- 人工神经网络教程
- 人工神经网络教程(1)
- TensorFlow中的人工神经网络
- TensorFlow 中的人工神经网络(1)
- TensorFlow中的人工神经网络(1)
- TensorFlow 中的人工神经网络
- 人工神经网络-构建块
- 人工神经网络-构建块(1)
- 讨论人工神经网络
- 讨论人工神经网络(1)
- 人工神经网络术语
- 人工神经网络简介|套装1
- 人工神经网络简介|套装2(1)
- 人工神经网络简介|套装2
- 人工神经网络简介|套装1(1)
- 人工神经网络的实现模型(1)
- 人工神经网络的实现模型
- 人工神经网络-有用的资源
- 人工神经网络-有用的资源(1)
- 人工神经网络-遗传算法(1)
- 人工神经网络-遗传算法
- 人工神经网络及其应用(1)
- 人工神经网络及其应用
- 机器学习-人工神经网络
- 机器学习-人工神经网络(1)
- 人工神经网络-基本概念
- 人工神经网络-基本概念(1)
- 2位二进制输入或逻辑门的人工神经网络实现
- 2位二进制输入与逻辑门的人工神经网络实现
📅 最后修改于: 2020-12-13 14:23:49 🧑 作者: Mango
人工神经网络,或者简称为神经网络,并不是一个新想法。它已经存在了大约80年。
直到2011年,深度神经网络因使用新技术,巨大的数据集可用性和强大的计算机而变得流行。
神经网络模仿具有树突,核,轴突和末端轴突的神经元。
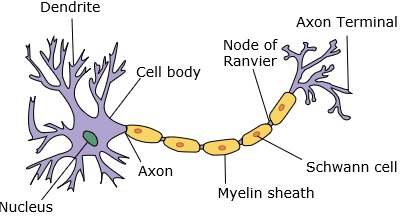
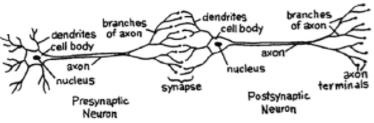
对于一个网络,我们需要两个神经元。这些神经元通过突触在一个的树突和另一个的终轴突之间传递信息。
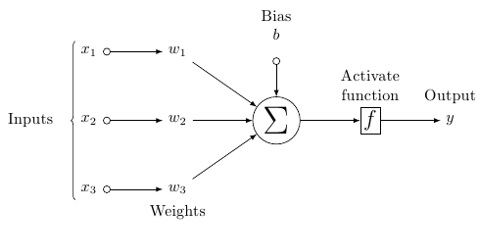
人工神经元的可能模型看起来像这样-
神经网络如下图所示-
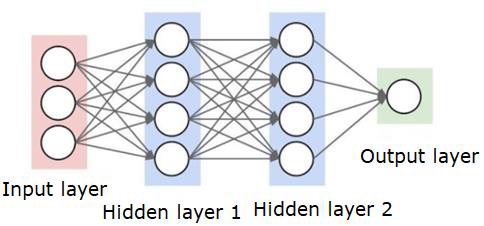
圆圈是神经元或节点,它们在数据上具有功能,连接它们的线/边是传递的权重/信息。
每列是一个层。数据的第一层是输入层。然后,输入层和输出层之间的所有层都是隐藏层。
如果您有一个或几个隐藏层,那么您就拥有一个浅层的神经网络。如果您有许多隐藏层,那么您将拥有一个深层的神经网络。
在此模型中,您具有输入数据,对其进行加权,然后将其通过神经元中的函数(称为阈值函数或激活函数)传递。
基本上,它是将它与某个特定值进行比较之后所有值的总和。如果您发射信号,则结果为(1),否则没有结果,则为(0)。然后将其加权并传递到下一个神经元,并运行相同类型的函数。
我们可以将S型(s形)函数作为激活函数。
至于权重,它们只是随机开始的,并且对于节点/神经元的每个输入都是唯一的。
在典型的“前馈”(神经网络的最基本类型)中,您的信息将直接通过创建的网络传递,然后将输出与希望使用示例数据获得的输出进行比较。
在这里,您需要调整权重以帮助您获得与所需输出匹配的输出。
直接通过神经网络发送数据的行为称为前馈神经网络。
我们的数据从输入开始依次到各层,再到输出。
当我们倒退并开始调整权重以最小化损失/成本时,这称为反向传播。
这是一个优化问题。使用神经网络,在实际中,我们必须处理成千上万个变量,甚至数百万个甚至更多。
第一个解决方案是使用随机梯度下降作为优化方法。现在,有一些选项,例如AdaGrad,Adam Optimizer等。无论哪种方式,这都是一个庞大的计算操作。这就是为什么神经网络大部分被搁置了半个多世纪。直到最近,我们甚至在机器中都拥有强大的功能和体系结构,甚至可以考虑执行这些操作,并选择合适大小的数据集进行匹配。
对于简单的分类任务,神经网络在性能上与其他简单算法(例如K最近邻居)相对接近。当我们拥有更大的数据和更复杂的问题时,神经网络才真正发挥作用,这两者都胜过其他机器学习模型。