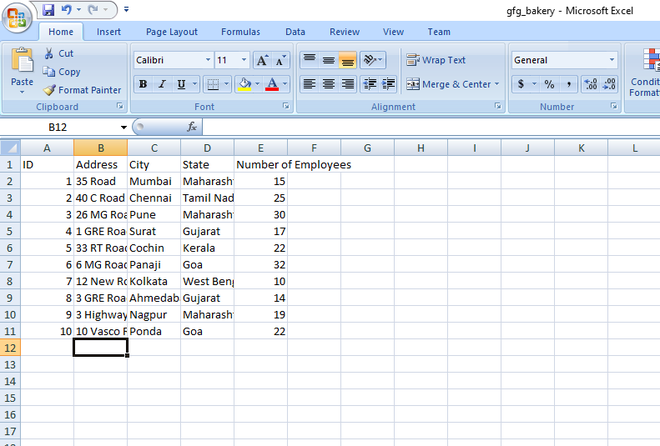
“gfg_bakery.xlsx”文件的内容
在 Pandas DataFrame 中获取数据的代码是:
Python
# Import the Pandas library
import pandas
# Load data from an Excel file
# Use method - read_excel(filepath)
# Method parameter - The file location(URL/path) and name
dfBakery = pandas.read_excel("gfg_bakery.xlsx")
# print the dataframe object
print(dfBakery)
输出:
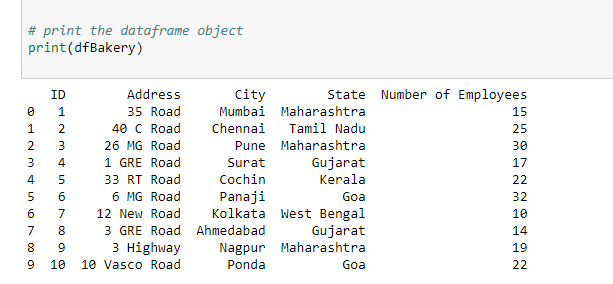
数据框对象中的 Excel 数据
从JSON 文件中读取数据
要加载 JavaScript 对象表示法文件 (.json) 中存在的数据,我们将按照以下步骤操作:
- 准备您的示例数据集。在这里,我们有一个 JSON 文件,其中包含有关国家及其拨号代码的信息。
- 使用 Pandas 方法 'read_json' 。
- 使用的方法 – read_json(file_path)
- 参数 - 此方法接受文件的路径及其名称(字符串格式)作为参数。它读取文件数据,并将其转换为有效的二维数据框对象。
文件内容如下:
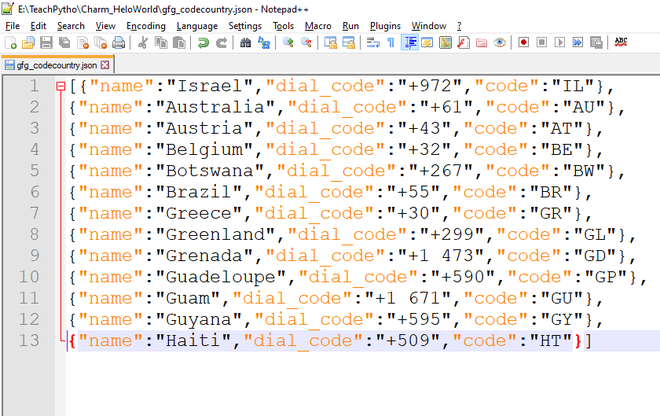
“gfg_codecountry.json”文件的内容
在 Pandas DataFrame 中获取数据的代码是:
Python
# Import the Pandas library
import pandas
# Load data from a JSON file
# Use method - read_json(filepath)
# Method parameter - The file location(URL/path) and name
dfCodeCountry = pandas.read_json("gfg_codecountry.json")
# print the dataframe object
print(dfCodeCountry)
输出:
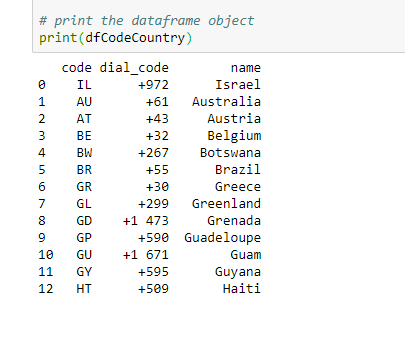
数据框对象中的 JSON 数据
从剪贴板读取数据
我们还可以将剪贴板中存在的数据传输到数据帧对象。剪贴板是随机存取存储器 (RAM) 的一部分,其中存在复制的数据。每当我们使用“复制”命令复制任何文件、文本、图像或任何类型的数据时,它都会存储在剪贴板中。要转换此处显示的数据,请按照以下步骤操作 –
- 选择文件的所有内容。该文件应为 CSV 文件。它也可以是一个“.txt”文件,包含逗号分隔的值,如示例中所示。请注意,如果文件内容的格式不合适,那么在运行时可能会出现解析器错误。
- 对,单击并说复制。现在,这些数据被传输到计算机剪贴板。
- 使用 Pandas 方法 'read_clipboard' 。
- 使用的方法 – read_clipboard
