ANN学习对训练数据中的错误具有鲁棒性,并且已成功应用于学习包含诸如解释视觉场景,语音识别和学习机器人控制策略等问题的实值,离散值和矢量值函数。人工神经网络(ANN)的研究部分受到以下观察的启发:生物学习系统是由大脑中相互连接的神经元的非常复杂的网络构成的。人脑包含大约10 ^ 11-10 ^ 12个神经元的密集互连网络,每个神经元平均连接到10 ^ 4-10 ^ 5个其他神经元。因此,平均每个人的大脑大约需要10 ^ -1才能做出令人惊讶的复杂决定。人工神经网络系统的动机是基于分布式表示来捕获这种高度并行的计算。通常,人工神经网络是由一组紧密互连的简单单元构建而成的,其中每个单元采用大量实值输入,并产生单个实值输出。
但是,人工神经网络受生物神经系统的动机较少,生物神经系统有许多复杂性,无法通过人工神经网络来建模。其中一些如图所示。
生物神经元与人工神经元之间的差异
| Biological Neurons | Artificial Neurons |
|---|---|
| Major components: Axions, Dendrites, Synapse | Major Components: Nodes, Inputs, Outputs, Weights, Bias |
| Information from other neurons, in the form of electrical impulses, enters the dendrites at connection points called synapses. The information flows from the dendrites to the cell where it is processed. The output signal, a train of impulses, is then sent down the axon to the synapse of other neurons. | The arrangements and connections of the neurons made up the network and have three layers. The first layer is called the input layer and is the only layer exposed to external signals. The input layer transmits signals to the neurons in the next layer, which is called a hidden layer. The hidden layer extracts relevant features or patterns from the received signals. Those features or patterns that are considered important are then directed to the output layer, which is the final layer of the network. |
| A synapse is able to increase or decrease the strength of the connection. This is where information is stored. | The artificial signals can be changed by weights in a manner similar to the physical changes that occur in the synapses. |
| Approx 1011 neurons. | 102– 104 neurons with current technology |
人脑与计算机之间在信息处理方式方面的差异。
| Human Brain(Biological Neuron Network) | Computers(Artificial Neuron Network) |
|---|---|
| The human brain works asynchronously | Computers(ANN) work synchronously. |
| Biological Neurons compute slowly (several ms per computation) | Artificial Neurons compute fast (<1 nanosecond per computation) |
| The brain represents information in a distributed way because neurons are unreliable and could die any time. | In computer programs every bit has to function as intended otherwise these programs would crash. |
| Our brain changes their connectivity over time to represents new information and requirements imposed on us. | The connectivity between the electronic components in a computer never change unless we replace its components. |
| Biological neural networks have complicated topologies. | ANNs are often in a tree structure. |
| Researchers are still to find out how the brain actually learns. | ANNs use Gradient Descent for learning. |
使用人工神经网络的优势:
- ANN中的问题可能具有由许多属性-值对表示的实例。
- 用于具有目标函数输出的问题的ANN可以是离散值,实值或几个实值或离散值属性的向量。
- 神经网络学习方法对于训练数据中的噪声非常鲁棒。培训示例可能包含错误,这些错误不会影响最终输出。
- 它通常用于可能需要快速评估学习目标函数的场合。
- 人工神经网络可以承受较长的训练时间,具体取决于诸如网络中权数的数量,所考虑的训练示例的数量以及各种学习算法参数的设置等因素。
神经元的McCulloch-Pitts模型:
Warren McCulloch和Walter Pitts在1943年引入了人工神经元的早期模型。McCulloch-Pitts神经模型也称为线性阈值门。它是一组输入I1,I2,…,Im和一个输出y的神经元。线性阈值门仅将输入集分为两个不同的类别。因此,输出y是二进制的。这样的函数可以在数学使用这些方程来描述:

W1,W2,W3….Wn是在(0,1)或(-1,1)范围内归一化的权重值,并且与每个输入线相关联,Sum是加权总和,并且是阈值常数。函数f是阈值处的线性阶跃函数
单层神经网络(感知器)
输入是多维的(即输入可以是向量):
输入x =(I1,I2,..,In)
输入节点(或单元)(通常完全连接)到下一层中的一个节点(或多个节点)。下一层中的节点对其所有输入进行加权求和: ![]()
规则:
输出节点具有“阈值” t。
规则:如果求和输入? t,则“触发”(输出y = 1)。否则(总输入
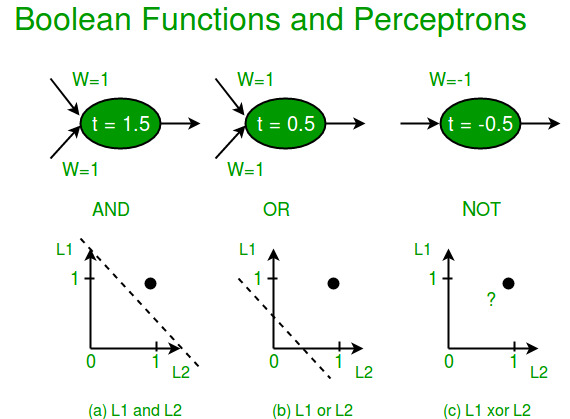
感知器的局限性:
(i)由于硬极限传递函数,感知器的输出值只能采用两个值(0或1)之一。
(ii)感知器只能对向量的线性可分离集进行分类。如果可以画一条直线或一个平面将输入向量分成正确的类别,则输入向量是线性可分离的。如果向量不是线性可分离的,学习将永远不会到达所有向量都正确分类的地步
布尔函数XOR不可线性分离(其正例和负例不能由线或超平面分隔)。因此,单层感知器永远无法计算XOR函数。这是一个很大的缺点,它曾经导致神经网络领域的停滞。但这已通过多层解决。
多层神经网络
多层感知器(MLP)或多层神经网络包含一个或多个隐藏层(一个输入层和一个输出层除外)。虽然单层感知器只能学习线性函数,但是多层感知器也可以学习非线性函数。
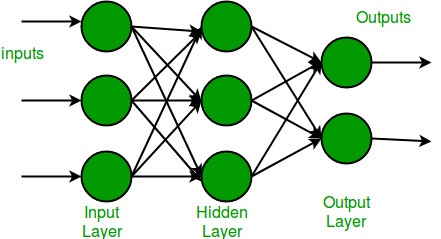
这个神经元将x1,x2,….,x3(和+1偏差项)作为输入,并输出f(求和输入+ bias),其中f(。)称为激活函数。 Bias的主要函数是为每个节点提供一个可训练的常数值(除了该节点接收的常规输入外)。每个激活函数(或非线性函数)取一个数字并对其执行特定的固定数学运算。在实践中可能会遇到几种激活功能:
Sigmoid:采用实值输入并将其压缩为0到1之间的范围。 ![]()
tanh:获取实值输入并将其压缩为[-1,1]范围。 ![]()
ReLu: ReLu代表整流线性单位。它采用实值输入并将其阈值设置为0(将负值替换为0)。 ![]()
参考:
- Christos Stergiou和Dimitrios Siganos的神经网络
- ujjwalkarn.me
- 机器学习,汤姆·米切尔,麦格劳·希尔,1997年。