- 参数 - 该方法,不接受任何参数。它读取剪贴板中最新复制的数据,并将其转换为有效的二维数据帧对象。
选择的文件内容如下:
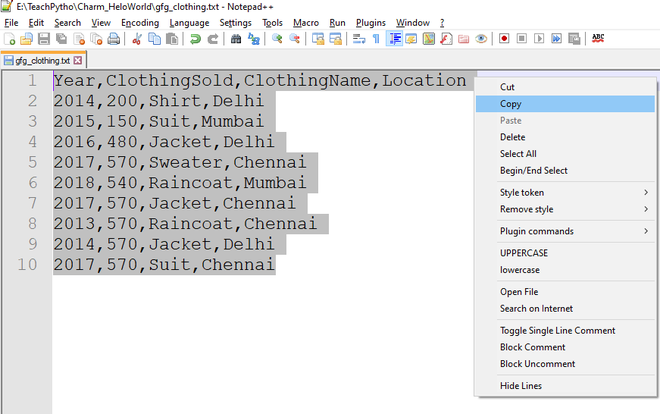
“gfg_clothing.txt”文件的内容
在 Pandas DataFrame 中获取数据的代码是:
Python
# Import the required library
import pandas
# Copy file contents which are in proper format
# Whatever data you have copied will
# get transferred to dataframe object
# Method does not accept any parameter
pdCopiedData = pd.read_clipboard()
# Print the data frame object
print(pdCopiedData)
输出:
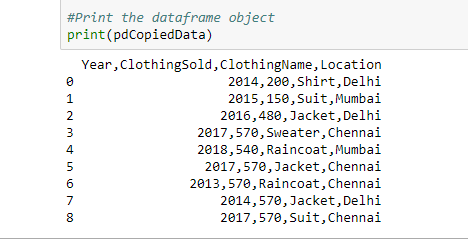
剪贴板数据,在数据帧对象中
从 HTML 文件中读取数据
网页通常由 HTML 元素组成。在浏览器上,根据数据显示的目的,有不同的 HTML 标签,例如
、、<table>、<div>。我们可以将 HTML 网页中 <table> 元素之间的内容传输到 Pandas 数据框对象。请按照以下步骤操作 –</p><ul><li>选择 <table> 中开始和结束标记之间的所有元素。将其分配给Python变量。</li><li>使用 Pandas 方法 'read_html' 。<ul><li>使用的方法 – read_html( <table> 标签内的字符串)</li><li>参数 – 该方法接受字符串变量,包含 <table> 标记之间存在的元素。它读取元素,遍历表、<tr> 和 <td> 标签,并将其转换为列表对象。列表对象的第一个元素是所需的数据框对象。</li></ul></li></ul><p>使用的HTML网页如下:</p><div class="noIdeBtnDiv"><div class="responsive-tabs"><h2 class="tabtitle"> HTML </h2><div class="tabcontent"><div class="hcb_wrap"><pre class="prism undefined-numbers lang-python" data-lang="Python"><code class="replace"><!DOCTYPE html>
<html>
<head>
<title>Data Ingestion with Pandas Example
Welcome To GFG
Date
Empname
Year
Rating
Region
2020-01-01
Savio
2004
0.5
South
2020-01-02
Rahul
1998
1.34
East
2020-01-03
Tina
1988
1.00023
West
2021-01-03
Sonia
2001
2.23
North